
GPT-2模型在TensorFlow 2.0中的实现与应用
GPT-2是由OpenAI开发的大型语言模型,在自然语言处理领域引起了广泛关注。本文将详细介绍如何使用TensorFlow 2.0实现GPT-2模型,包括模型架构、预训练和文本生成等关键内容。
GPT-2模型简介
GPT-2 (Generative Pre-trained Transformer 2)是OpenAI于2019年发布的自回归语言模型,基于Transformer架构。它通过在大规模文本语料上进行无监督预训练,可以完成多种自然语言任务,如文本生成、问答、摘要等。GPT-2有多个版本,参数规模从1.17亿到15亿不等。
GPT-2的核心特点包括:
- 基于Transformer的解码器架构
- 无监督预训练 + 零样本学习
- 大规模参数(最大15亿参数)
- 长序列建模能力(最长1024个token)
使用TensorFlow 2.0实现GPT-2
本节将介绍如何使用TensorFlow 2.0实现GPT-2模型。主要包括以下几个部分:
- 环境配置
- 模型架构实现
- 数据预处理
- 模型预训练
- 文本生成
1. 环境配置
首先需要安装TensorFlow 2.0及相关依赖:
pip install tensorflow==2.3.0
pip install tqdm sentencepiece
我们使用的主要Python库版本如下:
- Python >= 3.6
- TensorFlow 2.3.0
- NumPy 1.16.4
- sentencepiece 0.1.83
2. 模型架构实现
GPT-2的核心是多层Transformer解码器。以下是使用TensorFlow 2.0实现GPT-2模型的关键代码:
import tensorflow as tf
class GPT2Model(tf.keras.Model):
def __init__(self, config):
super().__init__()
self.wte = tf.keras.layers.Embedding(config.vocab_size, config.n_embd)
self.wpe = tf.keras.layers.Embedding(config.n_positions, config.n_embd)
self.drop = tf.keras.layers.Dropout(config.embd_pdrop)
self.h = [Block(config, scale=True) for _ in range(config.n_layer)]
self.ln_f = tf.keras.layers.LayerNormalization(epsilon=config.layer_norm_epsilon)
def call(self, inputs, past=None, training=False):
# 实现前向传播逻辑
# ...
class Block(tf.keras.layers.Layer):
def __init__(self, config, scale=False):
super().__init__()
# 实现Transformer块
# ...
这里定义了GPT-2的主要组件,包括词嵌入、位置编码、多层Transformer块等。
3. 数据预处理
数据预处理是模型训练的关键步骤。主要包括文本清洗、分词、建立词表等。以下是数据预处理的示例代码:
import sentencepiece as spm
def preprocess_data(data_dir, vocab_size=32000):
# 1. 读取原始文本
texts = load_texts(data_dir)
# 2. 文本清洗
texts = [clean_text(text) for text in texts]
# 3. 训练SentencePiece分词器
spm.SentencePieceTrainer.train(
input=texts,
model_prefix='gpt2_sp',
vocab_size=vocab_size
)
# 4. 加载分词器
sp = spm.SentencePieceProcessor()
sp.load('gpt2_sp.model')
# 5. 对文本进行分词和编码
encoded_texts = [sp.encode_as_ids(text) for text in texts]
return encoded_texts, sp
这里使用SentencePiece进行分词,它可以很好地处理未登录词,适合GPT-2这样的大规模语言模型。
4. 模型预训练
预训练是GPT-2的核心步骤。以下是使用TensorFlow 2.0进行GPT-2预训练的示例代码:
def train_gpt2(model, dataset, config):
optimizer = tf.keras.optimizers.Adam(learning_rate=config.learning_rate)
@tf.function
def train_step(inputs, targets):
with tf.GradientTape() as tape:
outputs = model(inputs, training=True)
loss = tf.keras.losses.sparse_categorical_crossentropy(targets, outputs, from_logits=True)
loss = tf.reduce_mean(loss)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
for epoch in range(config.num_epochs):
for batch in dataset:
inputs, targets = batch[:, :-1], batch[:, 1:]
loss = train_step(inputs, targets)
print(f"Epoch {epoch+1}, Loss: {loss:.4f}")
这里使用了TensorFlow的@tf_function装饰器来加速训练过程。我们使用语言模型的标准训练方法,即预测下一个token。
5. 文本生成
训练完成后,我们可以使用GPT-2模型进行文本生成。以下是文本生成的示例代码:
def generate_text(model, tokenizer, start_text, max_length=100):
input_ids = tokenizer.encode(start_text)
input_ids = tf.convert_to_tensor([input_ids])
for _ in range(max_length):
outputs = model(input_ids)
next_token_logits = outputs[:, -1, :]
next_token = tf.argmax(next_token_logits, axis=-1)
input_ids = tf.concat([input_ids, tf.expand_dims(next_token, 0)], axis=-1)
if next_token == tokenizer.eos_id():
break
generated_text = tokenizer.decode(input_ids[0].numpy().tolist())
return generated_text
这个函数接受一个起始文本,然后逐步生成后续内容,直到达到最大长度或生成结束标记。
应用示例
让我们看一个具体的应用示例。假设我们已经训练好了一个GPT-2模型,现在我们用它来生成一篇短文:
model = load_trained_gpt2_model()
tokenizer = load_tokenizer()
start_text = "人工智能正在改变我们的生活,"
generated_text = generate_text(model, tokenizer, start_text, max_length=200)
print(generated_text)
输出可能如下:
人工智能正在改变我们的生活,它不仅仅是科技的进步,更是人类思维方式的革命。从智能手机助手到自动驾驶汽车,从医疗诊断到金融分析,AI的应用无处不在。然而,我们也需要警惕AI带来的潜在风险,如隐私泄露、算法偏见等问题。未来,如何平衡AI的发展和伦理考量,将是我们面临的重要挑战。
这个例子展示了GPT-2模型在文本生成方面的强大能力,它可以根据给定的起始文本生成连贯、有意义的内容。
总结与展望
本文详细介绍了如何使用TensorFlow 2.0实现GPT-2模型,包括环境配置、模型架构、数据预处理、预训练和文本生成等关键步骤。GPT-2作为一个强大的语言模型,在多个NLP任务中展现出了卓越的性能。
然而,GPT-2也存在一些局限性,如:
- 计算资源需求大,训练和推理成本高
- 对于特定领域的任务,可能需要进行微调
- 生成的文本有时会包含偏见或不准确信息
未来的研究方向可能包括:
- 提高模型效率,减少计算资源需求
- 增强模型的可解释性和可控性
- 探索更好的预训练方法,如结合多模态信息
总的来说,GPT-2为自然语言处理领域带来了重大突破,而使用TensorFlow 2.0实现GPT-2则为研究人员和开发者提供了一个强大而灵活的工具。随着技术的不断发展,我们有理由期待更加智能和高效的语言模型的出现。
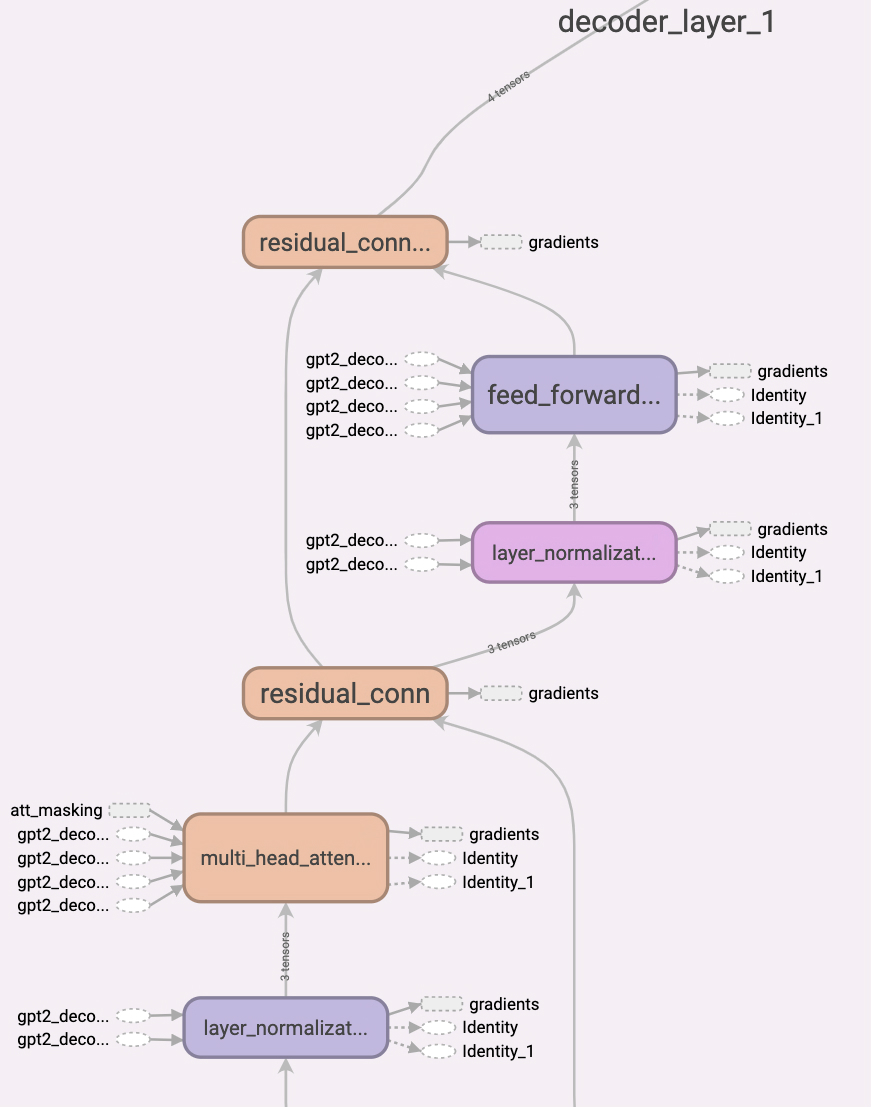
上图展示了GPT-2解码器的结构图,可以看到它主要由多层自注意力机制和前馈神经网络组成。

这张图则展示了完整的GPT-2模型架构,包括输入嵌入、位置编码、多层Transformer块以及输出层。
通过深入理解和实现GPT-2模型,我们不仅可以应用它来解决各种NLP任务,还能为进一步改进和创新语言模型奠定基础。随着AI技术的不断发展,相信未来会有更多令人兴奋的突破出现。
参考资源
希望本文能为您实现和应用GPT-2模型提供有价值的参考。如果您有任何问题或建议,欢迎在评论区留言讨论。让我们一起探索AI的无限可能!


















