
MelGAN:高效的神经网络声码器
MelGAN是一种基于生成对抗网络(GAN)的神经网络声码器,由Kundan Kumar等人于2019年提出。它可以将梅尔频谱图转换为高质量的音频波形,在语音合成领域具有广阔的应用前景。相比传统的声码器,MelGAN具有轻量、快速、泛化能力强等优点,受到了学术界和工业界的广泛关注。
MelGAN的工作原理
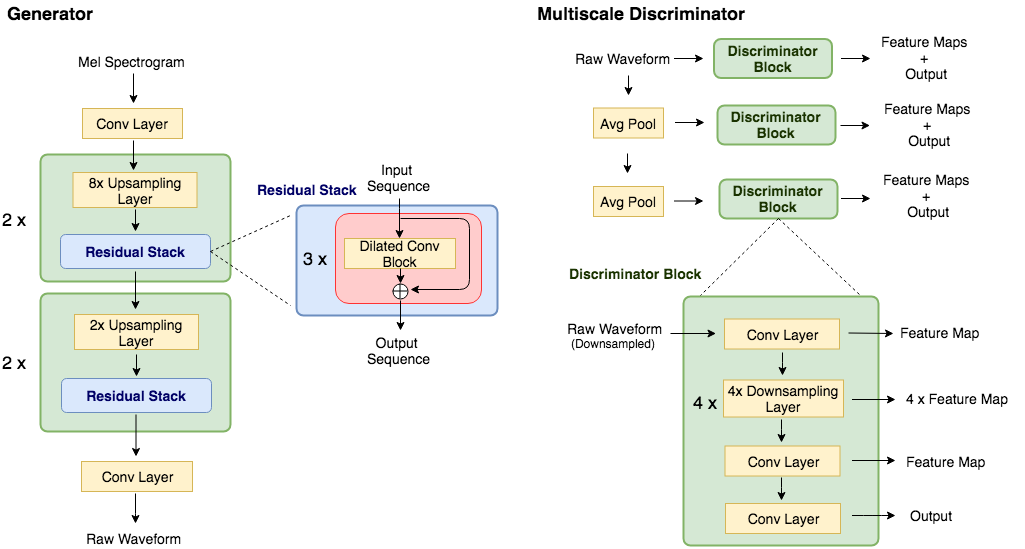
MelGAN的核心思想是利用生成对抗网络来学习梅尔频谱图到音频波形的映射。它包含一个生成器和多个判别器:
- 生成器:采用全卷积网络结构,通过转置卷积逐步将低分辨率的梅尔频谱图上采样为高分辨率的音频波形。
- 判别器:包括多尺度判别器和多分辨率判别器,从不同角度判断生成音频的真实性。
在训练过程中,生成器和判别器相互博弈,不断提高生成音频的质量。MelGAN还采用了特征匹配损失等技巧来稳定训练过程。
MelGAN的主要特点
-
轻量级:MelGAN的模型参数量较少,推理速度快,可以实现实时语音合成。
-
非自回归:MelGAN是一种非自回归模型,可以并行生成音频样本,效率高。
-
泛化能力强:MelGAN对未见过的说话人具有良好的泛化能力,可以生成自然的语音。
-
高质量:MelGAN生成的音频质量接近真实语音,主观评分(MOS)较高。
-
与其他模型兼容:MelGAN可以与Tacotron2等文本到梅尔频谱图模型无缝对接。
MelGAN的应用
MelGAN在语音合成领域有广泛的应用,主要包括:
-
文本转语音(TTS):结合Tacotron2等模型,实现端到端的文本到语音转换。
-
语音转换:将一个说话人的语音转换为另一个说话人的语音风格。
-
语音增强:去除语音中的噪声,提高语音质量。
-
音乐生成:将MIDI等符号表示转换为真实的音乐音频。
MelGAN的实现与使用
目前已有多个开源的MelGAN实现,其中较为知名的是seungwonpark的PyTorch实现。该实现具有以下特点:
- 与NVIDIA的Tacotron2兼容,可以直接用于转换Tacotron2的输出。
- 提供了预训练模型,可以通过PyTorch Hub轻松加载使用。
- 支持在多GPU上训练,提高了训练效率。
使用该实现可以很方便地训练和使用MelGAN模型:
import torch
# 加载预训练模型
vocoder = torch.hub.load('seungwonpark/melgan', 'melgan')
vocoder.eval()
# 准备输入梅尔频谱图
mel = torch.randn(1, 80, 234) # 假设这是你的梅尔频谱图
# 生成音频
with torch.no_grad():
audio = vocoder.inference(mel)
MelGAN的发展与展望
自MelGAN提出以来,研究人员对其进行了多方面的改进:
-
Multi-band MelGAN:将音频分成多个频带分别处理,进一步提高了音质。
-
HiFi-GAN:改进了判别器结构,在音质和推理速度上都有提升。
-
Universal MelGAN:通过多分辨率谱图判别器等技术,提高了模型在多领域的泛化能力。
未来,MelGAN还有很大的发展空间:
-
进一步提高音质,特别是在高频部分的还原度。
-
降低计算复杂度,使其能在移动设备等资源受限的环境中运行。
-
增强对多语言、多说话人的支持能力。
-
探索在更多音频生成任务中的应用。
总的来说,MelGAN作为一种高效的神经网络声码器,在语音合成领域具有重要意义。它不仅推动了学术研究的发展,也为工业应用提供了新的可能。随着技术的不断进步,我们有理由相信MelGAN会在更多场景中发挥重要作用,为人们带来更好的语音交互体验。














