
InferLLM简介
InferLLM是由MegEngine团队开发的一个轻量级大语言模型(LLM)推理框架。它主要参考和借鉴了llama.cpp项目,但对其进行了重构和优化,使其更易于开发者阅读和修改。InferLLM具有以下几个主要特点:
- 结构简单,易于上手和学习,将框架部分和内核部分解耦。
- 高效性能,移植了llama.cpp中的大部分内核。
- 定义了专门的KVstorage类型,便于缓存和管理。
- 兼容多种模型格式(目前支持alpaca中英文int4模型)。
- 支持CPU和GPU,针对Arm、x86、CUDA和RISC-V向量进行了优化。
- 可部署在移动设备上,具有可接受的运行速度。
简而言之,InferLLM是一个简单高效的LLM CPU推理框架,可以在本地部署量化模型并实现良好的推理速度。
最新动态
InferLLM项目一直在持续更新和优化中,以下是一些最新的进展:
- 2023年8月16日:增加了对LLama-2-7B模型的支持。
- 2023年8月8日:优化了Arm平台上的性能,使用arm汇编和内核打包优化了int4矩阵乘法内核。
- 之前:支持了ChatGLM/ChatGLM2、Baichuan、Alpaca、GGML-LLama等多种模型。
使用方法
下载模型
InferLLM使用与llama.cpp相同的模型,可以从llama.cpp项目下载模型。此外,也可以直接从Hugging Face上的kewin4933/InferLLM-Model仓库下载模型。目前该项目上传了两个alpaca模型、llama2模型、chatglm/chatglm2模型和baichuan模型,分别是中文int4模型和英文int4模型。
编译InferLLM
本地编译
mkdir build
cd build
cmake ..
make
默认情况下GPU是禁用的,如果想启用GPU,请使用cmake -DENABLE_GPU=ON ..来启用GPU。目前仅支持CUDA,使用CUDA之前请先安装CUDA工具包。
Android交叉编译
对于Android交叉编译,可以使用预先准备好的tools/android_build.sh脚本。需要提前安装NDK并将NDK的路径配置到NDK_ROOT环境变量中。
export NDK_ROOT=/path/to/ndk
./tools/android_build.sh
运行InferLLM
运行ChatGLM模型请参考ChatGLM模型文档。
如果在本地执行,直接运行./chatglm -m chatglm-q4.bin -t 4。如果想在手机上执行,可以使用adb命令将alpaca和模型文件复制到手机上,然后执行adb shell ./chatglm -m chatglm-q4.bin -t 4。
默认设备是CPU,如果想使用GPU进行推理,请使用./chatglm -m chatglm-q4.bin -g GPU来指定GPU设备。
以下是在不同平台上运行的效果展示:
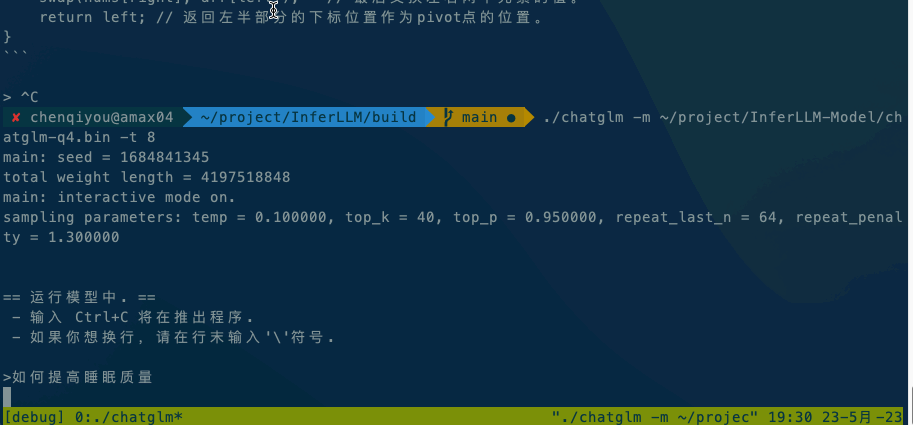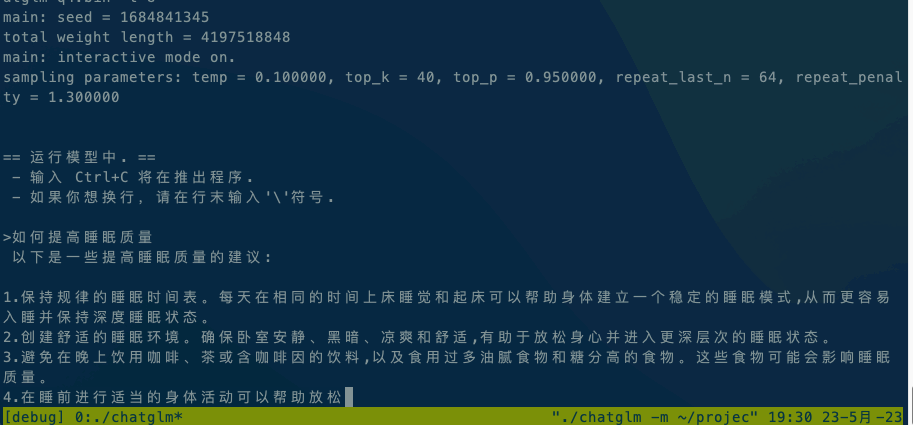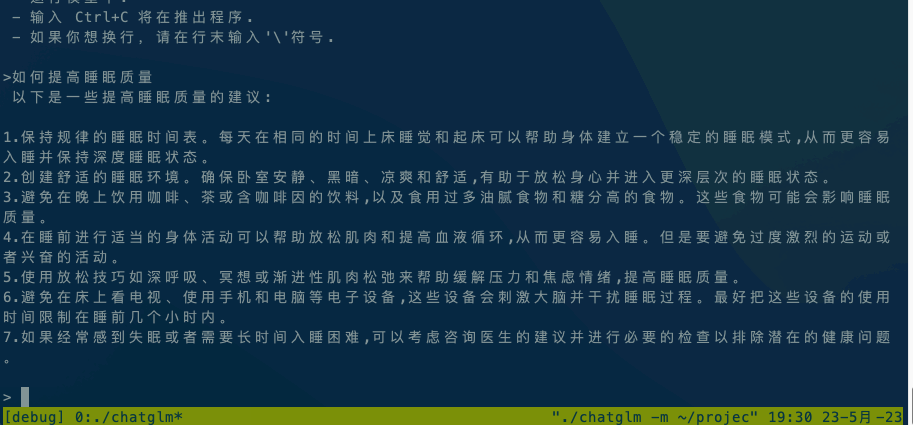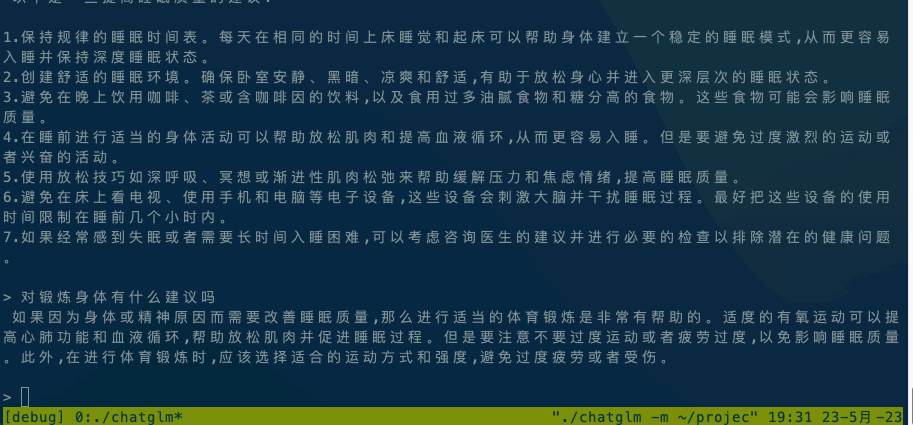
x86平台:Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
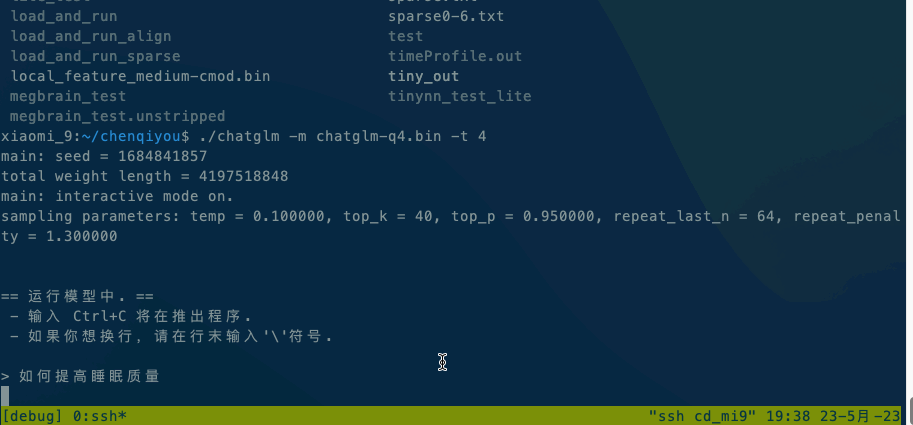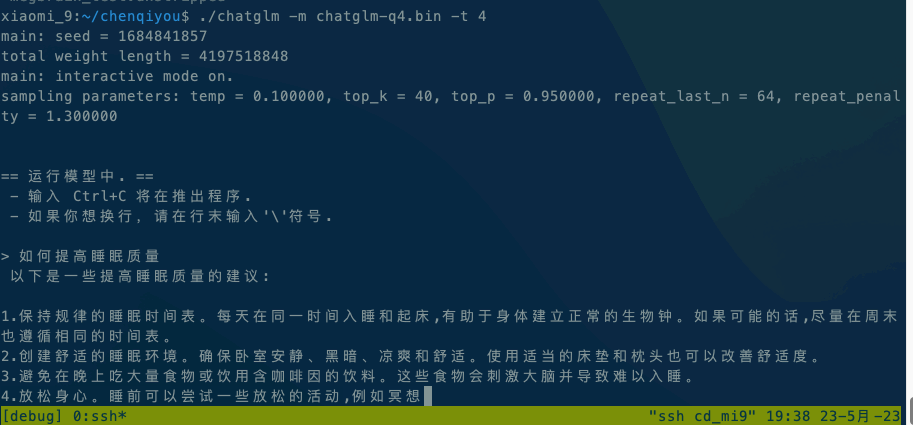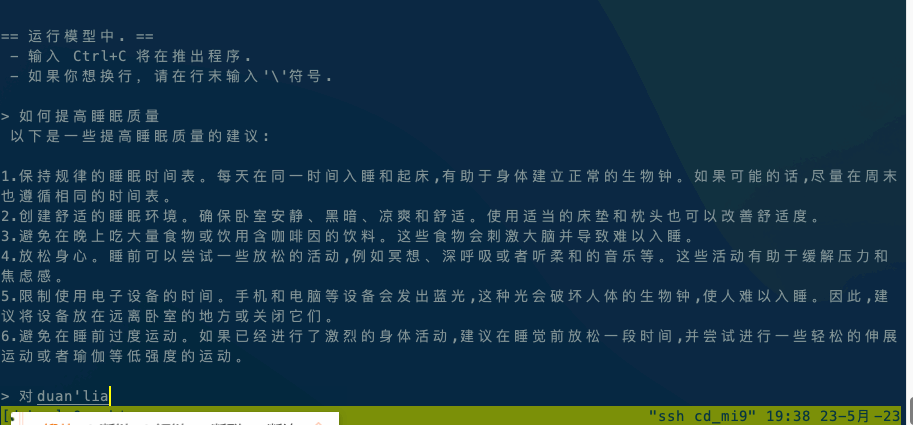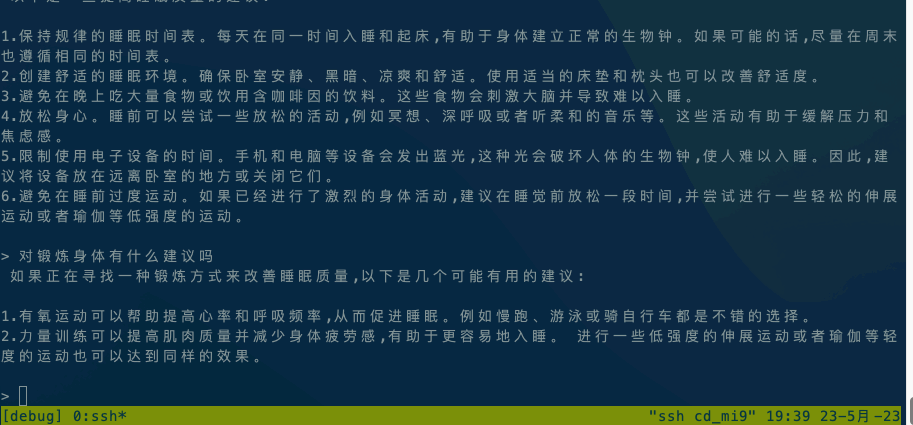
Android平台:小米9,高通SM8150骁龙855

RISC-V平台:SG2042,带RISC-V向量0.7,64线程
根据x86性能分析结果,我们强烈建议使用4个线程。
支持的模型
目前InferLLM支持以下模型:
- ChatGLM2-6B:使用方法请参考ChatGLM文档
- ChatGLM-6B:使用方法请参考ChatGLM文档
- LLaMA
- LLaMA 2
- Alpaca
- Baichuan:使用方法请参考Baichuan文档
许可证
InferLLM采用Apache License 2.0许可证。这意味着您可以自由地使用、修改和分发该软件,但需要遵守该许可证的条款。
总结
InferLLM作为一个轻量级的大语言模型推理框架,为开发者提供了一个简单高效的工具,可以在本地部署和运行各种量化后的LLM模型。它支持多种流行的模型,如ChatGLM、LLaMA、Alpaca等,并且在不同的硬件平台上都能实现良好的性能。无论是在服务器、个人电脑还是移动设备上,InferLLM都能为用户提供流畅的大语言模型推理体验。
随着项目的不断更新和优化,我们可以期待InferLLM在未来支持更多的模型和硬件平台,为大语言模型的应用和研究提供更强大的工具支持。对于那些希望在本地或边缘设备上部署大语言模型的开发者和研究人员来说,InferLLM无疑是一个值得关注和尝试的项目。










