
 Github
Github 论文
论文Pri主奇异值和奇异向量S适应
引言
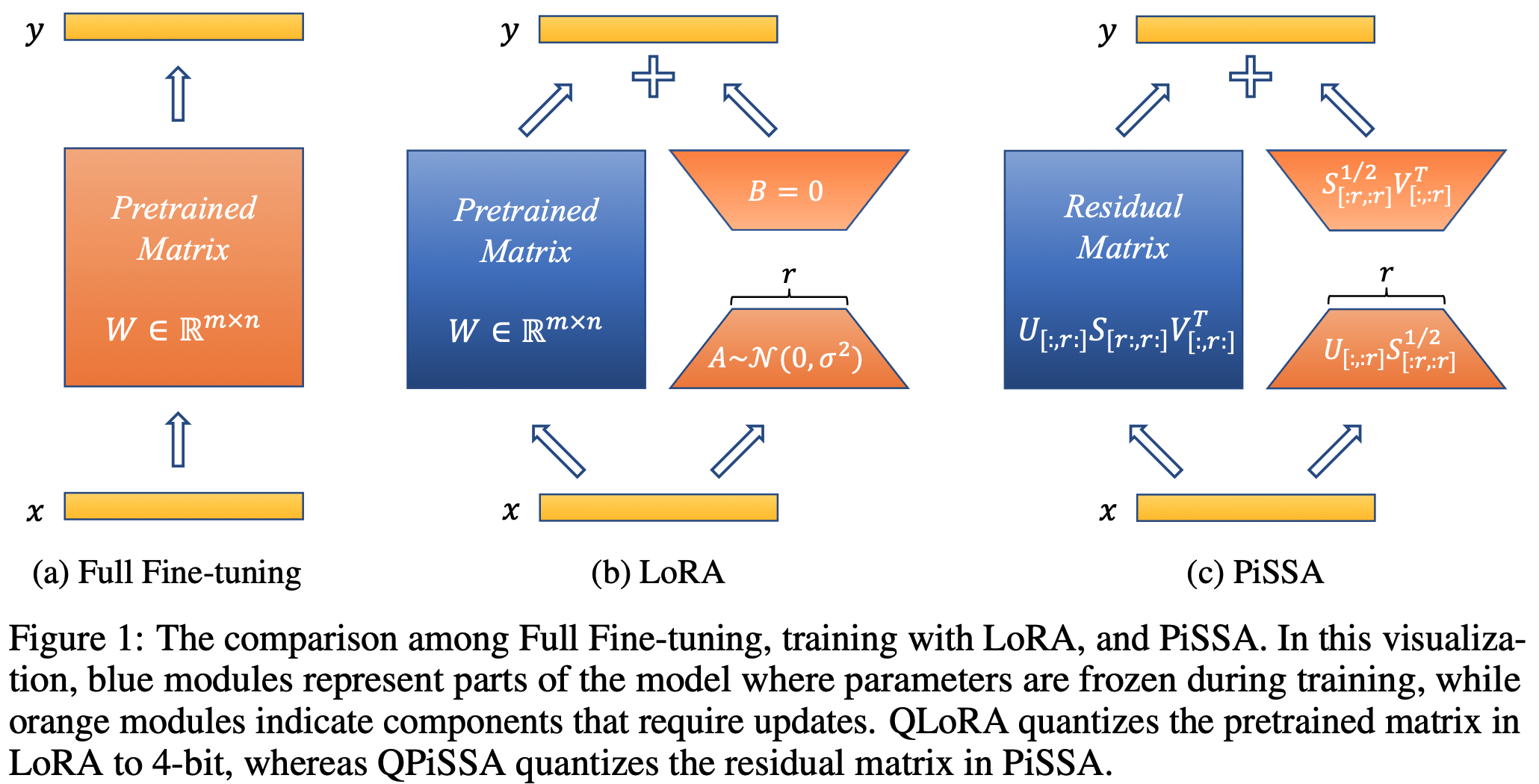
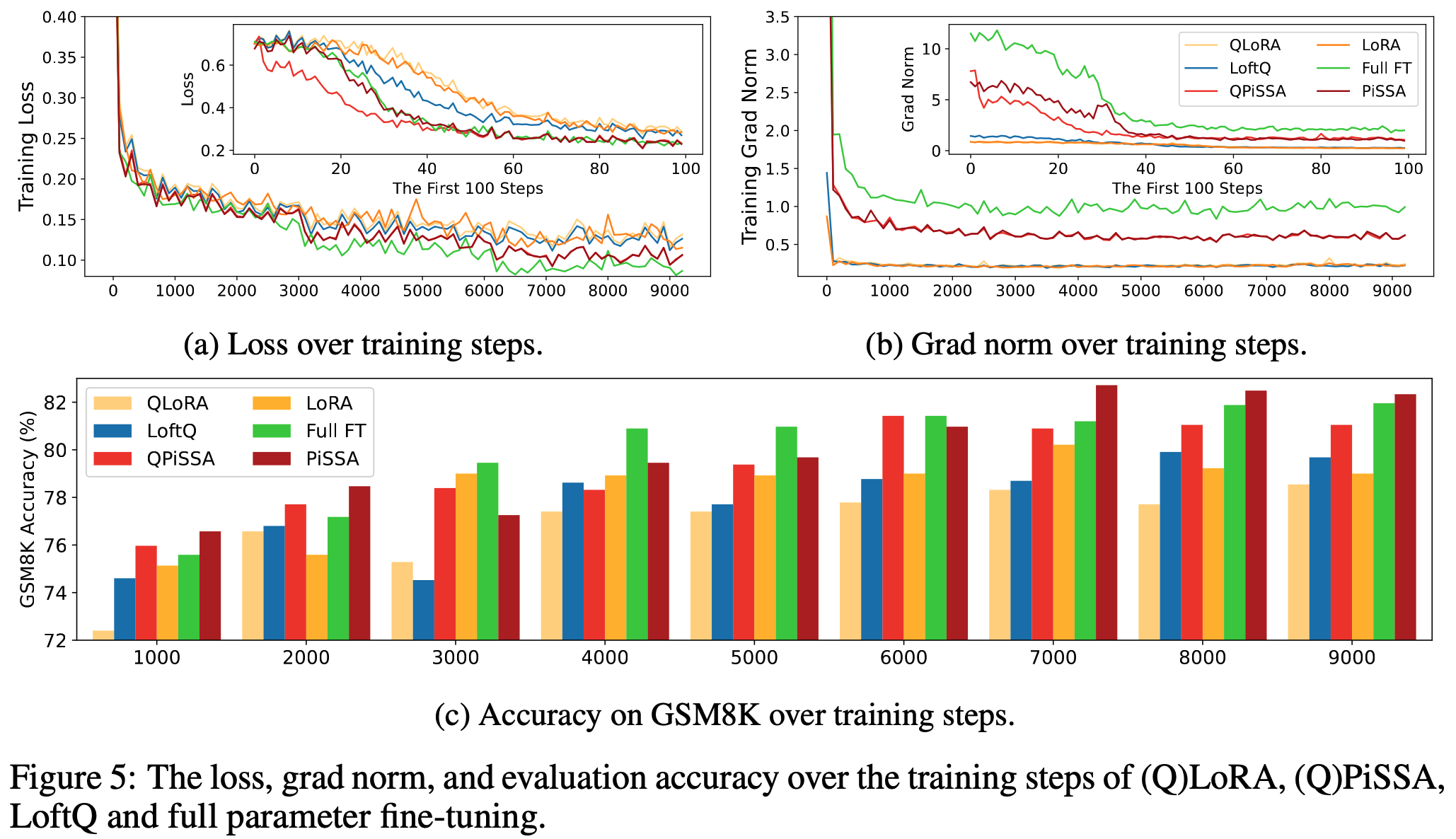
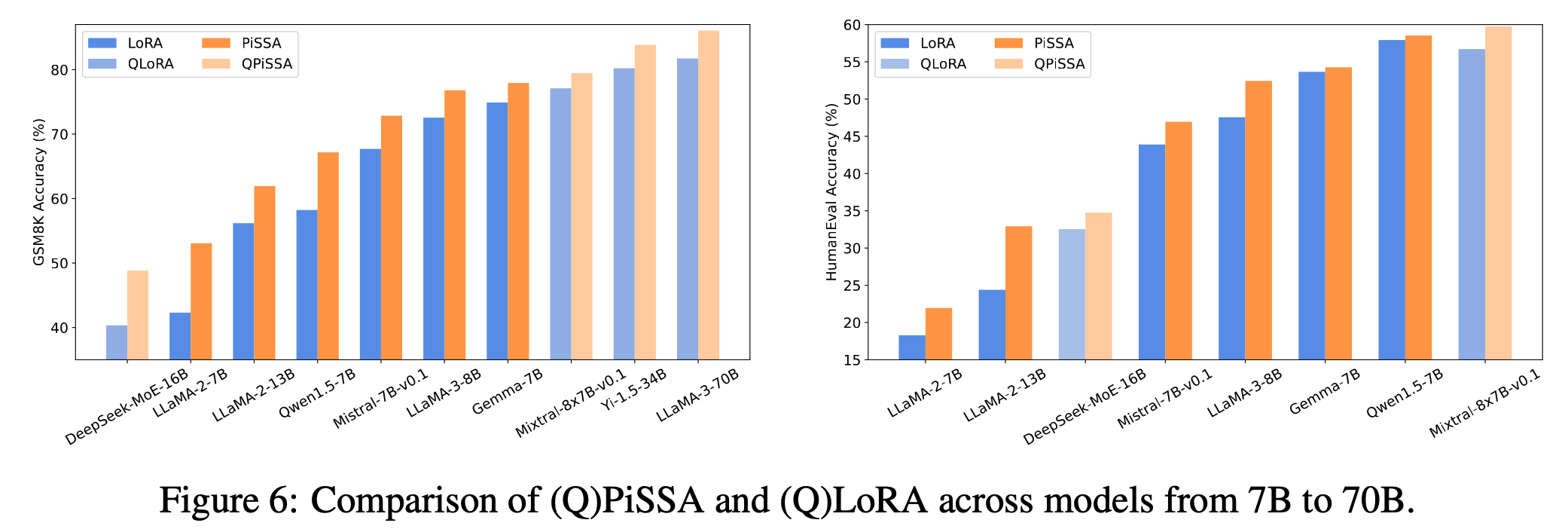
我们提出了一种参数高效的微调(PEFT)方法,称为Pri主奇异值和奇异向量A适应(PiSSA),该方法优化关键的奇异值和向量,同时冻结"噪声"部分。相比之下,LoRA冻结原始矩阵并更新"噪声"。这种区别使得PiSSA能够比LoRA收敛得更快,并最终获得更好的性能。在五个常见的基准测试中,PiSSA在使用完全相同的设置(除了不同的初始化)的情况下,在所有测试中都优于LoRA。在GSM8K上,使用PiSSA微调的Mistral-7B达到了72.86%的准确率,比LoRA的67.7%高出5.16%。 由于架构相同,PiSSA继承了LoRA的许多优点,如参数效率和与量化的兼容性。 此外,PiSSA将LLaMA 2-7B的4位量化误差减少了18.97%,显著提高了微调性能。在GSM8K基准测试中,PiSSA达到了49.13%的准确率,超过了QLoRA的39.8%和LoftQ的40.71%。 利用快速SVD技术,PiSSA的初始化只需几秒钟,将LoRA切换到PiSSA的成本几乎可以忽略不计。
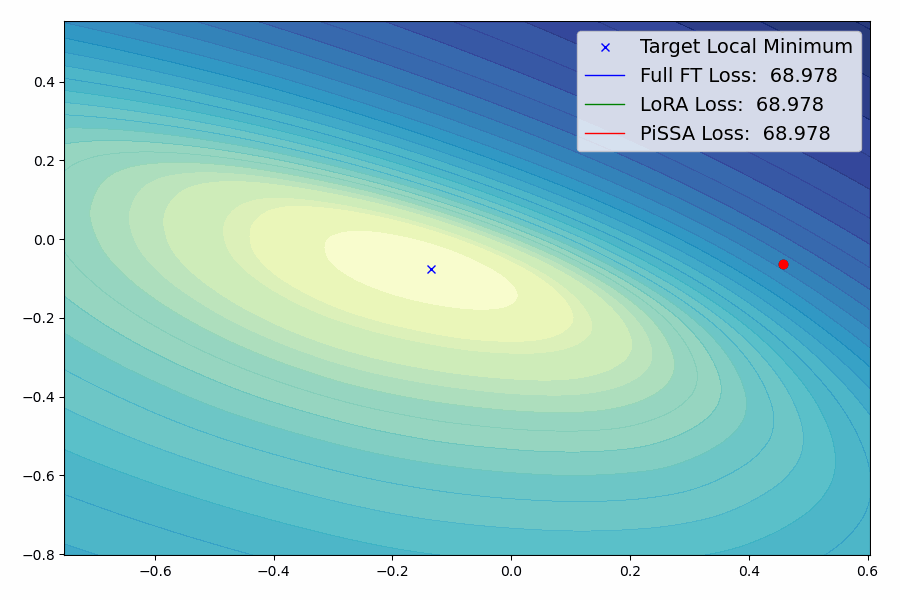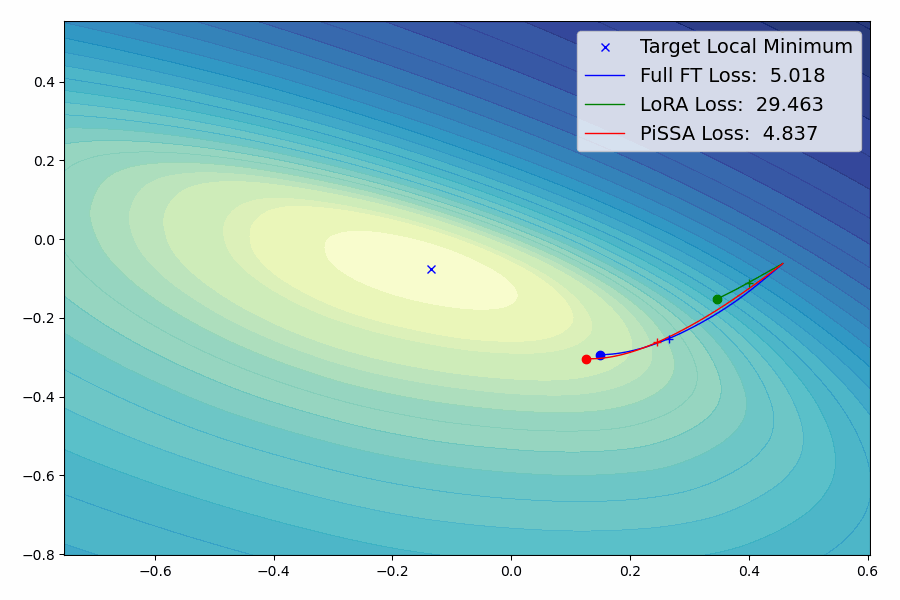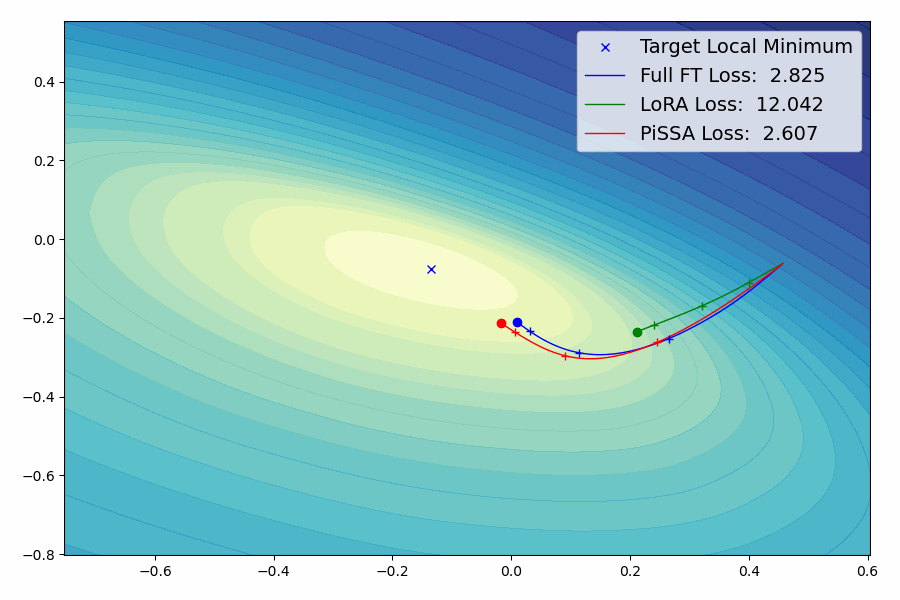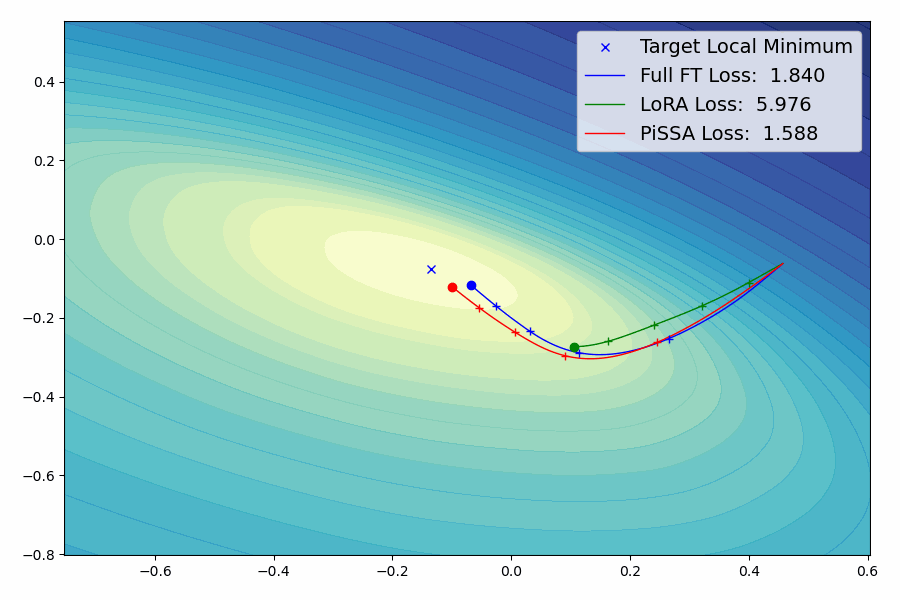
新闻
- [2024.07.17] PiSSA现在支持Conv2d和Embedding,这里是在SDXL上使用PiSSA的示例。
- [2024.07.16] PiSSA现在支持deepspeed。
- [2024.05.16] PiSSA已被合并到peft的主分支中,作为LoRA的可选初始化方法。
快速开始
通过pip安装PiSSA:
conda create -n pissa python=3.10
conda activate pissa
conda install nvidia/label/cuda-12.1.0::cuda-toolkit
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
复现结果
我们使用的所有数据集都可以在数据集公开获取。
PiSSA初始化的模型在模型上共享,以便于重复使用。它们保留了与原始模型相同的输入和输出,但被分为残差模型和PiSSA适配器,以实现更有效的微调。
| PiSSA | QPiSSA | |
|---|---|---|
| LLaMA-2-7B | r128 | r16,32,64,128 |
| LLaMA-3-8B | r16,32,64,128 | r64,128 |
| LLaMA-3-8B-Instruct | r16,32,64,128 | -- |
| LLaMA-3-70B | -- | r64,128 |
| LLaMA-3-70B-Instruct | -- | r128 |
| Qwen2-7B | r128 | r128 |
| Qwen2-7B-Instruct | r128 | r128 |
| Qwen2-72B | -- | r64,128 |
| Qwen2-72B-Instruct | -- | r64,128 |
训练
运行以下脚本将自动下载数据集和模型,然后开始训练:
sh scripts/run_full_finetune.sh
sh scripts/lora.sh
sh scripts/pissa.sh
sh scripts/loftq.sh
sh scripts/qlora.sh
sh scripts/qpissa.sh
评估
要评估您微调模型的性能,请按照fxmeng/pissa-evaluation-code中的说明进行操作。
高级用法
我们建议直接从Hugging Face Collections下载分解后的模型,而不是每次都执行SVD。 如果现有模型不能满足您的需求,可以对预训练模型应用PiSSA初始化,并将分解后的模型本地存储:
import torch
import os
from peft import LoraConfig, get_peft_model
from transformers import AutoTokenizer, AutoModelForCausalLM
MODEL_ID = "meta-llama/Llama-2-7b-hf"
model = AutoModelForCausalLM.from_pretrained(MODEL_ID, torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
tokenizer.pad_token_id = tokenizer.eos_token_id
lora_config = LoraConfig(
# init_lora_weights="pissa", # 将初始化方法配置为"pissa",这可能需要几分钟来对预训练模型执行SVD。
init_lora_weights="pissa_niter_4", # 使用快速SVD初始化PiSSA,只需几秒钟即可完成。
r=128,
lora_alpha=128,
lora_dropout=0, # 由于PiSSA适配器的组成部分是主要奇异值和向量,dropout应设置为0以避免随机丢弃。
target_modules=["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj"],
task_type="CAUSAL_LM",
)
peft_model = get_peft_model(model, lora_config)
peft_model.print_trainable_parameters()
OUTPUT_DIR="PiSSA-Llama-2-7b-hf-r128"
# 保存PiSSA模块:
peft_model.peft_config["default"].init_lora_weights = True # 重要
peft_model.save_pretrained(os.path.join(OUTPUT_DIR, "pissa_init"))
# 保存残差模型:
peft_model = peft_model.unload()
peft_model.save_pretrained(OUTPUT_DIR)
# 保存分词器:
tokenizer.save_pretrained(OUTPUT_DIR)
加载预处理过的模型并在IMDB数据集上进行微调:
from trl import SFTTrainer
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import PeftModel
MODEL_ID = "PiSSA-Llama-2-7b-hf-r128"
residual_model = AutoModelForCausalLM.from_pretrained(MODEL_ID,device_map="auto")
model = PeftModel.from_pretrained(residual_model, MODEL_ID, subfolder = "pissa_init", is_trainable=True)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
dataset = load_dataset("imdb", split="train[:1%]") # 仅使用1%的数据集
trainer = SFTTrainer(
model=peft_model,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=128,
tokenizer=tokenizer,
)
trainer.train()
peft_model.save_pretrained("pissa-llama-2-7b-ft")
将PiSSA转换为LoRA
使用peft_model.save_pretrained时,如果path_initial_model_for_weight_conversion=None,会保存微调后的矩阵$A$和$B$,应与残差模型结合使用。然而,当指定path_initial_model_for_weight_conversion="pissa_init_dir"时,保存函数会通过$\Delta W = A B - A_0 B_0 = [A | A_0] [B | -B_0]^T=A^{'}B^{'}$将PiSSA转换为LoRA。这种转换使得可以在标准基础模型之上加载LoRA:
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf", torch_dtype=torch.bfloat16, device_map="auto"
)
# 在此步骤中不执行SVD,基础模型保持不变。
peft_model = PeftModel.from_pretrained(model, "pissa-llama-2-7b-lora")
使用转换后的LoRA不需要修改基础模型的参数。当同时需要多个转换后的LoRA时,每个适配器独立运行而不会相互干扰,允许自由删除或添加适配器。
引用
@article{meng2024pissa,
title={Pissa: Principal singular values and singular vectors adaptation of large language models},
author={Meng, Fanxu and Wang, Zhaohui and Zhang, Muhan},
journal={arXiv preprint arXiv:2404.02948},
year={2024}
}
Star历史
后续工作
2024年5月27日, LoRA-XS: 使用极少参数的低秩适配 对主要奇异值和奇异向量进行基础适配。
2024年5月30日, SVFT: 使用奇异向量的参数高效微调 冻结奇异向量,同时以稀疏方式微调奇异值。
2024年6月3日, OLoRA: 大型语言模型的正交低秩适配, 利用QR分解进行正交矩阵初始化。
2024年6月7日, CorDA: 大型语言模型的上下文导向分解适配, 通过上下文导向分解利用知识保留适配和指令预览适配。
2024年6月7日, MiLoRA: 利用次要奇异分量进行参数高效的LLM微调, 次要奇异分量适配。
2024年6月18日, LaMDA: 通过谱分解的低维适配进行大型模型微调 对主要奇异值和奇异向量进行基础适配。
2024年7月6日, LoRA-GA: 具有梯度近似的低秩适配 在第一步对齐低秩矩阵乘积的梯度与全量微调的梯度。











