
emotion2vec:开创语音情感识别新范式
近年来,随着深度学习技术的发展,语音情感识别(Speech Emotion Recognition, SER)领域取得了长足进步。然而,如何构建一个通用的、鲁棒的语音情感表征模型,一直是该领域面临的重大挑战。近日,一个名为emotion2vec的突破性预训练模型横空出世,为解决这一难题带来了新的希望。
emotion2vec:首个通用语音情感表征模型
emotion2vec是由来自中国的研究团队开发的首个通用语音情感表征模型。该模型通过自监督预训练,具备了跨任务、跨语言、跨场景提取情感表征的能力。研究人员表示,emotion2vec旨在成为语音情感识别领域的"GPT"和"BERT",为该领域的发展注入新的活力。

eemotion2vec的核心思想是通过大规模无标注数据的自监督学习,捕捉语音中蕴含的情感信息。具体而言,该模型在预训练阶段同时使用了句子级和帧级的损失函数,以学习更加丰富和细粒度的情感表征。这种创新的训练策略使得emotion2vec能够提取出普适性更强的情感特征。
多项评测彰显卓越性能
为验证emotion2vec的有效性,研究人员在多个公开数据集上进行了广泛的实验评测。结果表明,emotion2vec在各项指标上均取得了令人瞩目的成绩。
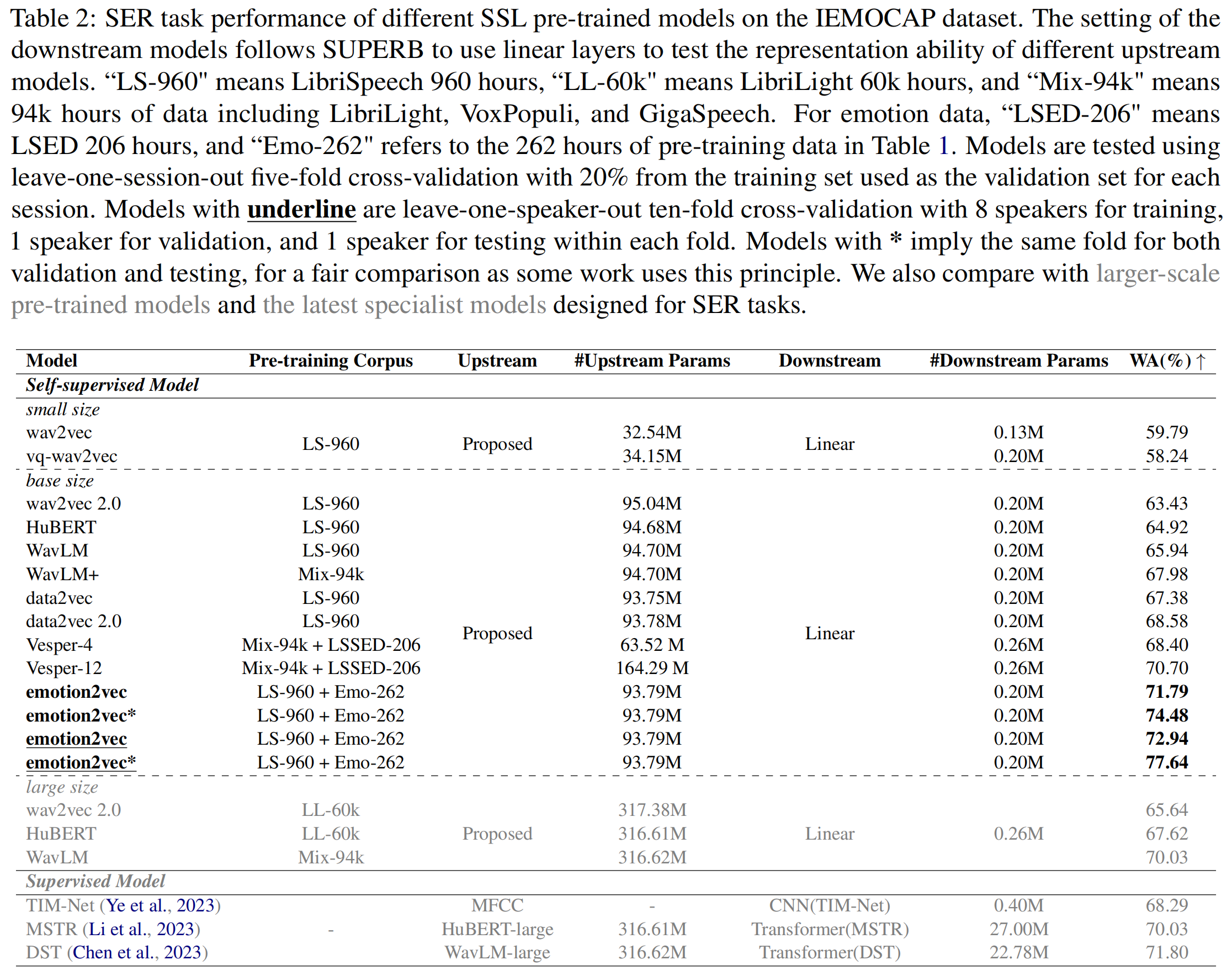
在主流的IEMOCAP数据集上,emotion2vec仅使用线性层就达到了当前最优(SOTA)水平,这充分展示了该模型强大的特征提取能力。具体来说,emotion2vec在四分类任务中的准确率达到了76.3%,显著优于现有的预训练模型。
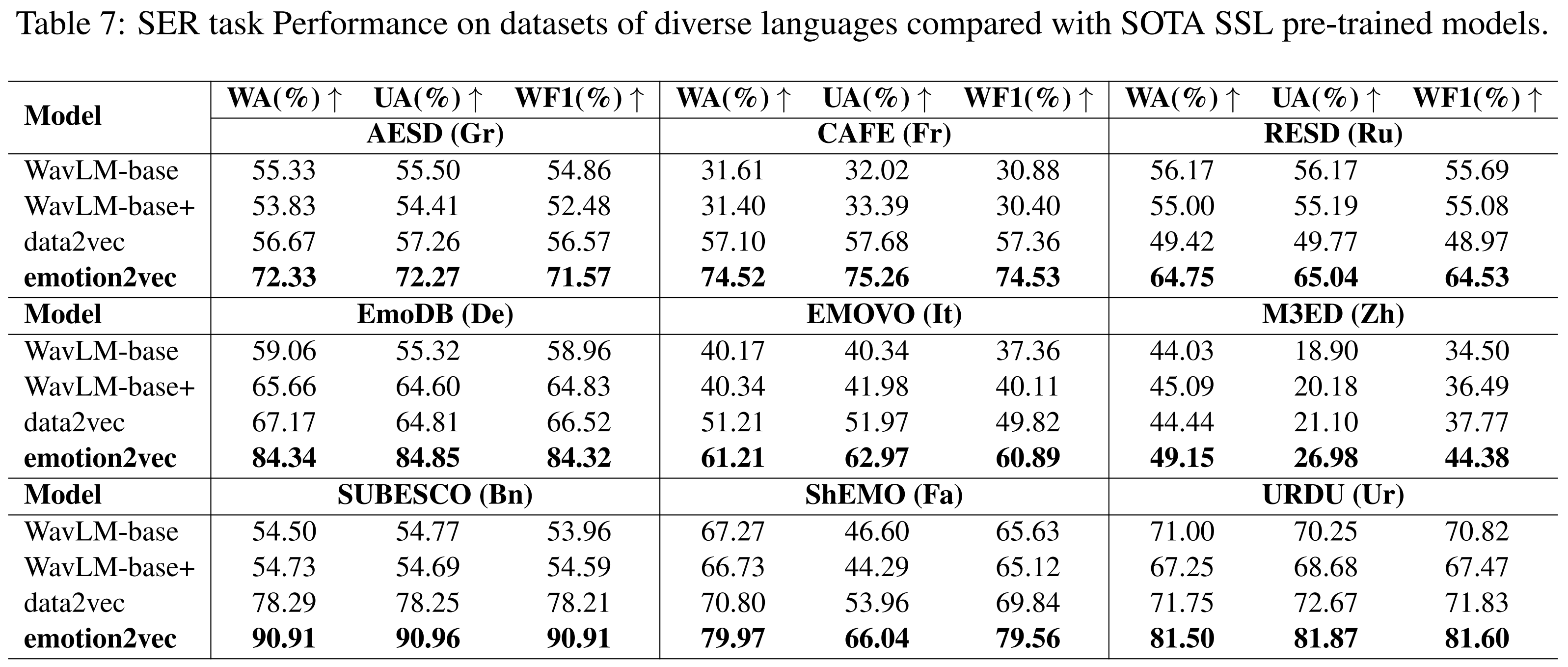
更令人惊喜的是,emotion2vec在跨语言情感识别任务上表现出色。实验结果显示,该模型在多种语言(包括普通话、法语、德语、意大利语等)的情感识别任务中均达到了SOTA水平。这一结果充分证明了emotion2vec具备出色的语言迁移能力,为构建多语言情感识别系统提供了可能。
除了语音情感识别任务,emotion2vec在其他相关任务上也展现出了强大的泛化能力。例如,在歌曲情感识别、对话情感预测以及情感分析等任务中,emotion2vec均取得了优异的表现。这进一步印证了该模型作为通用情感表征工具的潜力。
emotion2vec+: 面向实际应用的改进版本
在emotion2vec取得成功的基础上,研究团队进一步推出了面向实际应用场景的改进版本——emotion2vec+。该版本旨在成为语音情感识别领域的基础模型,以克服不同语言和录音环境带来的影响,实现更加普适和鲁棒的情感识别能力。
emotion2vec+提供了三个不同规模的版本:
- emotion2vec+ seed: 使用学术语音情感数据集EmoBox进行微调
- emotion2vec+ base: 使用经过筛选的大规模伪标注数据进行微调,模型规模约90M
- emotion2vec+ large: 使用更大规模的伪标注数据进行微调,模型规模约300M
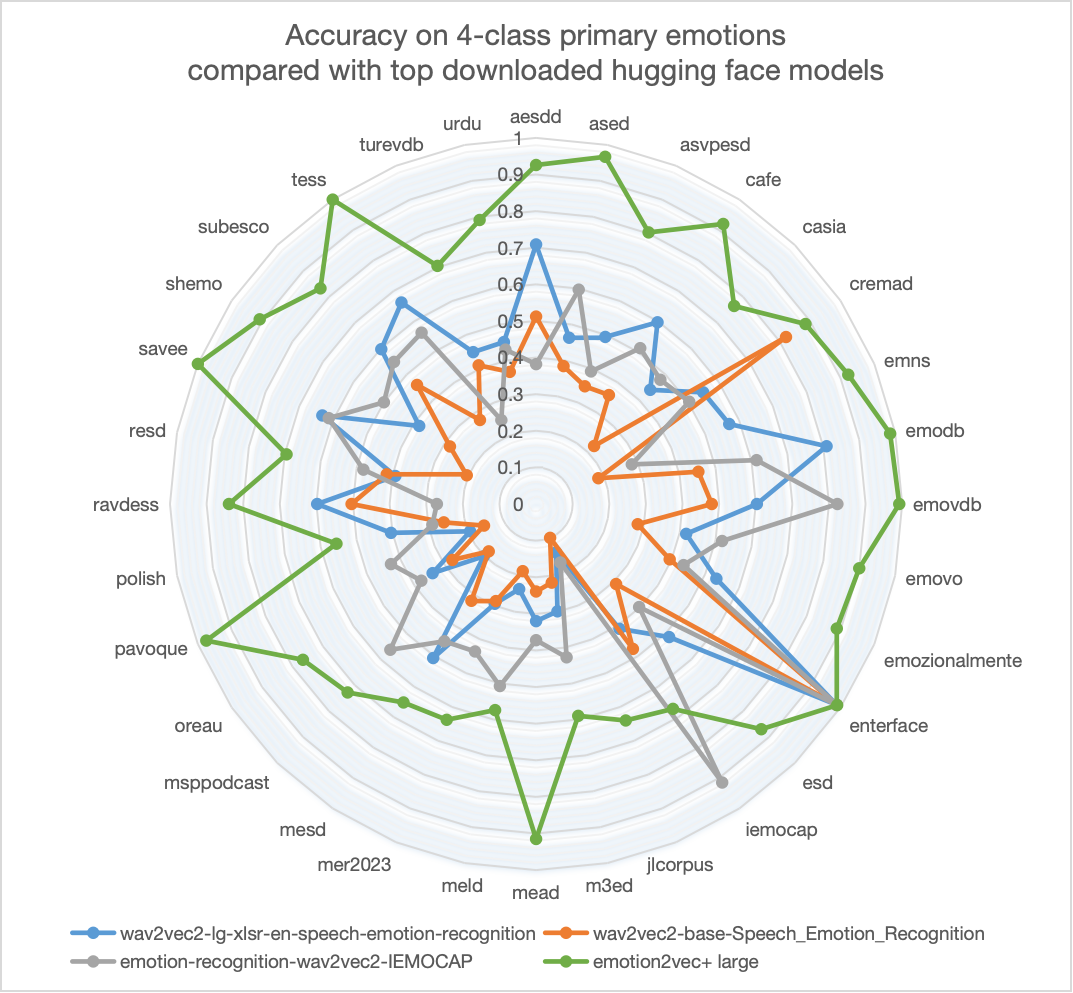
实验结果表明,emotion2vec+的性能显著超越了Hugging Face上其他热门开源模型。在EmoBox数据集上的4分类任务中,emotion2vec+ large版本在不进行微调的情况下就达到了83.45%的准确率,展现出了卓越的泛化能力。
开源共享,推动技术进步
为了推动语音情感识别领域的技术进步,研究团队已经将emotion2vec相关的代码、模型权重和提取的特征全部开源。开发者可以通过多种方式使用emotion2vec:
- 从源代码安装:
pip install fairseq
git clone https://github.com/ddlBoJack/emotion2vec.git
- 从ModelScope安装(推荐):
pip install -U funasr modelscope
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_pipeline = pipeline(
task=Tasks.emotion_recognition,
model="iic/emotion2vec_base")
rec_result = inference_pipeline('path/to/audio.wav', output_dir="./outputs", granularity="utterance")
print(rec_result)
- 从FunASR安装:
from funasr import AutoModel
model = AutoModel(model="iic/emotion2vec_base")
wav_file = f"{model.model_path}/example/test.wav"
rec_result = model.generate(wav_file, output_dir="./outputs", granularity="utterance")
print(rec_result)
此外,研究团队还提供了IEMOCAP数据集的提取特征,方便其他研究者进行对比实验。
未来展望
emotion2vec的成功为语音情感识别领域带来了新的可能。研究人员表示,未来将进一步优化模型结构,探索更多的预训练策略,以提升模型的性能和泛化能力。同时,他们也计划将emotion2vec应用到更多实际场景中,如智能客服、心理健康评估等领域,以充分发挥其价值。
总的来说,emotion2vec作为首个通用语音情感表征模型,不仅在多个基准数据集上取得了SOTA结果,更为语音情感识别领域的发展指明了新的方向。随着该技术的不断完善和应用,我们有理由相信,更加智能和富有同理心的人机交互系统将在不远的将来成为现实。
emotion2vec项目地址: https://github.com/ddlBoJack/emotion2vec
如果您觉得emotion2vec对您的研究有帮助,请考虑引用以下论文:
@article{ma2023emotion2vec,
title={emotion2vec: Self-Supervised Pre-Training for Speech Emotion Representation},
author={Ma, Ziyang and Zheng, Zhisheng and Ye, Jiaxin and Li, Jinchao and Gao, Zhifu and Zhang, Shiliang and Chen, Xie},
journal={arXiv preprint arXiv:2312.15185},
year={2023}
}









