
DoRA: 权重分解的低秩适应
[ICML2024 (口头报告)]
DoRA: 权重分解的低秩适应 [ICML2024 (口头报告, 接受率: 1.5%)]的官方PyTorch实现。

刘世扬*、王建宜、尹宏旭、Pavlo Molchanov、王御橘、郑光廷、陈敏宏
(*在英伟达研究院实习期间完成的工作)
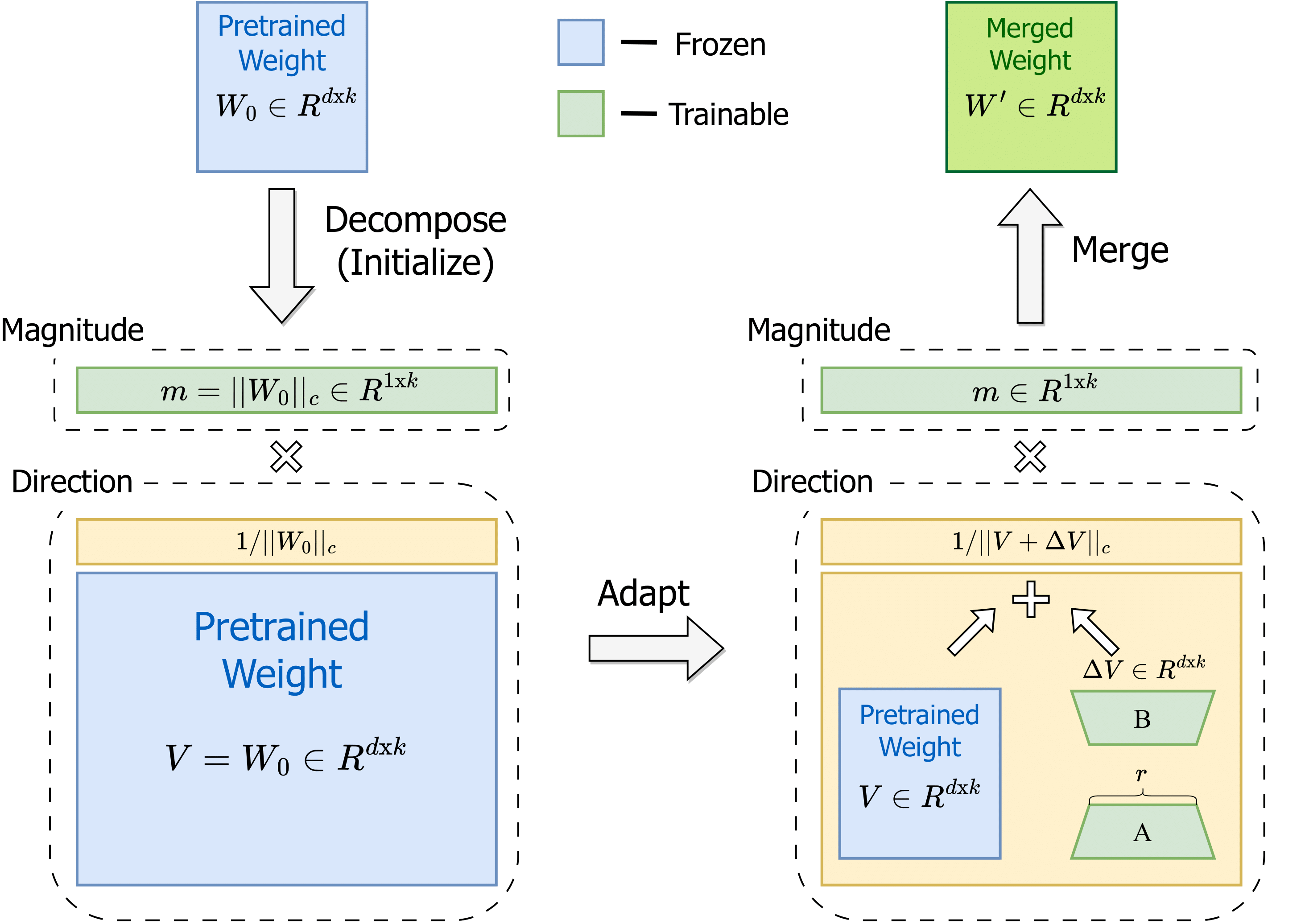
DoRA将预训练权重分解为幅度和方向两个组成部分进行微调,特别是采用LoRA进行方向更新以有效地最小化可训练参数的数量。通过采用DoRA,我们在避免任何额外推理开销的同时提高了LoRA的学习能力和训练稳定性。DoRA在各种下游任务(如常识推理、视觉指令调整和图像/视频-文本理解)上持续优于LoRA在微调LLaMA、LLaVA和VL-BART方面的表现。
如需商业咨询,请访问我们的网站并提交表单:NVIDIA研究许可。
💥 新闻 💥
- [2024.07.02] 🔥🔥 DoRA的官方NVIDIA技术博客已发布点击这里!!
- [2024.06.02] 🔥🔥 DoRA被选为ICML 2024的口头报告论文!!
- [2024.05.24] 🔥🔥 添加了如何复现QDoRA/FSDP结果的分步说明,请查看/QDoRA
- [2024.05.02] 🔥🔥 DoRA被接受到ICML 2024!! 维也纳见!!
- [2024.04.27] 🔥🔥 我们已添加在常识推理任务上微调LLaMA2-7B和LLaMA3-8B的源代码和DoRA权重!
- [2024.04.22] 🔥🔥 查看Answer.ai的精彩博文FSDP/QDoRA,显示QDoRA显著优于QLoRA,甚至略胜于完全微调!
- [2024.04.18] 🔥🔥 我们已发布源代码和DoRA权重,用于复现论文中的结果!
- [2024.03.20] 🔥🔥 DoRA现已完全被HuggingFace PEFT包支持,现可支持Linear、Conv1d和Conv2d层,以及使用bitsandbytes量化的线性层!
有用链接
- Sebastian Raschka提供的从头实现DoRA的精彩教程,请参见 https://magazine.sebastianraschka.com/p/lora-and-dora-from-scratch
- Answer.AI关于QDoRA/FSDP的精彩博文,允许在消费级GPU上微调LLMs,请参见 https://www.answer.ai/posts/2024-04-26-fsdp-qdora-llama3.html
快速开始和使用DoRA进行微调的一些技巧
HuggingFace PEFT
DoRA现已被Huggingface PEFT包支持。您可以使用以下命令安装PEFT包
pip install git+https://github.com/huggingface/peft.git -q
安装PEFT后,您只需将LoraConfig()的use_dora参数设置为True即可应用DoRA。
示例如下:
from peft import LoraConfig
# 初始化DoRA配置
config = (
use_dora=True, ...
)
更多详情请参阅官方文档。
HuggingFace Diffusers
您还可以在微调扩散模型时尝试DoRA。请参见huggingface/diffusers。另一个不错的教程是Linoy Tsaban的这个Colab笔记本。
总的来说,在扩散模型上使用DoRA进行微调仍处于_实验阶段_,可能需要不同的超参数值才能达到最佳性能,相比于LoRA。
具体而言,人们注意到在训练中需要考虑两个差异:
- LoRA似乎比DoRA收敛更快(因此,可能导致LoRA过拟合的一组参数可能适用于DoRA)
- DoRA在较低秩时的质量特别优于LoRA:秩为8的DoRA与秩为8的LoRA之间的质量差异似乎比训练秩为32或64时更显著。
一些DoRA与LoRA扩散微调结果对比
- 来自Linoy Tsaban的示例(DoRA生成的图像在左侧,LoRA在右侧):

- 来自merve的示例:

DoRA超参数设置
[!NOTE] 💡 在使用DoRA进行微调时,使用LoRA的配置大多数情况下已经可以取得更好的结果,但要达到比LoRA更优的性能仍需调整超参数。
我们建议从略低于LoRA的学习率开始,用户也可以尝试不同的LoRA dropout比率。
用户也可以从LoRA配置的一半秩开始,这通常就可以达到与LoRA相当甚至更优的准确率。
复现论文中的结果
本仓库包含四个目录:
./commonsense_reasoning 包含使用DoRA在常识推理任务上微调LLaMA-7B/13B的代码。该目录基于LLM-Adapter修改。
./instruction_tuning_dvora 包含使用DoRA和DVoRA(DoRA+VeRA)以清理后的Alpaca指令微调数据集微调LLaMA-7B和LLaMA2-7B的代码。该目录基于VeRA修改。
./image_video_text_understanding 包含使用DoRA微调VL-BART进行图像/视频-文本理解任务的代码。该目录基于VL-Adapter修改。
./visual_instruction_tuning 包含使用DoRA在视觉指令调整任务上微调LLaVA-1.5-7B的代码。该目录基于LLaVA修改。
DoRA 与 LoRA 在常识推理任务上的对比
| 模型 | r | BoolQ | PIQA | SIQA | HellaS | WinoG | ARC-e | ARC-c | OBQA | 平均分 |
|---|---|---|---|---|---|---|---|---|---|---|
| LLaMA-7B-LoRA | 32 | 67.5 | 80.8 | 78.2 | 83.4 | 80.4 | 78.0 | 62.6 | 79.1 | 76.3 |
| LLaMA-7B-DoRA(我们的) | 16 | 70.0 | 82.6 | 79.7 | 83.2 | 80.6 | 80.6 | 65.4 | 77.6 | 77.5 |
| LLaMA-7B-DoRA(我们的) | 32 | 69.7 | 83.4 | 78.6 | 87.2 | 81.0 | 81.9 | 66.2 | 79.2 | 78.4 |
| LLaMA2-7B-LoRA | 32 | 69.8 | 79.9 | 79.5 | 83.6 | 82.6 | 79.8 | 64.7 | 81.0 | 77.6 |
| LLaMA2-7B-DoRA(我们的) | 16 | 72.0 | 83.1 | 79.9 | 89.1 | 83.0 | 84.5 | 71.0 | 81.2 | 80.5 |
| LLaMA2-7B-DoRA(我们的) | 32 | 71.8 | 83.7 | 76.0 | 89.1 | 82.6 | 83.7 | 68.2 | 82.4 | 79.7 |
| LLaMA3-8B-LoRA | 32 | 70.8 | 85.2 | 79.9 | 91.7 | 84.3 | 84.2 | 71.2 | 79.0 | 80.8 |
| LLaMA3-8B-DoRA(我们的) | 16 | 74.5 | 88.8 | 80.3 | 95.5 | 84.7 | 90.1 | 79.1 | 87.2 | 85.0 |
| LLaMA3-8B-DoRA(我们的) | 32 | 74.6 | 89.3 | 79.9 | 95.5 | 85.6 | 90.5 | 80.4 | 85.8 | 85.2 |
星标历史
联系方式
刘世扬:shihyangl@nvidia.com 或 sliuau@connect.ust.hk
引用
如果您觉得DoRA有用,请考虑给予星标和引用:
@article{liu2024dora,
title={DoRA: Weight-Decomposed Low-Rank Adaptation},
author={Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung},
journal={arXiv preprint arXiv:2402.09353},
year={2024}
}
许可证
版权所有 © 2024,NVIDIA Corporation。保留所有权利。
本作品根据NVIDIA源代码许可证-NC提供。点击此处查看该许可证的副本。











