
LLaMA和RWKV的ONNX实现:开启高效AI推理新篇章
在人工智能快速发展的今天,大型语言模型(LLM)如LLaMA和RWKV的出现极大地推动了自然语言处理技术的进步。然而,如何在各类硬件设备上高效部署这些庞大的模型,一直是学术界和工业界关注的焦点。GitHub上的llama.onnx项目为我们提供了一个优秀的解决方案,通过将LLaMA和RWKV转换为ONNX格式,并进行一系列优化,使得这些强大的AI模型能够在更广泛的场景中发挥作用。
ONNX模型:跨平台AI部署的桥梁
ONNX(Open Neural Network Exchange)作为一种开放的神经网络交换格式,为AI模型的跨平台部署提供了极大的便利。llama.onnx项目正是基于ONNX的优势,将LLaMA和RWKV这两个广受关注的大型语言模型转换为ONNX格式,并提供了相应的量化和推理优化方案。
目前,该项目已经发布了多个版本的ONNX模型:
- LLaMA-7B (fp32): 26GB
- LLaMA-7B (fp16): 13GB
- RWKV-4-palm-430M (fp16): 920MB
这些模型可以从Hugging Face或硬件模型库等平台下载,为研究者和开发者提供了便捷的资源获取途径。
突破性特性:无需PyTorch,运行更轻量
llama.onnx项目的一大亮点在于其独立性和轻量化设计:
- 发布了LLaMA-7B和RWKV-400M的ONNX模型及其独立运行demo。
- 无需依赖PyTorch或Transformers库。
- 通过内存池优化,支持在2GB内存的笔记本上运行(尽管速度较慢)。
这些特性使得模型部署变得更加灵活,尤其适合资源受限的嵌入式设备或分布式系统。
深入技术细节:从导出到优化
将LLaMA和RWKV转换为ONNX并非易事,项目提供了详细的步骤指南:
RWKV导出流程:
- 克隆RWKV项目并下载模型。
- 使用提供的
onnx_RWKV_in_150_lines.py脚本进行转换。
LLaMA导出流程:
- 将模型转换为Hugging Face格式。
- 使用
torch.onnx.export进行导出。 - 可选择转换为fp16或使用TVM进行进一步优化。
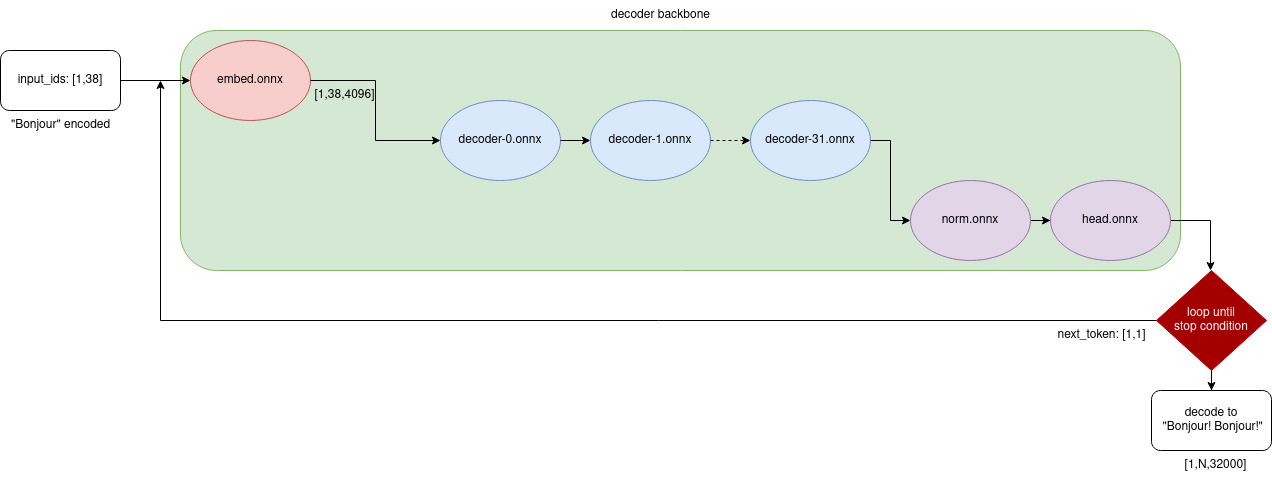
优化技术:提升推理效率
项目采用了多项优化技术来提高模型的推理效率:
- 图可视化: 支持嵌套结构或算子折叠,便于分析复杂模型。
- 量化: 利用LLM的重复特性,实现部分量化以减小模型体积。
- 分布式推理: 支持在多种异构设备(FPGA/NPU/GPGPU)上进行分布式推理。
这些优化不仅提高了模型的运行速度,还降低了内存占用,使得在资源受限的环境中部署大型语言模型成为可能。
实际应用:简单易用的demo
项目提供了简洁的demo脚本,方便用户快速上手:
# 安装依赖
python3 -m pip install -r requirements.txt
# 运行LLaMA demo
python3 demo_llama.py ${FP16_ONNX_DIR} "bonjour"
# 内存受限时使用内存池
python3 demo_llama.py ${FP16_ONNX_DIR} "bonjour" --poolsize 4
# 运行RWKV demo
python3 demo_rwkv.py ${FP16_ONNX_DIR}
这些demo不仅展示了模型的基本功能,还验证了ONNX格式转换后的精度,确保了模型性能的可靠性。
未来展望:混合精度与进一步优化
llama.onnx项目的发展并未止步于此。开发团队正在积极探索混合精度内核优化技术,以期在保持模型性能的同时进一步降低资源消耗。同时,项目也在不断完善量化指南,为用户提供更多细粒度的优化选项。
结语:开源协作,推动AI民主化
llama.onnx项目的成功离不开开源社区的贡献。从RWKV到LLaMA,从Alpaca到Transformers,每一个相关项目都为本项目的发展提供了宝贵的经验和技术支持。这种开放共享的精神不仅加速了AI技术的迭代,也让更多开发者能够参与到大型语言模型的应用与创新中来。
随着项目的不断完善和社区的持续贡献,我们有理由相信,LLaMA和RWKV的ONNX实现将为AI的普及应用铺平道路,让更多人能够从这一前沿技术中受益。无论是在学术研究、工业应用还是个人项目中,llama.onnx都为我们提供了一个强大而灵活的工具,助力我们在AI时代乘风破浪,开创新的可能。














