
大规模多模态预训练模型综述:技术进展与未来展望
近年来,随着深度学习技术的快速发展和计算能力的不断提升,大规模预训练模型在自然语言处理、计算机视觉等领域取得了巨大成功。受此启发,研究人员开始将注意力转向多模态预训练模型,希望通过融合文本、图像、语音等多种模态信息,构建更加通用和强大的人工智能系统。本文将全面综述大规模多模态预训练模型的最新研究进展,探讨其关键技术和未来发展方向。
1. 多模态预训练模型概述
多模态预训练模型旨在通过大规模无监督学习,同时对多种模态数据进行建模,从而获得跨模态的通用表示。与单模态预训练模型相比,多模态模型能够更好地捕捉不同模态之间的语义关联,提升模型的泛化能力和下游任务性能。
典型的多模态预训练模型架构通常包括以下几个关键组件:
-
单模态编码器:负责对各个模态的输入数据进行特征提取,如文本编码器、图像编码器等。
-
跨模态融合模块:实现不同模态特征的交互和融合,常用的方法包括注意力机制、跨模态Transformer等。
-
预训练目标:定义模型在预训练阶段需要优化的任务,如掩码语言建模、图像-文本匹配等。
-
下游任务适配层:用于将预训练模型应用于特定的下游任务。

2. 预训练方法与技术
多模态预训练模型的成功很大程度上依赖于有效的预训练方法。目前常用的预训练技术主要包括:
-
掩码语言建模(MLM):随机遮蔽输入文本中的部分词,让模型预测被遮蔽的词。
-
图像-文本匹配(ITM):判断给定的图像和文本是否语义匹配。
-
视觉问答(VQA):根据图像内容回答相关问题。
-
图像描述生成:生成描述给定图像内容的文本。
-
跨模态对比学习:拉近语义相关的跨模态样本表示,推开无关样本。
这些预训练任务的设计旨在让模型学习到不同模态之间的语义对应关系,从而获得更好的跨模态理解能力。
3. 代表性模型与进展
近年来涌现了大量优秀的多模态预训练模型,以下列举几个具有代表性的工作:
-
CLIP:通过大规模图像-文本对比学习,实现了零样本图像分类等任务的突破。
-
DALL-E:基于GPT-3架构,能够根据文本描述生成高质量图像。
-
Flamingo:结合了视觉和语言大模型,在各种视觉-语言任务上表现出色。
-
PaLM-E:将大规模语言模型与视觉和机器人控制相结合,展现了强大的多模态理解和决策能力。
这些模型在模型规模、训练数据、架构设计等方面都有各自的创新,推动了多模态预训练技术的快速发展。
4. 下游任务与应用
多模态预训练模型可以应用于广泛的下游任务,主要包括:
-
视觉-语言理解:如视觉问答、图像描述、视觉常识推理等。
-
跨模态检索:实现图像-文本双向检索。
-
多模态生成:如文本引导的图像生成、视频生成等。
-
多模态对话:支持图像、视频等多模态输入的智能对话系统。
-
机器人控制:结合视觉和语言信息进行机器人动作规划和控制。
这些应用展现了多模态预训练模型强大的跨模态理解和生成能力,为人工智能系统的发展开辟了新的方向。
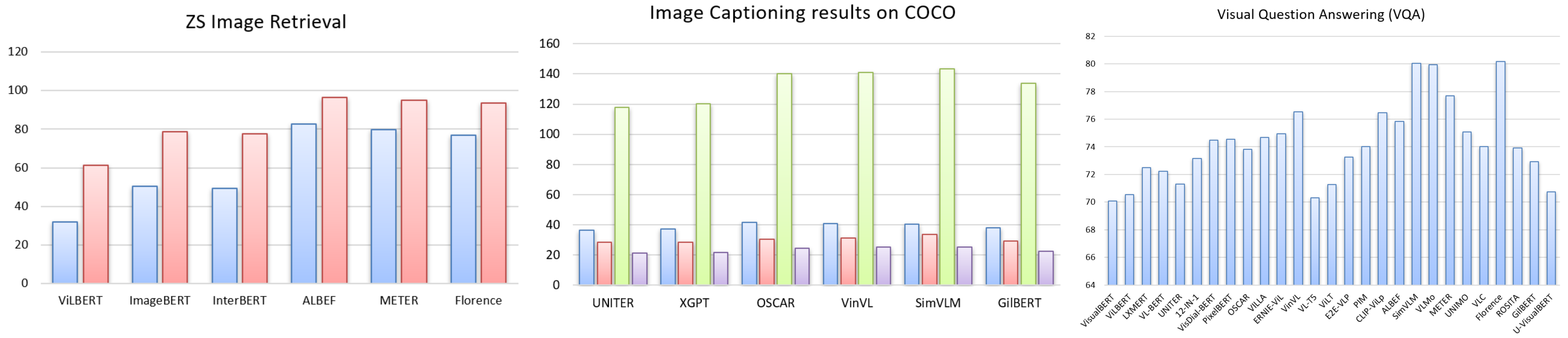
5. 挑战与未来方向
尽管多模态预训练模型取得了显著进展,但仍面临诸多挑战,主要包括:
-
模型效率:随着模型规模不断增大,如何提高训练和推理效率成为亟需解决的问题。
-
数据质量:大规模多模态数据的收集和清洗仍然是一项艰巨的任务。
-
模态对齐:如何更好地对齐不同模态之间的语义信息仍有待深入研究。
-
鲁棒性与可解释性:提高模型的鲁棒性和可解释性对于实际应用至关重要。
-
伦理与安全:大规模模型的潜在偏见和滥用问题需要得到重视。
未来的研究方向可能包括:
-
发展更高效的模型架构和训练方法。
-
探索自监督和弱监督学习技术,减少对标注数据的依赖。
-
设计更加通用的预训练任务,提升模型的迁移学习能力。
-
结合神经符号方法,增强模型的推理能力和可解释性。
-
研究模型压缩和知识蒸馏技术,降低部署成本。
6. 总结
大规模多模态预训练模型为人工智能系统的发展开辟了新的道路,展现出广阔的应用前景。通过融合不同模态的信息,这些模型能够更好地理解和生成复杂的多模态内容,为构建通用人工智能奠定了基础。随着技术的不断进步和挑战的逐步克服,我们有理由相信,多模态预训练模型将在未来的人工智能研究和应用中发挥越来越重要的作用。
参考文献
-
Wang, X., Chen, G., Qian, G., Gao, P., Wei, X. Y., Wang, Y., ... & Gao, W. (2022). Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey. arXiv preprint arXiv:2302.10035.
-
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021). Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR.
-
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., ... & Sutskever, I. (2021). Zero-shot text-to-image generation. In International Conference on Machine Learning (pp. 8821-8831). PMLR.
-
Alayrac, J. B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., ... & Zisserman, A. (2022). Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35, 23716-23736.
-
Driess, D., Xia, F., Sajjadi, M. S., Lynch, C., Chowdhery, A., Ichter, B., ... & Schölkopf, B. (2023). PaLM-E: An Embodied Multimodal Language Model. arXiv preprint arXiv:2303.03378.










