
InfLLM简介
InfLLM (Infinite-context Large Language Model) 是由清华大学自然语言处理实验室(THUNLP)开发的一种创新技术,旨在解决大语言模型处理超长序列输入的问题。它通过一种无需额外训练的基于内存的方法,使预训练的大语言模型能够有效处理和理解极长的输入序列。
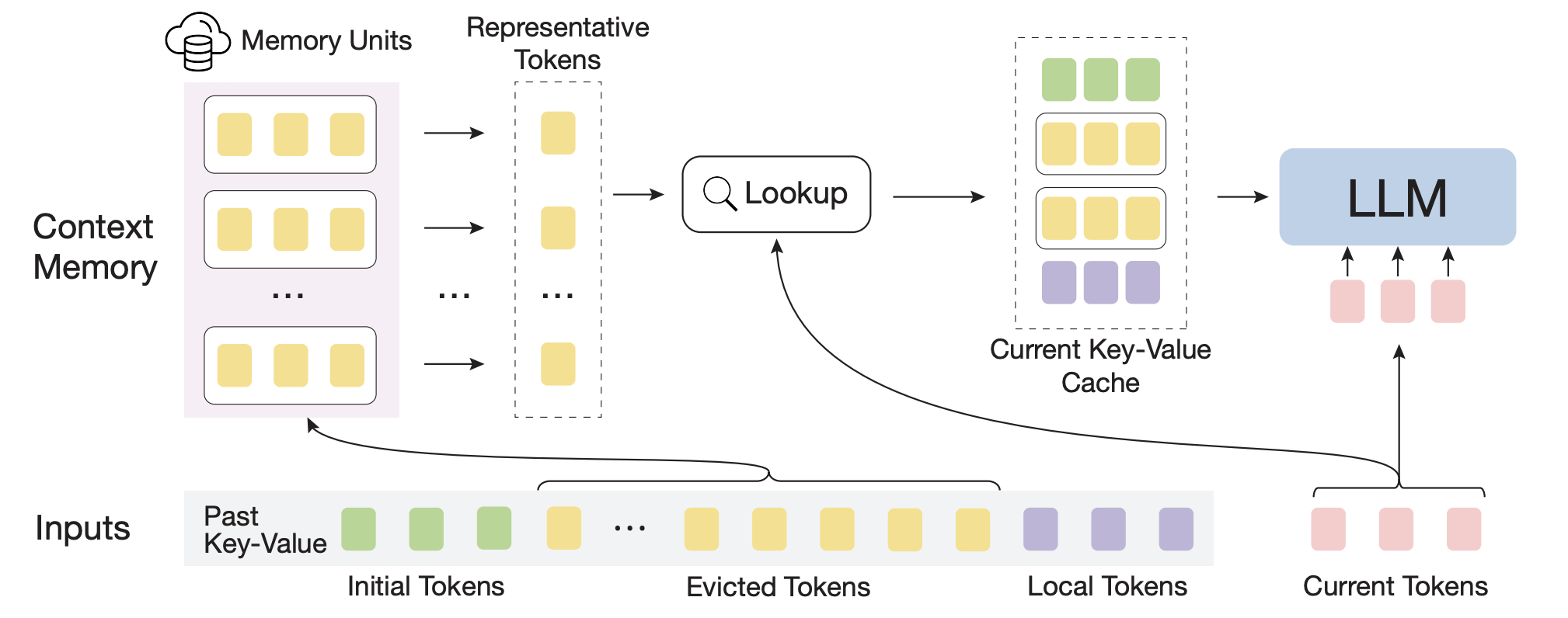
主要特点
- 🚀 无需额外训练:InfLLM可以直接应用于现有的预训练模型,无需昂贵的continual pre-training。
- 📏 支持超长上下文:即使对于原本只能处理几千个token的模型,InfLLM也能让其处理长达100万token的输入。
- 🧠 高效内存机制:通过将远距离上下文存储在额外的内存单元中,并使用高效的检索机制进行注意力计算。
- 🔗 保留长距离依赖:与滑动窗口等方法不同,InfLLM能够有效捕获序列中的长距离依赖关系。
学习资源
-
💻 代码实现:GitHub - thunlp/InfLLM
-
🛠️ 使用指南:
- 配置说明:查看GitHub仓库中的
config/目录 - 评估方法:使用InfiniteBench和LongBench数据集
- 运行聊天机器人:集成了fastchat的CLI聊天功能
- 配置说明:查看GitHub仓库中的
-
🆕 更新日志:
- 2024年3月3日:初始代码发布
- 2024年3月24日:重构代码,提高推理速度并减少GPU内存使用
- 2024年4月4日:支持使用faiss进行topk检索
- 2024年4月20日:增加对LLaMA 3的支持
快速上手
要开始使用InfLLM,您可以按照以下步骤操作:
-
克隆GitHub仓库:
git clone https://github.com/thunlp/InfLLM.git -
安装依赖:
pip install -r requirements.txt -
运行评估:
bash scripts/infinitebench.sh或
bash scripts/longbench.sh -
运行聊天机器人:
python -m inf_llm.chat \ --model-path mistralai/Mistral-7B-Instruct-v0.2 \ --inf-llm-config-path config/mistral-inf-llm.yaml
深入探索
对于想要深入了解InfLLM工作原理的研究者和开发者,可以关注以下几个关键点:
- 内存单元的设计和管理机制
- 注意力计算中的token相关单元查找算法
- 长距离依赖的捕获和利用方式
- 与其他长上下文处理方法(如滑动窗口)的比较
结语
InfLLM为大语言模型处理超长序列输入提供了一种高效且易于实施的解决方案。通过本文提供的学习资源,读者可以深入了解InfLLM的工作原理,并将其应用到自己的项目中。随着技术的不断发展,我们期待看到更多基于InfLLM的创新应用和研究成果。
🔗 欢迎访问InfLLM GitHub仓库获取最新更新和详细信息!










