PiSSA:大型语言模型的主成分奇异值和奇异向量自适应方法
在人工智能和自然语言处理领域,大型语言模型(Large Language Models, LLMs)的微调一直是一个热门且具有挑战性的研究方向。随着模型规模的不断增大,如何在有限的计算资源下高效地对这些模型进行微调成为了一个亟待解决的问题。近期,由GraphPKU团队提出的PiSSA(Principal Singular values and Singular vectors Adaptation)方法为这一问题提供了一个创新的解决方案。
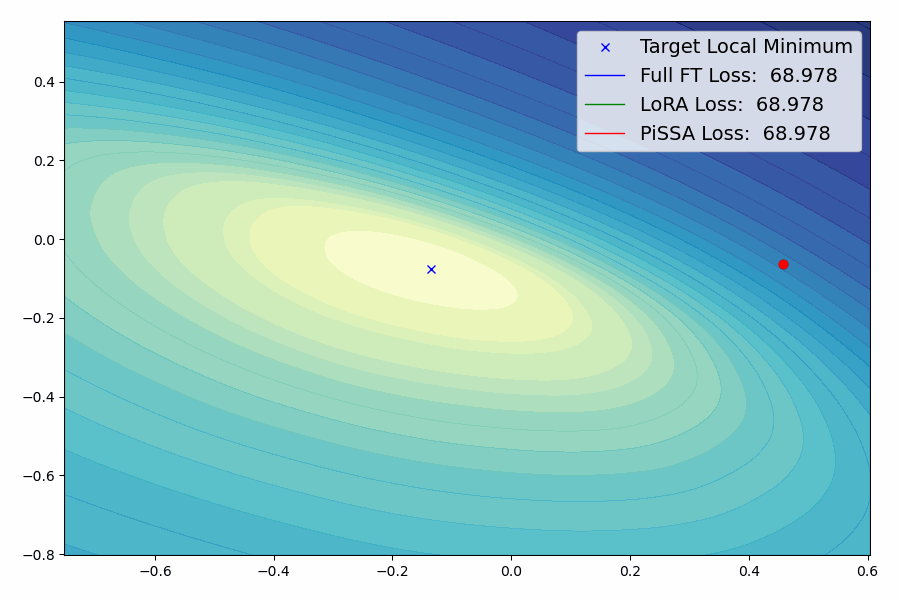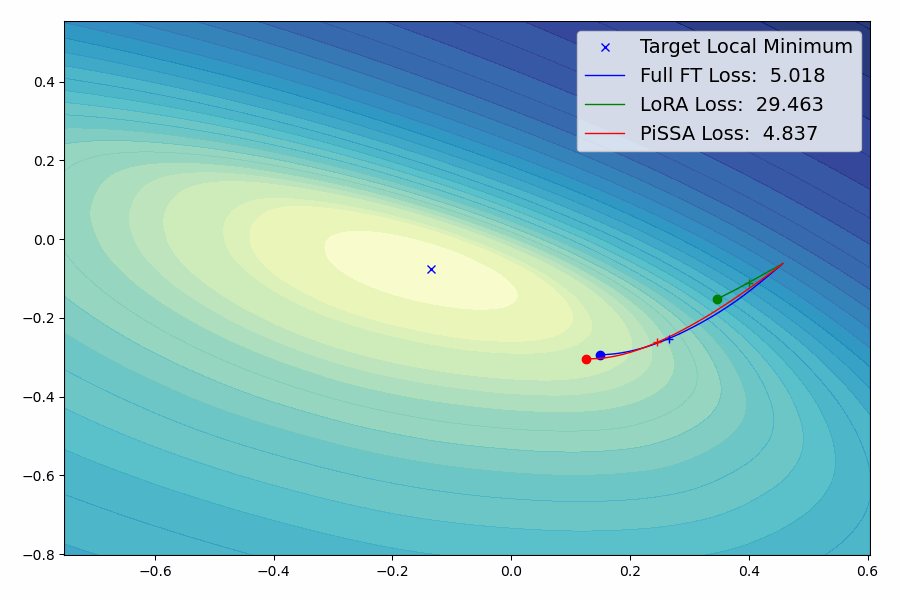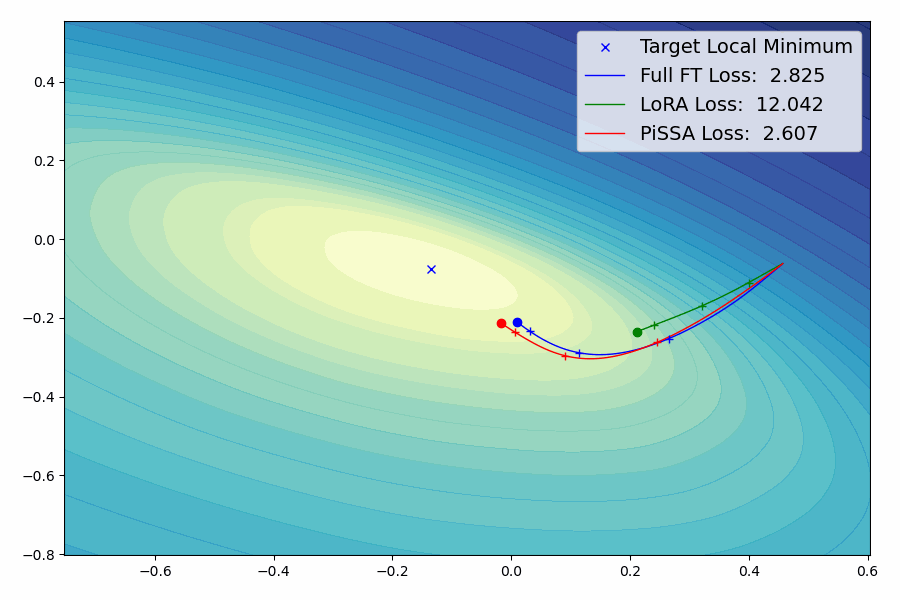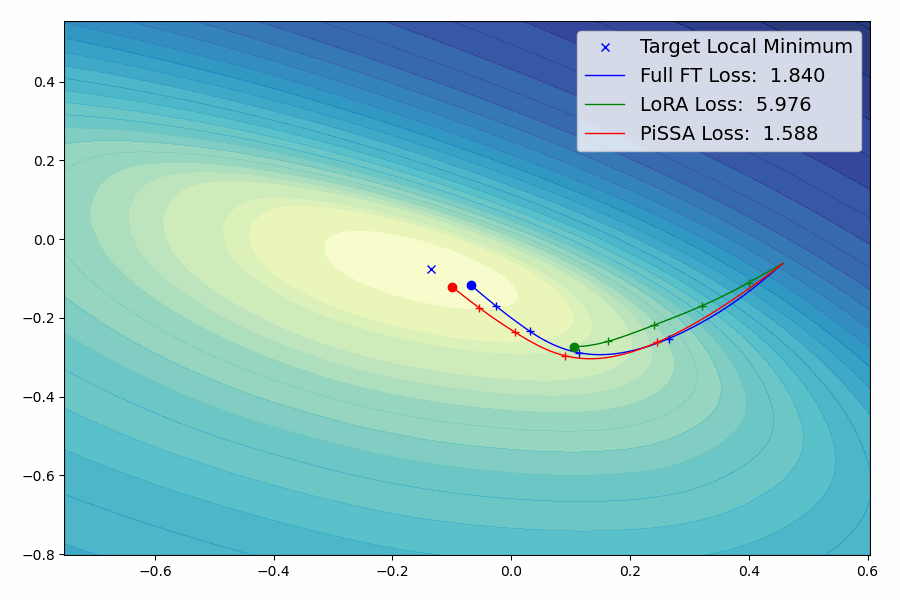
PiSSA的核心思想
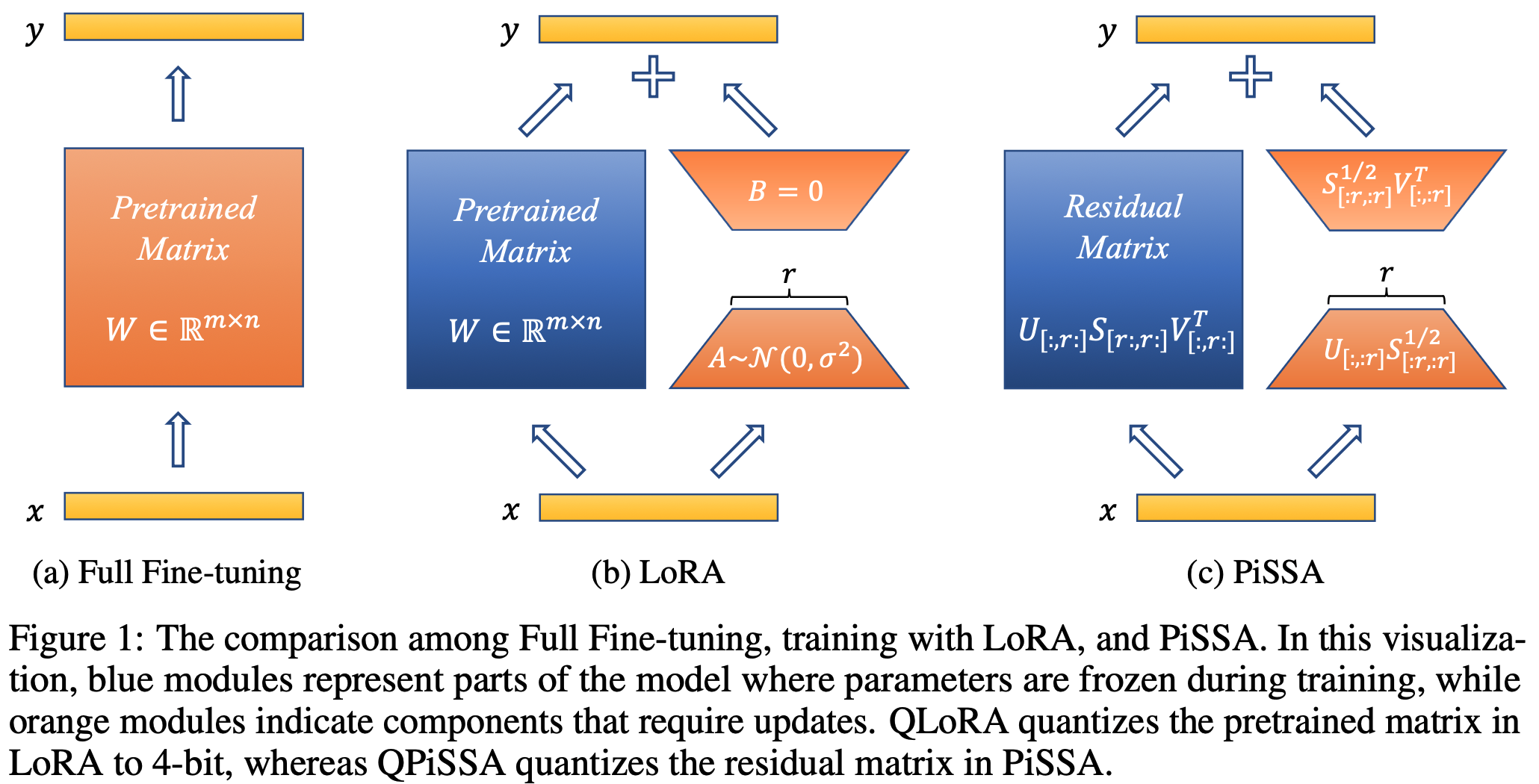
PiSSA是一种参数高效的微调(Parameter-Efficient Fine-Tuning, PEFT)方法。与传统的LoRA(Low-Rank Adaptation)方法不同,PiSSA聚焦于优化模型中最重要的部分 - 主要奇异值和奇异向量,同时冻结那些"噪声"部分。这种方法的核心思想是:
- 对原始模型矩阵进行奇异值分解(SVD)
- 将主要的奇异值和奇异向量作为初始化参数
- 在微调过程中只更新这些主要成分,而保持其他部分不变
这种方法的优势在于:
- 更快的收敛速度:由于直接优化模型中最重要的部分,PiSSA能够更快地达到理想的性能水平。
- 更好的最终性能:通过专注于主要成分,PiSSA能够在微调后达到更高的精度。
- 与量化技术兼容:PiSSA保持了与LoRA相同的架构,因此同样可以与模型量化技术结合使用。
PiSSA的实验结果
研究团队在多个基准测试中对PiSSA进行了全面的评估。结果表明,PiSSA在各项测试中都取得了显著的性能提升:
-
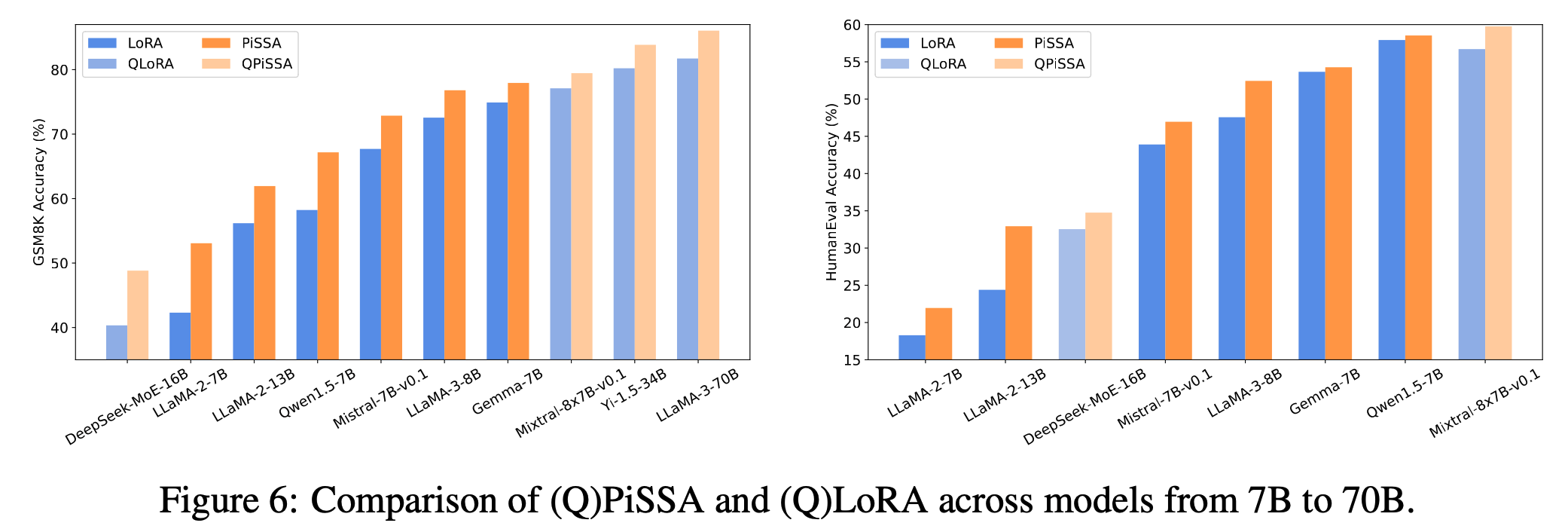
GSM8K数学推理任务:
- Mistral-7B模型使用PiSSA微调后,准确率达到72.86%
- 相比之下,使用LoRA微调的准确率为67.7%
- PiSSA实现了5.16%的性能提升
-
与量化技术结合:
- 在LLaMA 2-7B模型上,PiSSA将4位量化误差减少了18.97%
- 在GSM8K任务中,QPiSSA(结合4位量化的PiSSA)达到49.13%的准确率
- 明显优于QLoRA的39.8%和LoftQ的40.71%
-
大规模模型测试:
- 在LLaMA-3-70B模型上的GSM8K任务中,QPiSSA达到86.05%的准确率
- 显著超过了QLoRA的81.73%的表现
PiSSA的技术细节
PiSSA的实现基于以下几个关键点:
-
快速SVD技术:PiSSA使用了一种高效的SVD算法,使得整个初始化过程仅需几秒钟,大大降低了从LoRA切换到PiSSA的成本。
-
与LoRA相同的架构:这意味着PiSSA可以无缝集成到现有的使用LoRA的工作流程中。
-
灵活的rank选择:PiSSA支持不同的rank设置(如r16, r32, r64, r128),允许用户根据具体需求在性能和效率之间进行权衡。
-
广泛的模型支持:PiSSA已在多个主流大语言模型上进行了测试,包括LLaMA系列、Qwen2系列等。
PiSSA的实际应用
PiSSA不仅在理论上展现了优势,在实际应用中也表现出色:
-
模型微调:研究人员和开发者可以使用PiSSA来快速、高效地微调大型语言模型,以适应特定的任务或领域。
-
资源受限场景:在计算资源有限的情况下,PiSSA提供了一种优化模型性能的有效方法。
-
量化模型优化:结合模型量化技术,PiSSA可以在保持模型性能的同时,大幅减少模型的存储和计算需求。
-
快速原型开发:由于PiSSA的快速收敛特性,它特别适合于需要快速迭代和实验的场景。
PiSSA的未来发展
随着PiSSA的发布,它已经引起了学术界和工业界的广泛关注。未来,PiSSA可能在以下几个方面继续发展:
-
更广泛的模型支持:扩展到更多类型的神经网络模型,如视觉transformer等。
-
与其他技术的结合:探索与其他先进的微调和优化技术的结合可能性。
-
自动化工具:开发自动化工具,使得PiSSA的应用更加简单和直观。
-
理论研究:深入研究PiSSA的理论基础,为进一步改进提供依据。
结论
PiSSA作为一种新型的参数高效微调方法,为大型语言模型的优化提供了一个强大的工具。通过聚焦于模型的主要成分,PiSSA实现了更快的收敛速度和更好的性能。它不仅在多个基准测试中展现了卓越的表现,还为资源受限的场景提供了一个实用的解决方案。随着人工智能技术的不断发展,PiSSA有望在未来的语言模型优化中发挥更加重要的作用。
对于那些希望提高模型性能、加速微调过程或在有限资源下优化大型语言模型的研究者和开发者来说,PiSSA无疑是一个值得尝试的方法。它不仅提供了性能上的提升,还保持了与现有工作流程的兼容性,使得其应用变得相对简单和直接。随着更多的实践和研究,我们有理由相信PiSSA将在大语言模型优化领域占据重要地位。