
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文
🏔️ K2 (GeoLLaMA) 地球科学大型语言模型
- 论文《K2:地球科学知识理解与应用的基础语言模型》已被WSDM2024(墨西哥)接收!
- 论文《K2:地球科学知识理解与应用的基础语言模型》的代码和数据
- 演示:https://k2.acemap.info 由我们自己在单个GeForce RTX 3090上通过内网穿透托管(仅使用三个线程,最大长度为512)
- 作为学术助手基础模型的更大型地球科学语言模型是geogalactica!
- 数据预处理工具包已在sciparser上开源!
简介
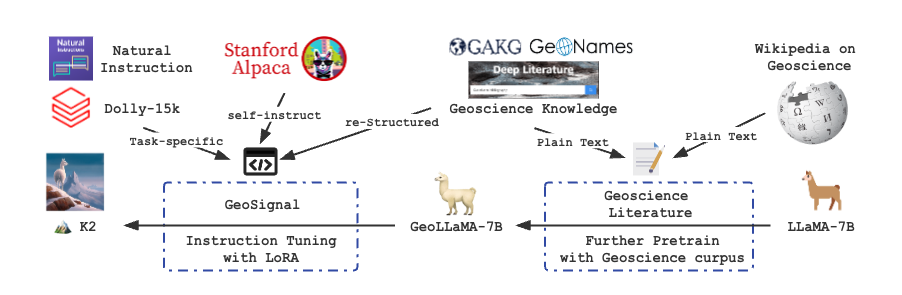
我们推出了K2(7B),这是一个开源语言模型,首先通过在收集和清理的地球科学文献(包括地球科学开放获取论文和维基百科页面)上进一步预训练LLaMA,然后使用知识密集型指令调优数据(GeoSignal)进行微调。初步评估中,我们使用GeoBench(包括地质学、地理学和环境科学的全国研究生入学考试和AP测试)作为基准。与具有相似参数的几个基线模型相比,K2在客观和主观任务上表现更优。 在本仓库中,我们将分享以下代码和数据。
- 我们以两部分发布K2权重(可以将我们的delta添加到原始LLaMA权重中,并使用
peft_model和transformers获得完整的K2模型。)- 在地球科学文本语料库上进一步预训练后的delta权重,以遵守LLaMA模型许可。
- 通过PEFT(LoRA)训练的适配器模型权重。
- 我们发布K2用于训练的GeoSignal核心数据。
- 我们发布GeoBench,这是首个用于评估LLMs在地球科学领域能力的基准。
- 我们发布K2进一步预训练和指令调优的代码。
以下是K2训练的概览:
快速开始
安装
1. 准备代码和环境
克隆我们的仓库,创建Python环境,并通过以下命令激活它
git clone https://github.com/davendw49/k2.git
cd k2
conda env create -f k2.yaml
conda activate k2
2. 准备预训练的K2(GeoLLaMA)
K2的当前版本在Hugging Face上 模型 K2的先前版本由两部分组成:delta模型(类似Vicuna),对LLaMA-7B的附加权重,以及适配器模型(通过PEFT训练)。
| Delta模型 | 适配器模型 | 完整模型 |
|---|---|---|
| k2_fp_delta | k2_it_adapter | k2_v1 |
- 参考Vicuna的仓库,我们分享构建K2预训练权重的命令
python -m apply_delta --base /path/to/weights/of/llama --target /path/to/weights/of/geollama/ --delta daven3/k2_fp_delta
使用Docker启动
即将推出...
3. 使用K2
base_model = /path/to/k2
tokenizer = LlamaTokenizer.from_pretrained(base_model)
model = LlamaForCausalLM.from_pretrained(
base_model,
load_in_8bit=load_8bit,
device_map=device_map
torch_dtype=torch.float16
)
model.config.pad_token_id = tokenizer.pad_token_id = 0
model.config.bos_token_id = 1
model.config.eos_token_id = 2
或者,也可以
base_model = /path/to/geollama
lora_weights = /path/to/adapter/model
tokenizer = LlamaTokenizer.from_pretrained(base_model)
model = LlamaForCausalLM.from_pretrained(
base_model,
load_in_8bit=load_8bit,
device_map=device_map
torch_dtype=torch.float16
)
model = PeftModel.from_pretrained(
model,
lora_weights,
torch_dtype=torch.float16,
device_map=device_map,
)
model.config.pad_token_id = tokenizer.pad_token_id = 0
model.config.bos_token_id = 1
model.config.eos_token_id = 2
- 更多详细信息在
./generation/目录中
数据
在本仓库中,我们分享了指令数据和基准数据:
- GeoSignal:
./data/geosignal/ - GeoBench:
./data/geobench/
进一步预训练
我们用于在LLaMA-7B上进行进一步预训练的文本语料库包含39亿个标记,这些标记来自于在地球科学领域选定的高质量期刊上发表的地球科学论文,主要由GAKG收集。
Hugging Face上的增量模型:daven3/k2_fp_delta
指令微调:GeoSignal
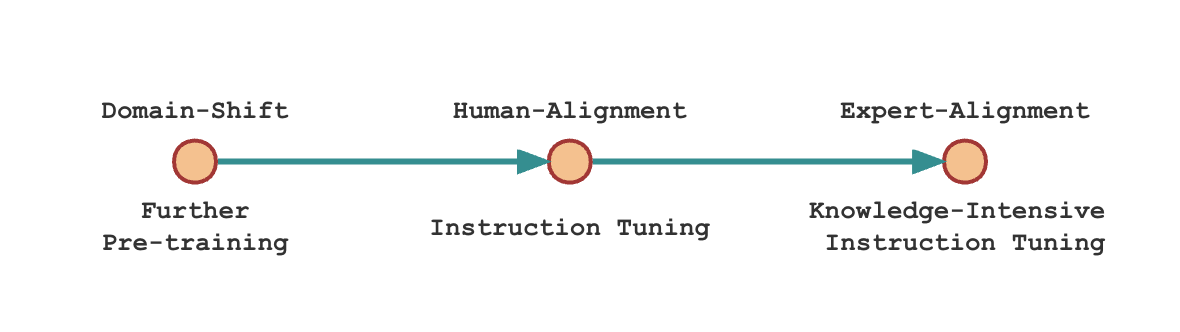
科学领域适应在指令微调过程中有两个主要步骤。
- 使用通用指令微调数据进行指令微调。这里我们使用Alpaca-GPT4。
- 使用重构的领域知识进行指令微调,我们称之为专业知识指令微调。对于K2,我们使用知识密集型指令数据GeoSignal。
以下是训练领域特定语言模型的配方示意图:
- Hugging Face上的适配器模型:daven3/k2_it_adapter
- Hugging Face上的数据集:geosignal
基准测试:GeoBench
在GeoBench中,我们收集了183个NPEE多选题和1,395个AP测试题作为客观任务。同时,我们收集了NPEE中所有939个主观问题作为主观任务集,并使用其中50个通过人工评估来衡量基线性能。
- Hugging Face上的数据集:geobench
代码
进一步预训练
训练脚本是**run_clm.py**
deepspeed --num_gpus=4 run_clm.py --deepspeed ds_config_zero.json >log 2>&1 &
我们使用的参数:
- 每个设备的批量大小:2
- 全局批量大小:128(2*4gpu*16梯度累积步骤)
- 可训练参数数量:6738415616(7b)
- 学习率:1e-5
- bf16:true
- tf32:true
- 预热:0.03/3 epoch(接近1000步)
- Zero_optimization_stage:3
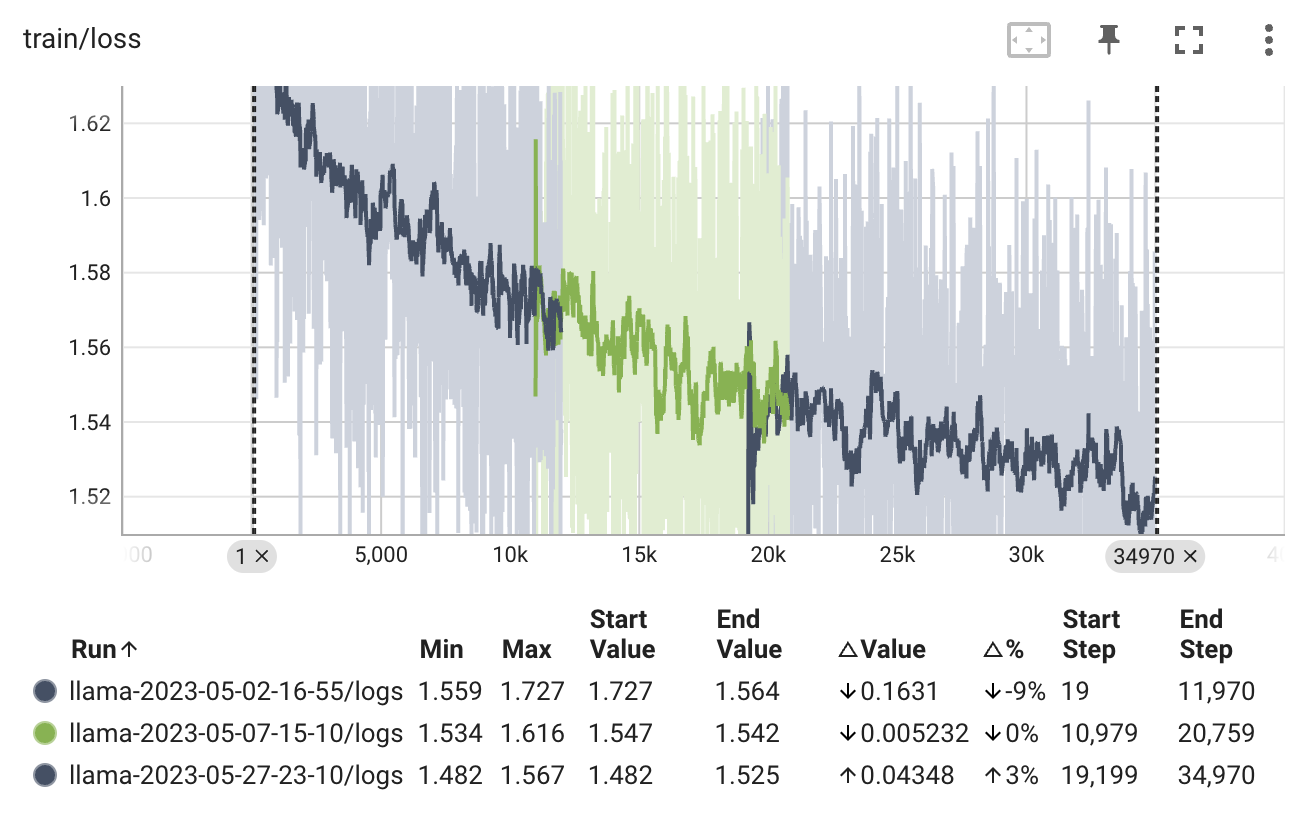
提示:由于计算能力有限,我们无法从检查点平滑恢复。因此,在恢复训练时我们没有加载优化器状态字典。尽管图表中有两个明显的峰值,但性能似乎保持正常。
指令微调
训练脚本是**finetune.py**
- 第一步:与人类对齐
python finetune.py --base_model /path/to/checkpoint-30140 --data_path /path/to/alpaca.json --output_dir /path/to/stage/one/model/ --cuda_id 2 --lora_target_modules "q_proj" "k_proj" "v_proj"
- 第二步:与专家对齐
python finetune.py --base_model /path/to/checkpoint-30140 --data_path /path/to/geosignal.json --output_dir /path/to/stage/two/model/ --cuda_id 2 --lora_target_modules "q_proj" "k_proj" "v_proj" --resume_from_checkpoint /path/to/stage/one/model/
- 批量大小:128
- 微批量大小:4
- 训练轮数:1
- 学习率:3e-4
- 截断长度:512
- 验证集大小:2000
- lora r:8
- lora alpha:16
- lora dropout:0.05
- lora 目标模块:["q_proj", "k_proj", "v_proj"]
案例
| 案例1 | 案例2 | 案例3 |
|---|---|---|
 |  |  |
-
回答:
- 问题: 什么是IOCG?
- 回答: 铁氧化物铜金(IOCG)矿床是一种由热液与火成岩相互作用形成的矿床类型。它们的特征是含有高浓度的铁氧化物、铜钼、金和铀矿物。通常,它们以脉状或角砾岩管的形式出现,但也可以在沉积岩和火山岩地层中以分散矿的形式存在。这些矿床的形成与岩浆侵入地壳有关,岩浆侵入会释放热量和压力,导致成矿元素从周围岩石中分离出来。IO
-
回答并解释:
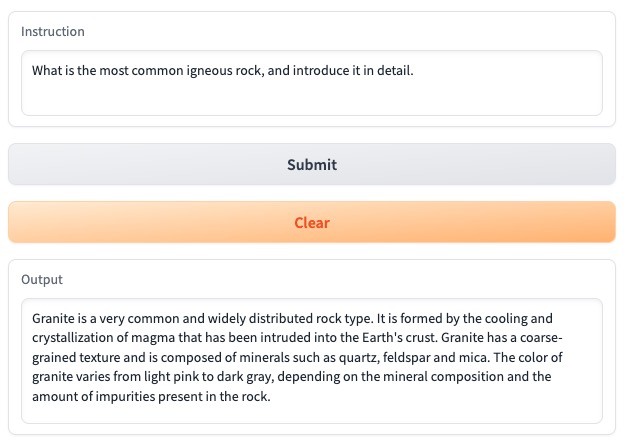
- 问题: 最常见的火成岩是什么,并详细介绍它。
- 回答: 花岗岩是一种非常常见且分布广泛的岩石类型。它是由侵入地壳的岩浆冷却结晶形成的。花岗岩具有粗粒结构,主要由石英、长石和云母等矿物组成。花岗岩的颜色从浅粉色到深灰色不等,取决于矿物成分和岩石中杂质的含量。
-
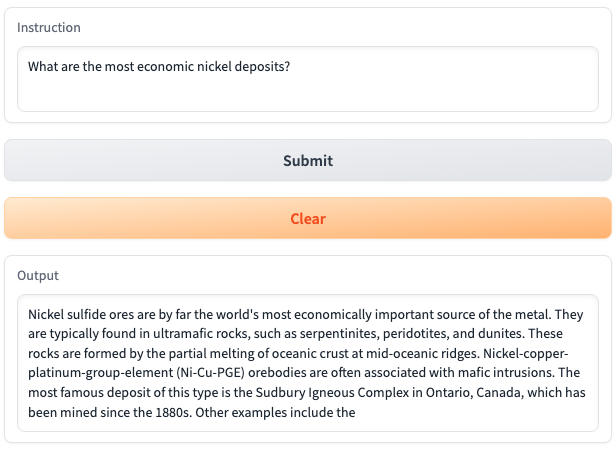
对比回答:
- 问题: 最具经济价值的镍矿床有哪些?
- 回答: 镍硫化物矿石是世界上最具经济价值的镍金属来源。它们通常存在于超镁铁质岩石中,如蛇纹岩、橄榄岩和纯橄榄岩。这些岩石是由大洋中脊处洋壳部分熔融形成的。镍-铜-铂族元素(Ni-Cu-PGE)矿体常与基性侵入岩相关。这类矿床中最著名的是加拿大安大略省的萨德伯里岩浆杂岩体,自19世纪80年代以来一直在开采。其他例子包括
评估
我们在evaluation文件夹中分享了原始评估代码,并将在不久的将来发布Geo-Eval,其中包含更多评估方法。
为什么命名为K2?
K2最初来源于世界第二高峰的名字,我们相信未来会有更大、更强大的地球科学语言模型被创造出来。此外,为了训练一个模型以适应具有显著领域壁垒的学科,我们遇到了许多困难(收集语料库、清理学术数据、计算能力等),这与攀登K2不亚于攀登珠穆朗玛峰的事实相似🏔️。
贡献者
该项目由上海交通大学Acemap团队创立,包括邓程、张天航、何中谋、陈琦元、施圆圆、周乐,由张伟男、傅洛毅、林舟涵、何俊贤和王新兵指导。整个项目得到了周成虎院士和中国科学院地理科学与资源研究所的支持。
致谢
K2参考了以下开源项目。我们要对这些项目的研究人员表示感谢和敬意。
- Facebook LLaMA:https://github.com/facebookresearch/llama
- Stanford Alpaca:https://github.com/tatsu-lab/stanford_alpaca
- alpaca-lora by @tloen:https://github.com/tloen/alpaca-lora
- alpaca-gp4 by Chansung Park:https://github.com/tloen/alpaca-lora/issues/340
K2得到了周成虎院士和中国科学院地理科学与资源研究所的支持。
许可证
K2是一个仅供非商业用途的研究预览版,受LLaMA模型许可证和OpenAI生成的数据使用条款的约束。如果您发现任何潜在的违规行为,请与我们联系。代码根据Apache许可证2.0发布。GeoSignal和GeoBench数据正在不断更新,如果您想订阅数据,可以发送电子邮件至davendw@sjtu.edu.cn。
引用 ArXiv
如果您使用K2的代码或数据,请使用以下引用:
@misc{deng2023learning,
title={K2: A Foundation Language Model for Geoscience Knowledge Understanding and Utilization},
author={Cheng Deng and Tianhang Zhang and Zhongmou He and Yi Xu and Qiyuan Chen and Yuanyuan Shi and Luoyi Fu and Weinan Zhang and Xinbing Wang and Chenghu Zhou and Zhouhan Lin and Junxian He},
year={2023},
eprint={2306.05064},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











