
Hidet简介
Hidet是一款强大的开源深度学习编译器,由Python编写而成。它的主要目标是简化在现代加速器(如NVIDIA GPU)上实现高性能深度学习算子的过程。Hidet的出现为深度学习从业者提供了一个新的选择,特别是对于那些需要实现高度优化的自定义算子的用户来说,Hidet无疑是一个极具吸引力的选项。
Hidet的主要特性
- 端到端编译:支持将PyTorch和ONNX模型编译为高效的CUDA内核。
- 图级优化:对模型的计算图进行优化,提升整体性能。
- 算子级优化:针对单个算子进行优化,进一步提升执行效率。
- Python API:提供友好的Python接口,便于集成和使用。
- 自动调优:能够自动搜索最佳的算子调度方案。
Hidet的安装与使用
安装Hidet
Hidet的安装非常简单,只需要通过pip包管理器即可完成:
pip install hidet
需要注意的是,Hidet目前主要针对NVIDIA GPU上的推理工作负载进行优化,因此在使用时需要满足以下条件:
- Linux操作系统
- CUDA Toolkit 11.6+
- Python 3.8+
对于想尝试最新功能的用户,也可以安装每日构建版本或从源代码构建。
使用Hidet优化PyTorch模型
以下是一个使用Hidet优化预训练ResNet18模型的简单示例:
import torch
import hidet
# 加载预训练的ResNet18模型
model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet18', pretrained=True).cuda().eval()
x = torch.rand(1, 3, 224, 224).cuda()
# 配置Hidet优化选项
hidet.torch.dynamo_config.use_tensor_core(True)
hidet.torch.dynamo_config.search_space(2)
# 使用Hidet编译模型
model_opt = torch.compile(model, backend='hidet')
# 运行优化后的模型
y = model_opt(x)
在这个例子中,我们首先加载了一个预训练的ResNet18模型,然后使用Hidet对其进行编译优化。通过设置use_tensor_core(True),我们允许Hidet生成利用NVIDIA GPU上Tensor Core的CUDA内核。而search_space(2)则允许Hidet搜索最适合当前硬件和输入尺寸的算子调度方案。
Hidet的工作原理
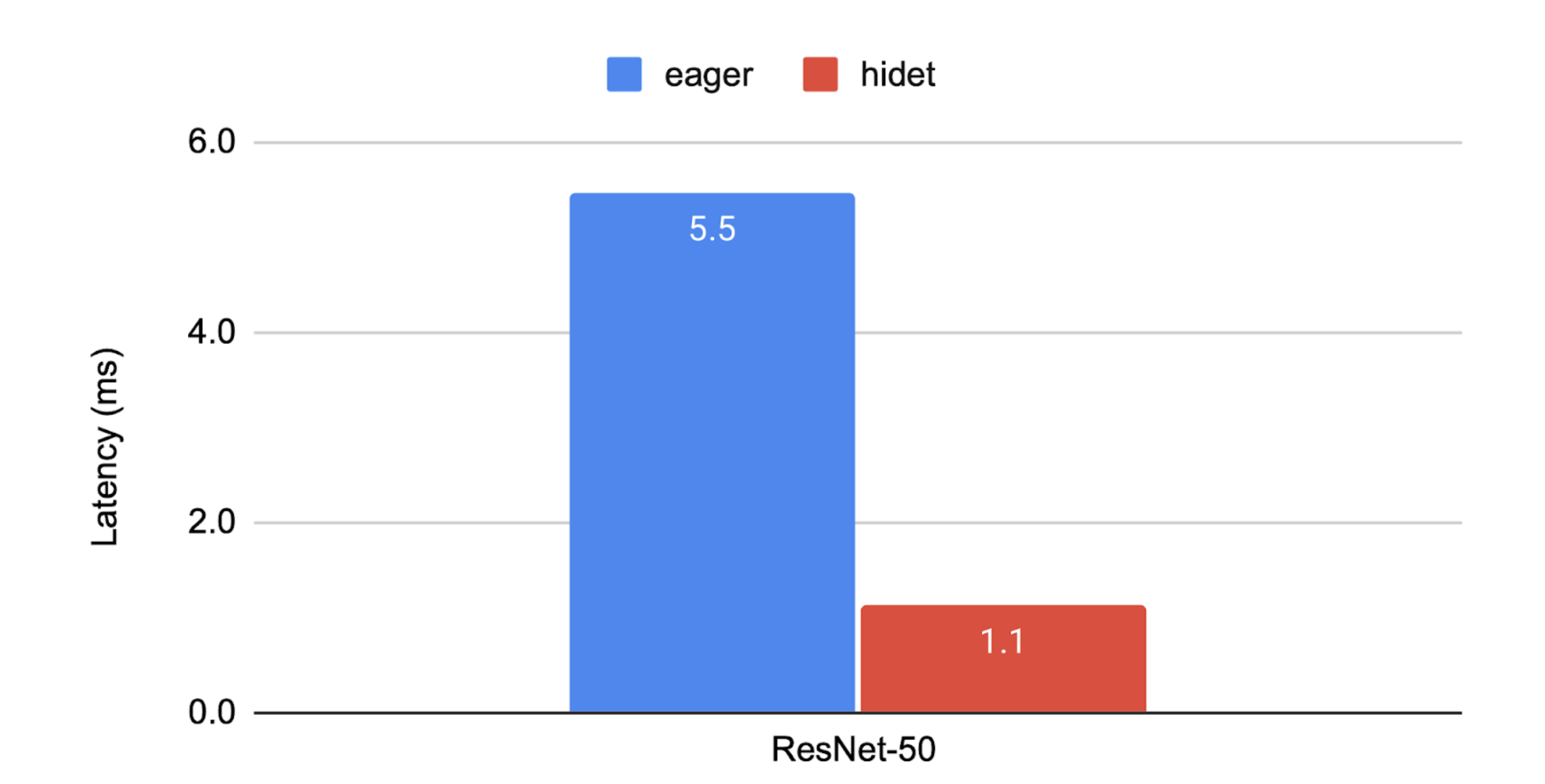
Hidet的工作原理可以概括为以下几个步骤:
- 模型转换:将PyTorch或ONNX模型转换为Hidet的内部图表示。
- 图级优化:对整个计算图进行优化,如算子融合、内存分配优化等。
- 算子级优化:针对单个算子进行优化,包括自动调优、张量核心利用等。
- 代码生成:生成优化后的CUDA内核代码。
- 运行时优化:使用CUDA Graph等技术减少框架级开销。
通过这一系列的优化步骤,Hidet能够显著提升模型的推理性能。如上图所示,在AWS g5.2xlarge实例上,Hidet优化后的ResNet50模型相比于PyTorch eager模式有明显的性能提升。
Hidet Script:自定义算子的利器
Hidet不仅提供了对现有模型的优化能力,还引入了Hidet Script,这是一种在Python中实现张量算子的方法。以下是使用Hidet Script实现简单矩阵乘法的示例:
import torch
import hidet
def matmul(m_size, n_size, k_size):
from hidet.lang import f32, attr
from hidet.lang.cuda import threadIdx, blockIdx, blockDim
with hidet.script_module() as script_module:
@hidet.script
def matmul(
a: f32[m_size, k_size],
b: f32[k_size, n_size],
c: f32[m_size, n_size]
):
attr.cuda_grid_dim = ((m_size + 31) // 32, (n_size + 31) // 32)
attr.cuda_block_dim = (32, 32)
i = threadIdx.x + blockIdx.x * blockDim.x
j = threadIdx.y + blockIdx.y * blockDim.y
if i < m_size and j < n_size:
c[i, j] = 0.0
for k in range(k_size):
c[i, j] += a[i, k] * b[k, j]
ir_module = script_module.ir_module()
func = hidet.driver.build_ir_module(ir_module)
return func
# 使用自定义算子
class NaiveMatmul(torch.autograd.Function):
@staticmethod
def forward(ctx, a, b):
m, k = a.shape
k, n = b.shape
c = torch.empty([m, n], dtype=a.dtype, device=a.device)
func = matmul(m, n, k)
func(a, b, c)
return c
a = torch.randn([3, 4], device='cuda')
b = torch.randn([4, 5], device='cuda')
c = NaiveMatmul.apply(a, b)
这个例子展示了如何使用Hidet Script实现一个简单的矩阵乘法算子,并将其集成到PyTorch中。Hidet Script的强大之处在于,它在简化张量编程的同时,仍然允许用户以灵活的方式实现自己的优化。
Hidet vs Triton:各有千秋
在深度学习编译器领域,Triton是另一个广受关注的项目。Hidet和Triton各有特点:
- Triton通过引入基于tile的编程模型大大简化了CUDA编程,但这种简化也限制了对细粒度计算和内存资源的操控。
- Hidet Script则在简化张量编程的同时,保留了对底层资源的细粒度控制能力,使得实现某些特定优化更为容易。
选择使用哪个工具,取决于具体的应用场景和优化需求。
Hidet的发展历程与未来展望
Hidet最初是由多伦多大学EcoSystem实验室和AWS联合领导的一个研究项目。项目团队提出了一种名为"任务映射编程范式"的新方法来构建张量程序,旨在简化张量编程而不牺牲任何优化机会。
目前,Hidet已经成为一个开源项目,由CentML Inc和EcoSystem实验室共同支持,致力于为现代加速器(如NVIDIA GPU)提供高效的端到端推理解决方案。
展望未来,Hidet团队计划进一步扩展其功能和优化能力:
- 支持更多深度学习框架和模型格式
- 增强对新硬件架构的支持
- 改进自动调优算法
- 提供更丰富的算子库和优化模式
结语
Hidet作为一个新兴的深度学习编译器,为模型推理性能优化提供了新的可能性。它的出现不仅为研究人员提供了一个强大的工具,也为工业界的深度学习应用带来了新的选择。随着人工智能技术的不断发展,像Hidet这样的工具将在提升模型部署效率、降低计算成本方面发挥越来越重要的作用。
无论您是深度学习研究人员、算法工程师还是对AI性能优化感兴趣的开发者,都可以尝试使用Hidet来优化您的模型。通过探索Hidet的各种功能,相信您会发现它在模型推理加速方面的独特优势。









