
Hey-Jetson: 边缘计算平台上的深度学习语音识别系统
Hey-Jetson 是一个运行在 Nvidia Jetson 嵌入式计算平台上的自动语音识别(ASR)系统。该项目由 Brice Walker 开发,旨在探索如何在边缘计算设备上部署复杂的深度学习语音识别模型。Hey-Jetson 不仅展示了先进的语音识别技术,还为实时语音交互应用提供了一个可扩展的解决方案。
项目背景与目标
Hey-Jetson 项目的灵感来源于开发者 Brice Walker 在心理健康领域的工作经历。他希望构建一个平台,能够对治疗师的干预效果进行实时推理和反馈。尽管最初的目标是为治疗师提供实时反馈工具,但该项目的应用范围远不止于此。在移动设备、机器人技术等领域,本地化的语音识别都有广阔的应用前景。
与传统的基于云计算的深度学习方案不同,Hey-Jetson 专注于边缘计算场景。这意味着语音识别可以在本地设备上完成,无需依赖网络连接,从而提高了响应速度,并better保护了用户隐私。
项目的主要目标是构建一个字符级的ASR系统,使用TensorFlow实现的循环神经网络,能够在Nvidia Pascal/Volta GPU上运行推理,并将词错误率(WER)控制在20%以下。
核心技术与模型架构
Hey-Jetson 采用了多项先进的深度学习技术:
-
模型架构: 基于循环神经网络(RNN)的编码器-解码器模型。包含3层膨胀卷积神经元、7层双向GRU单元、1个注意力层和2层时间分布式全连接层。
-
卷积神经网络(CNN): 使用256个神经元的CNN层进行早期模式检测和特征提取。
-
膨胀卷积: 通过在CNN的卷积核中引入间隔,扩大了感受野,使模型能够捕捉更全局的上下文信息。
-
批归一化: 对每一层的激活值进行归一化处理,加快训练速度并防止过拟合。
-
LSTM/GRU单元: 长短期记忆(LSTM)和门控循环单元(GRU)能够有效处理长序列数据,捕捉语音中的长期依赖关系。
-
双向层: 同时从前向和后向处理序列,使模型能够利用未来的上下文信息。
-
循环dropout: 随机丢弃部分神经元,防止过拟合。
-
注意力机制: 允许模型在生成输出时"关注"输入序列的不同部分,提高了模型的表现。
-
时间分布式全连接层: 对输入序列的每个时间步应用全连接层,增强了模型的表达能力。
-
CTC损失函数: 使用连接时序分类(CTC)作为损失函数,能够处理输入输出长度不一致的问题。
数据集与特征工程
Hey-Jetson 使用了 LibriSpeech ASR corpus 数据集,包含约1000小时的英语语音数据。在训练中使用了960小时的子集,音频长度在10-15秒之间。数据预处理包括将音频转换为单声道WAV格式,采样率16kHz,位率64k,并统一裁剪/填充到10秒长度。文本转录去除了除撇号外的所有标点,并转换为小写。
特征提取方面,项目探索了三种主要方法:
-
原始音频波形: 直接使用音频的一维幅度向量。
-
频谱图: 将原始波形转换为二维张量,横轴表示时间,纵轴表示频率。
-
MFCC: 梅尔频率倒谱系数,通过对信号进行傅里叶变换并取离散余弦变换得到,可以有效压缩特征维度。
模型训练与性能
模型在Nvidia GTX1070(8G) GPU上训练了30轮,总训练时间约6.5天。最终模型在测试集上达到了以下性能:
- 余弦相似度: 约78%(验证集80%)
- 词错误率(WER): 约18%(验证集16%)
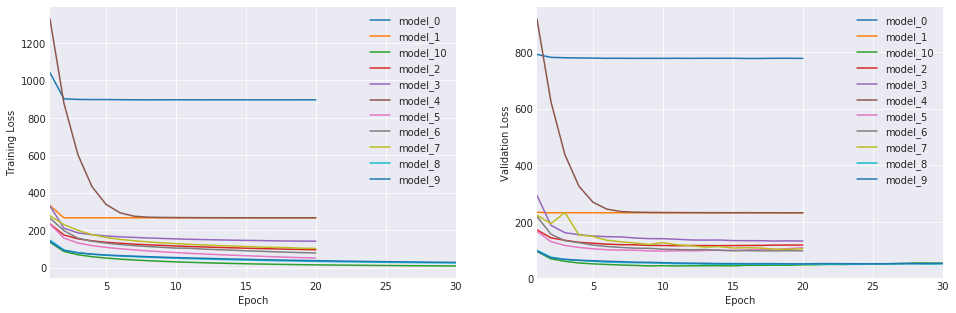
这一性能水平已经接近了项目设定的20%WER目标,证明了Hey-Jetson在边缘设备上实现高质量语音识别的可行性。
部署与推理
Hey-Jetson 项目不仅关注模型训练,还提供了完整的部署方案:
-
使用Flask开发了Web应用,通过REST API提供语音识别服务。
-
使用gunicorn作为WSGI服务器,并通过Nginx反向代理发布Web服务。
-
使用Supervisor进行进程管理,确保服务持续运行。
-
提供了详细的Jetson设备配置指南,包括刷机、安装依赖等步骤。
-
模型可在1-5秒内完成文本转录,实现了近实时的推理能力。
除基本的语音识别功能外,项目还集成了其他特性:
- 性能可视化工具,允许用户深入分析数据集和模型表现。
- 与Microsoft Azure认知服务API集成,用于基准测试。
- 提供基于Microsoft Speech-To-Text平台的JavaScript API。
- 使用Microsoft认知服务开发了情感分析引擎,可用于评估治疗干预的效果。
未来展望
Hey-Jetson 项目为边缘计算设备上的语音识别应用开辟了新的可能性。未来的改进方向包括:
- 构建更深层的模型架构。
- 训练模型以处理带背景噪声的音频。
- 使用更多语料库,如Mozilla的Common Voice数据集,实现说话者性别和口音识别。
- 开发处理敏感个人信息的生产系统。
- 实现在线学习,通过用户录音不断改进模型。
- 将模型迁移到TensorFlow以提高性能。
- 训练模型识别个别说话者,类似Google的说话者识别技术。
- 加入情感识别功能。
- 将推理引擎转换为Nvidia的TensorRT平台以进一步优化性能。
- 扩展到多语言支持。
- 尝试更先进的模型架构,如转录器模型。
Hey-Jetson 展示了深度学习在边缘计算设备上的巨大潜力。随着硬件性能的不断提升和算法的持续优化,我们可以期待在未来看到更多类似的创新应用,将人工智能的力量带到每个人的身边。



















