
InferLLM
InferLLM 是一个轻量级的LLM模型推理框架,主要参考并借鉴了llama.cpp项目。llama.cpp将几乎所有核心代码和内核放在一个文件中,并且使用了大量的宏,导致开发者难以阅读和修改。InferLLM具有以下特点:
- 结构简单,易于上手和学习,并且将框架部分与内核部分解耦。
- 高效,移植了llama.cpp中的大部分内核。
- 定义了专用的KV存储类型,便于缓存和管理。
- 兼容多种模型格式(目前仅支持中文和英文int4模型的alpaca)。
- 目前支持CPU和GPU,对Arm、x86、CUDA和riscv-vector进行了优化。并且可以在手机上部署,速度可接受。
总之,InferLLM是一个简单高效的LLM CPU推理框架,可以在本地部署量化模型,并具有良好的推理速度。
最新动态
- 2023.08.16:新增对LLama-2-7B模型的支持。
- 2023.08.8:优化了在Arm上的性能,使用arm asm优化了int4矩阵乘法内核和内核打包。
- berfor:支持chatglm/chatglm2、baichuan、alpaca、ggml-llama模型。
如何使用
下载模型
目前,InferLLM使用和llama.cpp相同的模型,可以从llama.cpp项目下载模型。此外,还可以直接从Hugging Face下载模型 kewin4933/InferLLM-Model。目前已上传两个alpaca、llama2、chatglm/chatglm2和baichuan模型,其中一个是中文int4模型,另一个是英文int4模型。
编译 InferLLM
本地编译
mkdir build
cd build
cmake ..
make
默认情况下禁用GPU,如果要启用GPU,请使用cmake -DENABLE_GPU=ON ..启用GPU。目前仅支持CUDA,在使用CUDA之前,请先安装CUDA开发工具包。
安卓交叉编译
根据交叉编译,可以使用预先准备好的tools/android_build.sh脚本。需要提前安装NDK并将NDK的路径配置到NDK_ROOT环境变量。
export NDK_ROOT=/path/to/ndk
./tools/android_build.sh
运行 InferLLM
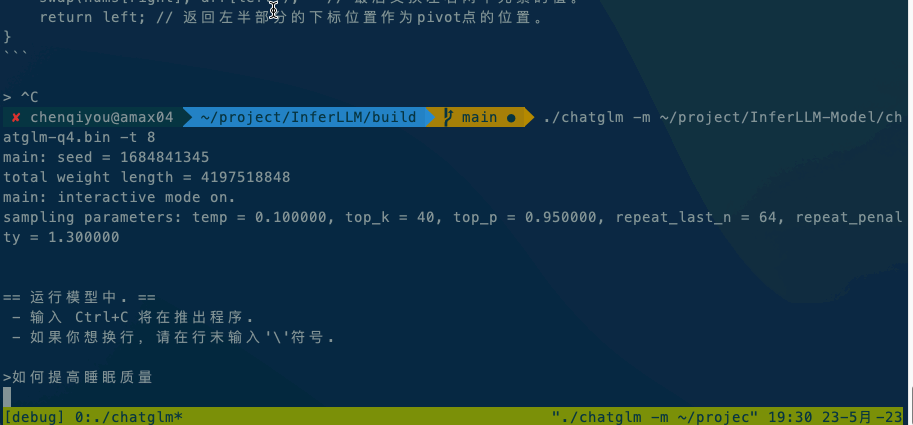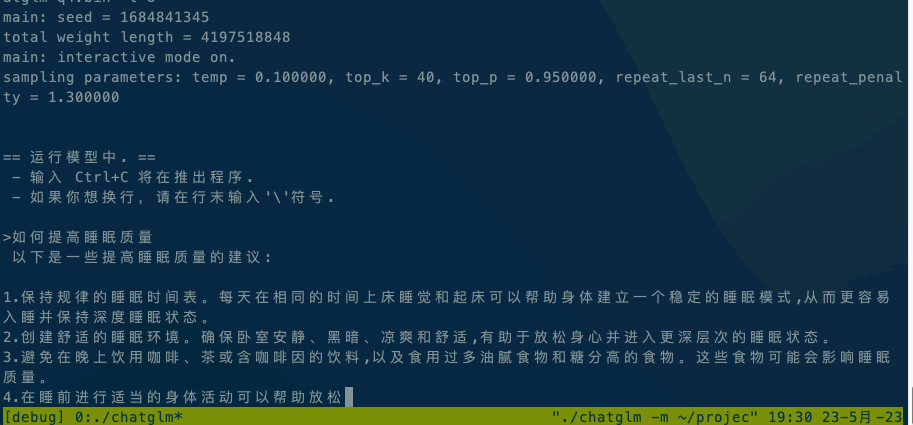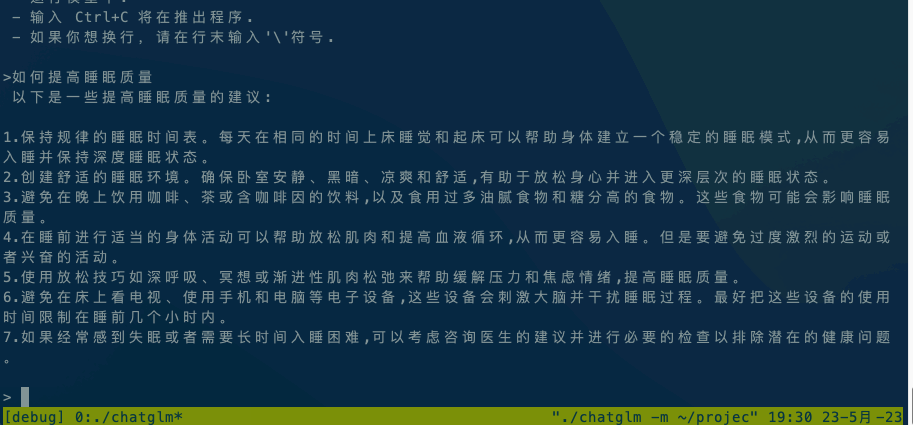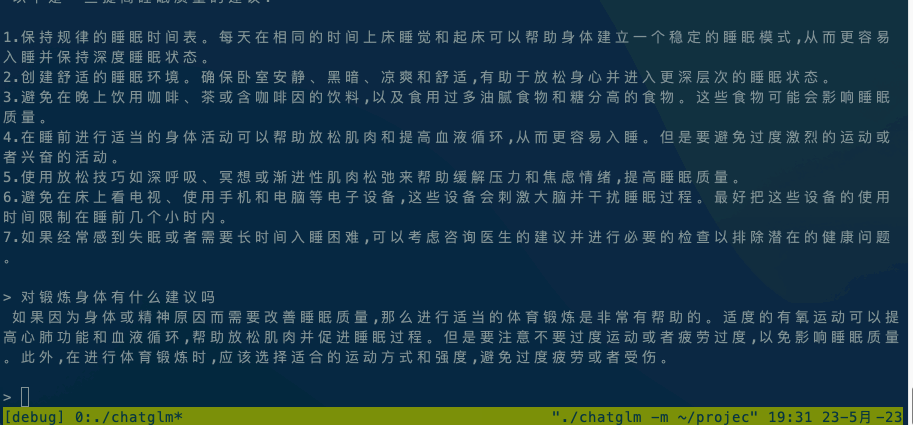
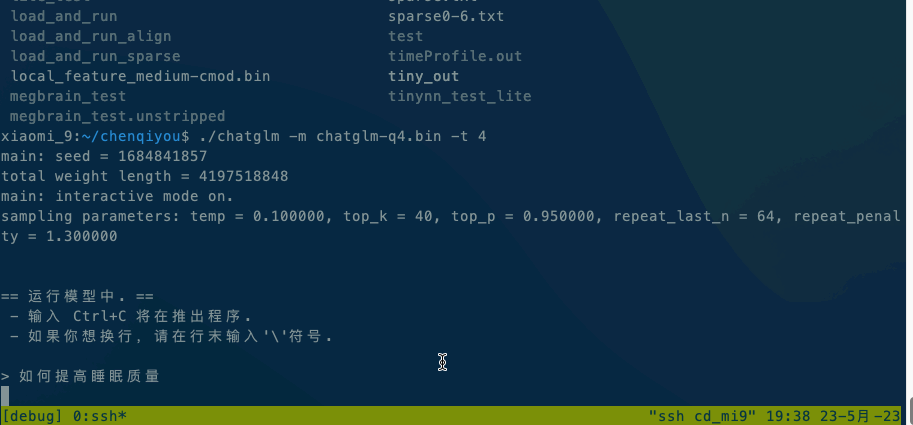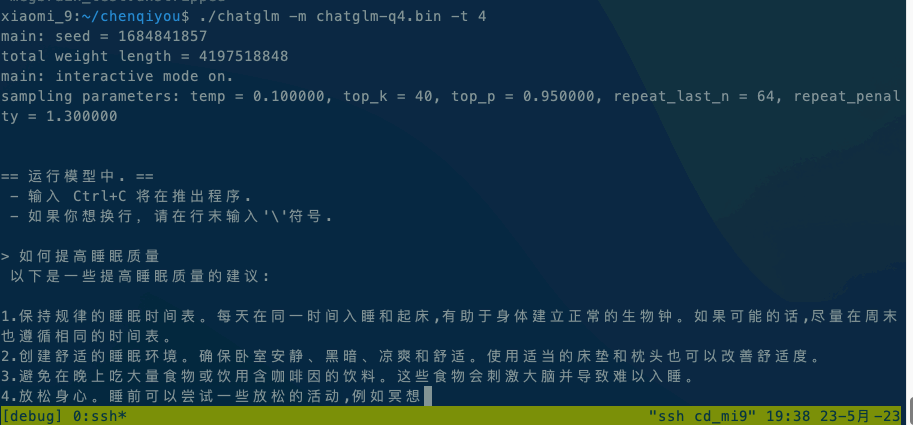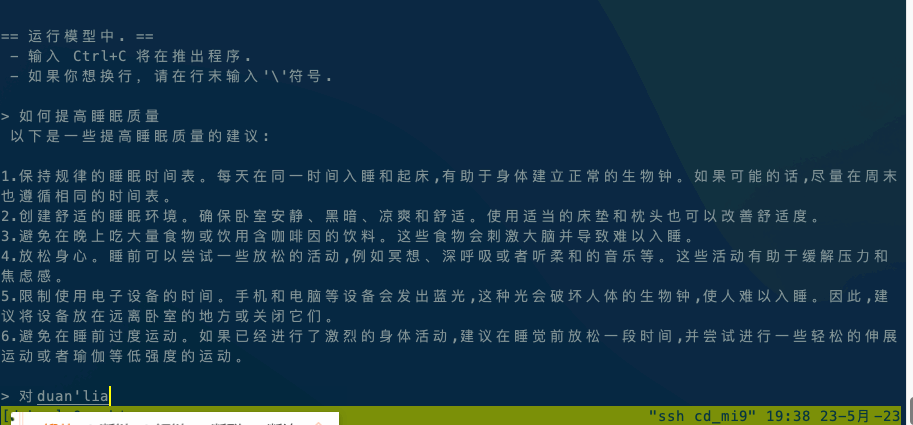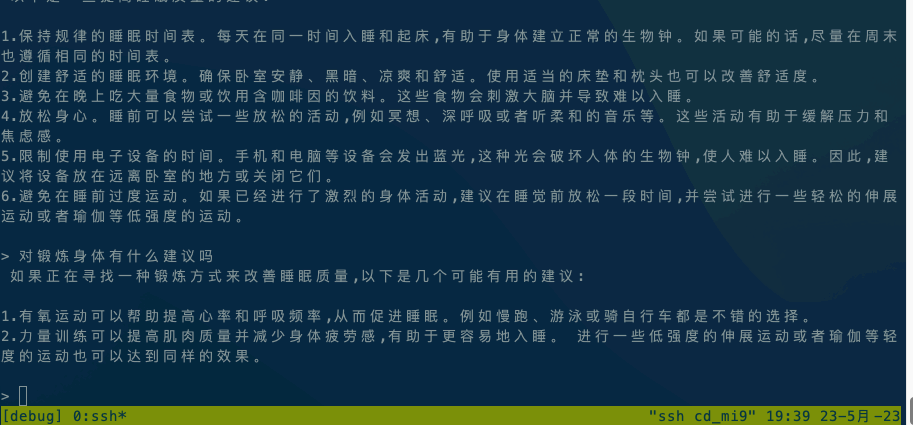
运行ChatGLM模型请参阅ChatGLM模型文档。
如果在本地执行,直接执行 ./chatglm -m chatglm-q4.bin -t 4。如果想在手机上执行,可以使用adb命令将alpaca和模型文件复制到手机上,然后执行 adb shell ./chatglm -m chatglm-q4.bin -t 4。
默认设备是CPU,如果想使用GPU进行推理,请使用./chatglm -m chatglm-q4.bin -g GPU指定GPU设备。
- x86 是:Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10GHz
- 安卓是 小米9,Qualcomm SM8150 Snapdragon 855
- CPU 是 SG2042,具备 riscv-vector 0.7,64线程

根据x86性能分析结果,我们强烈建议使用4线程。
支持的模型
现在InferLLM支持以下模型:
- ChatGLM2-6B:用法请参考ChatGLM
- ChatGLM-6B:用法请参考ChatGLM
- llama
- llama2
- alpaca
- baichuan:用法请参考baichuan
许可协议
InferLLM 采用 Apache 许可证,版本 2.0 许可证。











