
MLX-GPT2:在Apple Silicon上运行和训练GPT-2模型
GPT-2是由OpenAI开发的大型语言模型,以其强大的自然语言生成能力而闻名。然而,运行和训练如此庞大的模型通常需要昂贵的GPU资源。MLX-GPT2项目为此提供了一个创新的解决方案,让Mac用户也能在自己的设备上体验GPT-2的魅力。
项目概述
MLX-GPT2是一个使用Apple的新机器学习框架MLX重新实现的GPT-2项目。它允许用户在配备Apple silicon芯片的Mac设备上运行OpenAI的15亿参数GPT-2模型,或者从头开始训练自定义的GPT风格模型。
这个项目的主要特点包括:
- 完全使用MLX框架实现,充分利用Apple silicon的性能
- 可以运行OpenAI原版的15亿参数GPT-2模型
- 支持从头训练自定义的GPT模型
- 在MacBook Pro上可以实现实时文本生成
安装和使用
要使用MLX-GPT2,你需要一台搭载Apple silicon芯片的Mac设备。安装步骤如下:
- 创建并激活虚拟环境
- 安装依赖项:
pip install -r requirements.txt - 下载预训练的GPT-2模型权重
- 将PyTorch模型权重转换为MLX格式:
python convert_weights.py --weights_path="path/to/pytorch_model.bin" --model_name="gpt2-xl" - 生成文本:
python generate.py --model_name="gpt2-xl" --prompt "In a shocking finding, scientists discovered a herd of unicorns"
模型架构
MLX-GPT2完整实现了GPT-2的神经网络架构,主要包括以下几个部分:
- 输入嵌入层:将token ID映射为向量表示
- 位置编码:为每个token添加位置信息
- 自注意力机制:允许token之间交换信息
- 多头注意力:并行使用多个注意力头,学习更复杂的表示
- 前馈神经网络:进一步处理注意力的输出
- Layer Normalization:用于训练稳定性
整个模型由多个这样的Transformer块堆叠而成,形成了一个强大的语言模型。
训练自定义模型
MLX-GPT2不仅可以运行预训练模型,还支持用户训练自己的GPT风格模型。训练步骤如下:
- 准备训练数据,保存为文本文件
- 预处理和tokenize文本数据:
python prepare_data.py --data_path="path/to/train.txt" - 开始训练:
python train.py --data_path="path/to/train.npy" --checkpoint_dir="path/to/save/checkpoints"
训练脚本采用了批量加载数据的方式,避免将整个数据集加载到内存。同时也实现了梯度累积,允许训练更大的模型和使用更大的批量大小。
性能展示
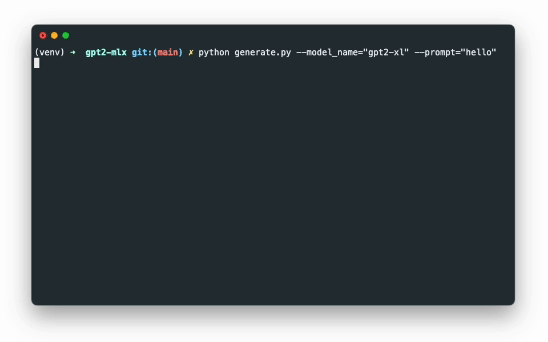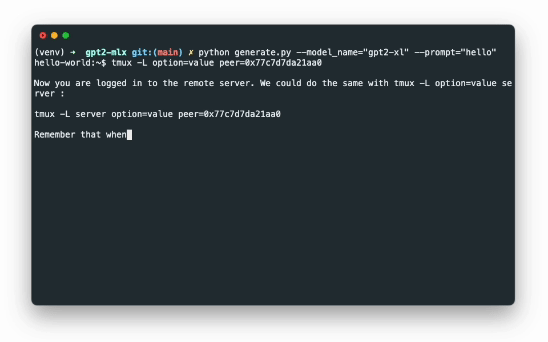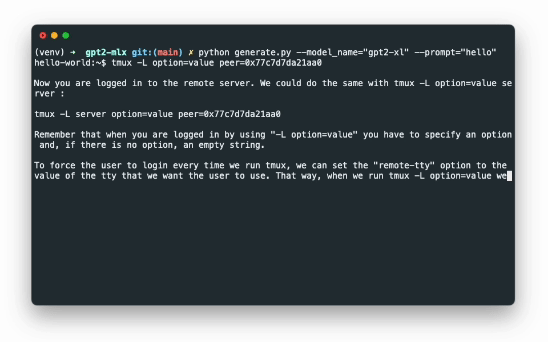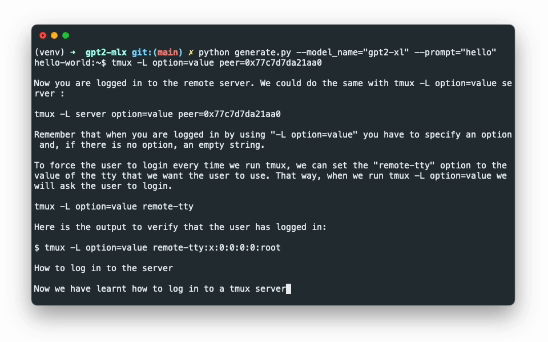
上图展示了GPT-2 XL(15亿参数)模型在配备16GB内存的M1 Pro芯片MacBook上进行实时文本生成的过程。可以看到,即使是如此庞大的模型,在Apple silicon上也能实现流畅的生成效果。
技术细节
MLX-GPT2的实现涉及多个复杂的技术细节,这里简要介绍几个关键点:
- 输入嵌入:使用查找表将token ID映射为向量表示。
- 位置编码:为每个token添加位置信息,使模型能够理解序列中的相对位置。
- 自注意力机制:通过计算token之间的相似度,允许信息在序列中流动。
- 多头注意力:并行使用多个注意力头,每个头学习不同的投影和注意力权重。
- 前馈神经网络:在注意力层之后进一步处理信息。
- Layer Normalization和残差连接:用于提高训练稳定性和模型性能。
这些技术的精妙结合,使得GPT-2能够理解复杂的语言结构并生成连贯的文本。
结语
MLX-GPT2项目为Mac用户提供了一个强大的工具,让他们能够在自己的设备上运行和训练大型语言模型。无论是研究人员、开发者还是AI爱好者,都可以利用这个项目深入探索GPT-2模型的潜力。随着Apple silicon芯片的不断发展,我们可以期待在未来看到更多令人兴奋的本地AI应用。
欢迎访问MLX-GPT2 GitHub仓库了解更多细节,并亲身体验GPT-2在Mac上的魅力!


















