InferLLM简介
InferLLM是由MegEngine开源的轻量级LLM模型推理框架,主要参考和借鉴了llama.cpp项目。相比llama.cpp,InferLLM具有以下特点:
- 结构简单,易于上手学习,将框架部分和内核部分解耦
- 高效实现,移植了llama.cpp中的大部分内核
- 定义了专门的KVstorage类型,便于缓存和管理
- 兼容多种模型格式(目前支持Alpaca中英文int4模型)
- 支持CPU和GPU,针对Arm、x86、CUDA和RISC-V向量进行了优化
- 可部署到手机上,推理速度可接受
总之,InferLLM是一个简单高效的LLM CPU推理框架,可以在本地部署量化的LLM模型,并具有良好的推理速度。
快速开始
1. 下载模型
InferLLM使用与llama.cpp相同的模型格式。您可以直接从Hugging Face下载已经量化好的Int4模型,包括:
- Alpaca中文/英文模型
- LLaMA 2模型
- ChatGLM/ChatGLM2模型
- Baichuan模型
2. 编译InferLLM
本地编译:
mkdir build
cd build
cmake ..
make
如需启用GPU支持,请使用:
cmake -DENABLE_GPU=ON ..
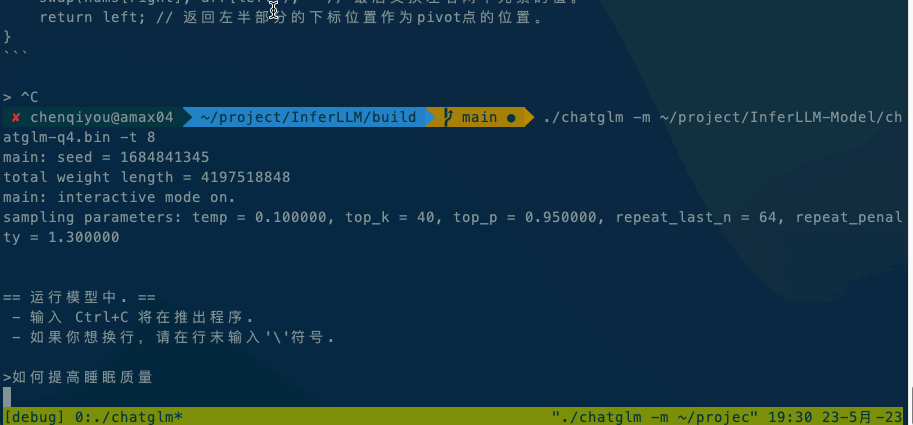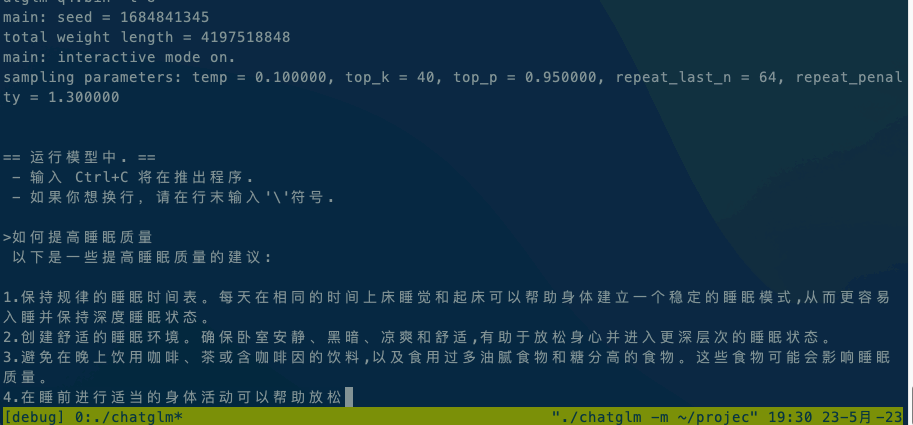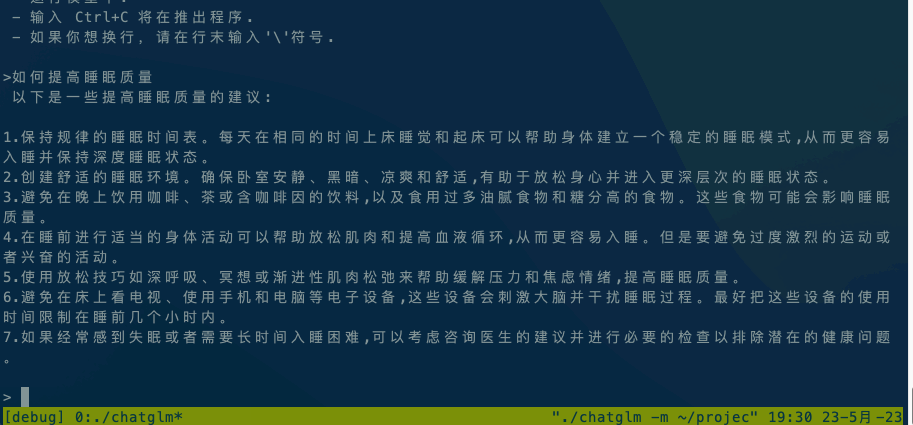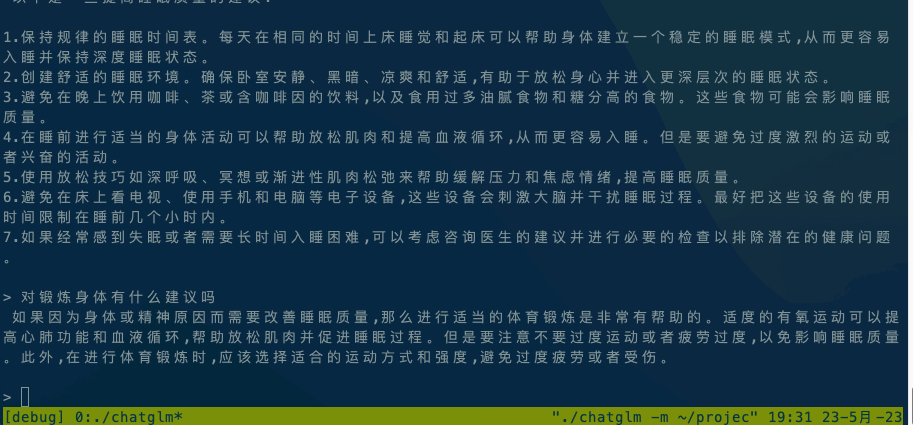
3. 运行模型
以ChatGLM模型为例:
./chatglm -m chatglm-q4.bin -t 4
默认使用CPU设备,如需使用GPU:
./chatglm -m chatglm-q4.bin -g GPU
支持的模型
InferLLM目前支持以下模型:
更多资源
InferLLM采用Apache 2.0开源协议。如果您在使用过程中遇到任何问题,欢迎在GitHub Issues中反馈。