
项目简介
TrOCR 模型是一个编码器-解码器模型,由图像 Transformer 充当编码器,文本 Transformer 充当解码器。图像编码器是使用 BEiT 的权重进行初始化的,而文本解码器则是使用 RoBERTa 的权重进行初始化。
图像被呈现给模型作为一系列固定大小的图块(分辨率为 16x16),这些图块被线性嵌入。在将序列提供给 Transformer 编码器的层之前,还会添加绝对位置嵌入。接下来,Transformer 文本解码器自回归地生成标记。

架构
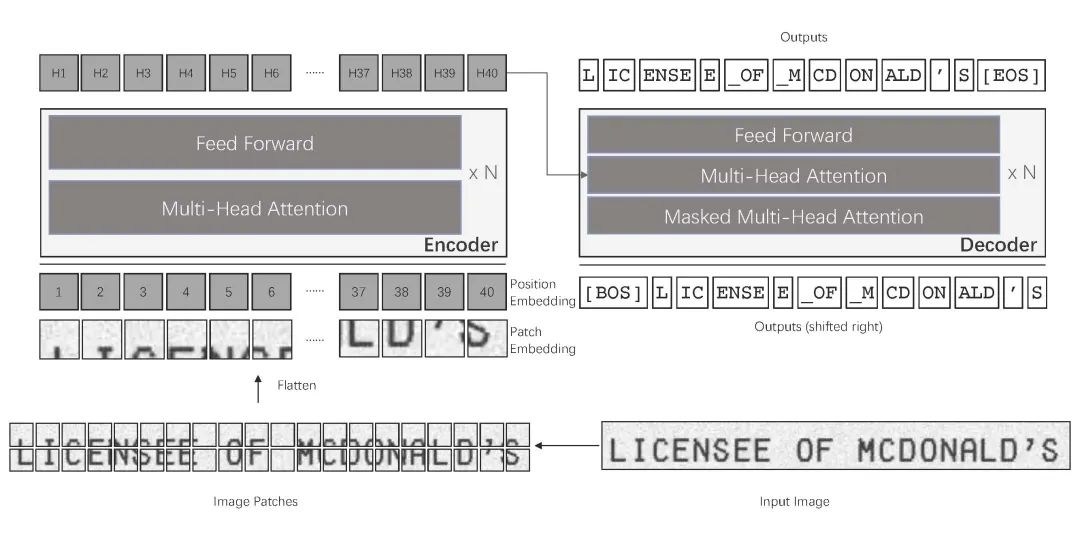
(TrOCR 架构,摘自原始论文)
模型设置
克隆存储库并确保已安装 conda 或 miniconda,然后进入克隆存储库的目录并运行以下命令:
conda env create -n trocr --file environment.yml
conda activate trocr
这将安装所有必要的库。
在没有 GPU 的情况下进行训练:
强烈建议使用 CUDA GPU,但也可以在 CPU 上完成所有操作。在这种情况下,请使用 environment-cpu.yml 文件进行安装。如果进程终止时出现警告 "killed",请减小批处理大小以适应工作内存。
使用存储库
有三种模式:推理(inference)、验证(validation)和训练(training)。它们三者都可以从正确路径中的本地模型开始(参见 src/constants/paths),也可以使用来自 Huggingface 的预训练模型。默认情况下,推理和验证使用本地模型,而训练则默认使用 Huggingface 模型。
· 推理(预测):
python -m src predict <image_files> # predict image files using the trained local model
python -m src predict data/img1.png data/img2.png # list all image files
python -m src predict data/* # also works with shell expansion
python -m src predict data/* --no-local-model # uses the pretrained huggingface model
· 验证:
python -m src validate # uses pretrained local model
python -m src validate --no-local-model # loads pretrained model from huggingface
· 训练:
python -m src train # starts with pretrained model from huggingface
python -m src train --local-model # starts with pretrained local model
对于验证和训练,输入图像应位于 train 和 val 目录中,标签应位于 gt/labels.csv 文件中。在 CSV 文件中,每一行应包括图像名称,然后以结束,例如 img1.png, a(如有必要,用引号括起来)。
如果要从其他位置读取标签也很简单。只需在 src/dataset.py 中的 load_filepaths_and_labels 函数中添加必要的代码。
要选择训练数据的子样本作为验证数据,可以使用以下命令:
find train -type f | shuf -n <num of val samples> | xargs -I '{}' mv {} val
集成到其他项目中
如果您想将预测结果作为更大项目的一部分使用,可以直接使用 main 中 TrocrPredictor 提供的接口。为此,请确保以 Python 模块的形式运行所有代码。
以下是代码示例:
from PIL import Image
from trocr.src.main import TrocrPredictor
# load images
image_names = ["data/img1.png", "data/img2.png"]
images = [Image.open(img_name) for img_name in image_names]
# directly predict on Pillow Images or on file names
model = TrocrPredictor()
predictions = model.predict_images(images)
predictions = model.predict_for_file_names(image_names)
# print results
for i, file_name in enumerate(image_names):
print(f'Prediction for {file_name}: {predictions[i]}')
调整代码
通常情况下,应该很容易调整代码以适应其他输入格式或用例。学习率、批量大小、训练周期数、日志记录、单词长度:src/configs/constants.py输入路径、模型检查点路径:src/configs/paths.py不同的标签格式:src/dataset.py:load_filepaths_and_labels单词长度常量非常重要。为了方便批量训练,所有标签都需要填充到相同的长度。可能需要进行一些实验。对我们来说,填充到 8 的长度效果很好。
如果要更改模型的特定内容,可以向 transformers 接口提供一个 TrOCRConfig 对象。有关更多详细信息,请参阅 https://huggingface.co/docs/transformers/model_doc/trocr#transformers.TrOCRConfig
项目链接
https://github.com/rsommerfeld/trocr#training-without-gpu
关注「开源AI项目落地」公众号










