
LLM-Shearing:加速大语言模型预训练的结构化剪枝方法 - 学习资料汇总
LLM-Shearing是由普林斯顿大学研究人员提出的一种通过结构化剪枝来加速大语言模型预训练的方法。该方法可以在保持模型性能的同时大幅降低训练成本,为构建高效的小规模语言模型提供了新的思路。本文汇总了LLM-Shearing项目的相关学习资料,帮助读者快速了解和使用这一方法。
📄 论文
这是LLM-Shearing方法的原始论文,详细介绍了该方法的原理和实验结果。
💻 代码实现
LLM-Shearing的官方代码实现,包含了完整的训练和评估流程。
🤗 预训练模型
使用LLM-Shearing方法训练得到的1.3B和2.7B参数规模的语言模型,可以直接下载使用。
📚 技术博客
对LLM-Shearing方法的详细介绍,包括方法原理、实验结果和未来展望等。
🛠️ 使用指南
- 安装依赖:
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn==1.0.3.post
cd llmshearing
pip install -r requirement.txt
-
数据准备:参考llmshearing/data
-
模型剪枝:使用pruning.sh脚本
-
继续预训练:使用
llmshearing/scripts/continue_pretraining.sh脚本 -
模型转换:使用composer_to_hf.py脚本将模型转换为Hugging Face格式
🔬 实验结果
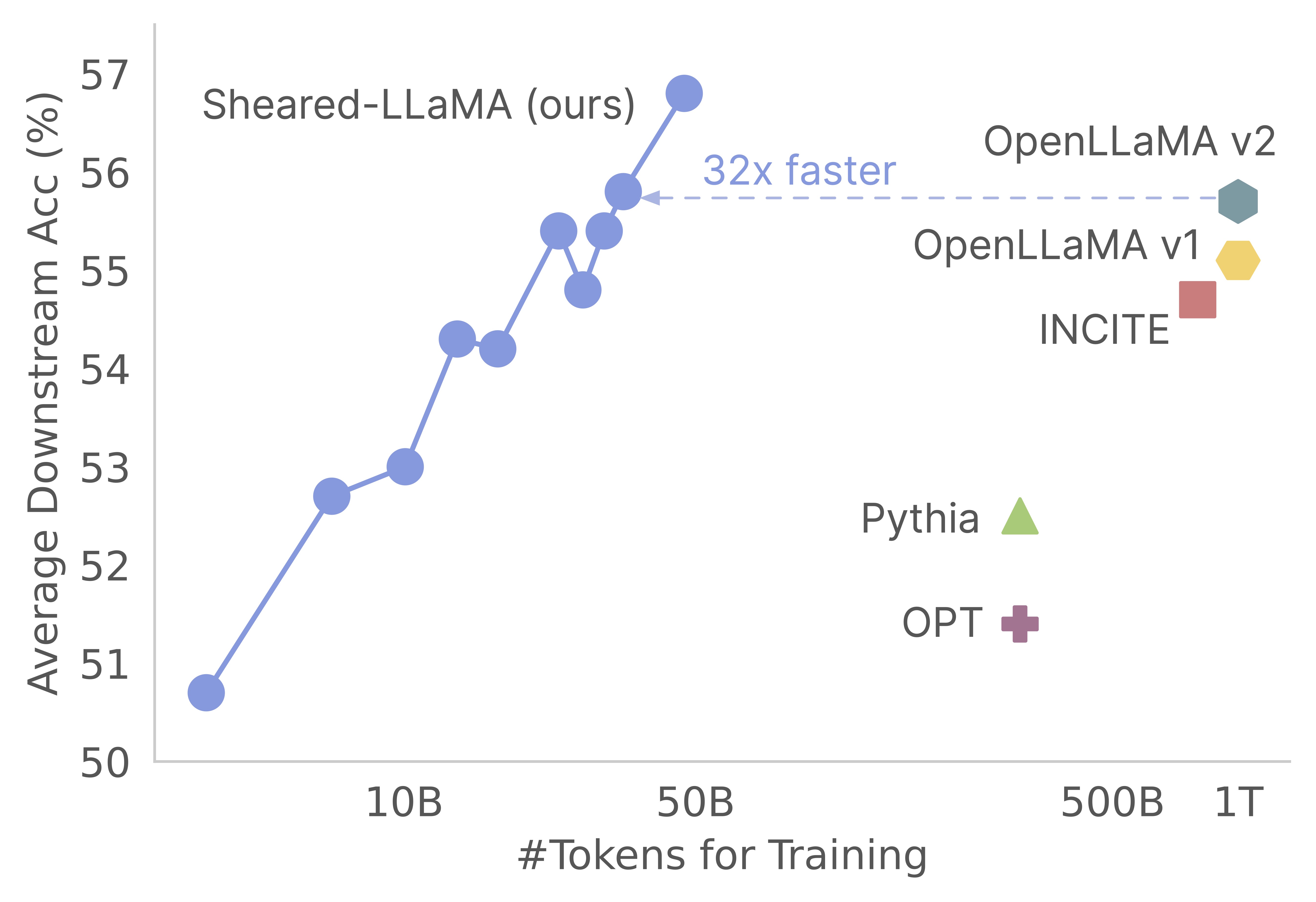
LLM-Shearing方法在多个下游任务上的表现优于同等规模的其他开源模型,同时只需要3%的训练计算量。具体结果可参考论文中的实验部分。
🔗 相关资源
- RedPajama数据集:用于训练的大规模语料库
- Composer包:LLM-Shearing基于此包实现
- Flash Attention:用于加速Transformer训练的技术
🙋 问题反馈
如有任何问题,可以在GitHub Issues中提出,或直接联系作者Mengzhou Xia(mengzhou@princeton.edu)。
LLM-Shearing为构建高效的小规模语言模型提供了新的思路,相信随着研究的深入,这一方法会在更多场景中发挥作用。欢迎感兴趣的读者深入探索并贡献自己的想法!


















