
PiSSA的诞生背景与核心思想
在大语言模型(LLM)的时代,如何高效地对模型进行微调以适应特定任务成为了一个关键问题。传统的全参数微调方法虽然效果好,但计算成本高昂。为解决这一问题,参数高效微调(PEFT)技术应运而生,其中LoRA(Low-Rank Adaptation)方法因其简单高效而广受欢迎。然而,LoRA仍存在一些局限性,如收敛速度较慢等。
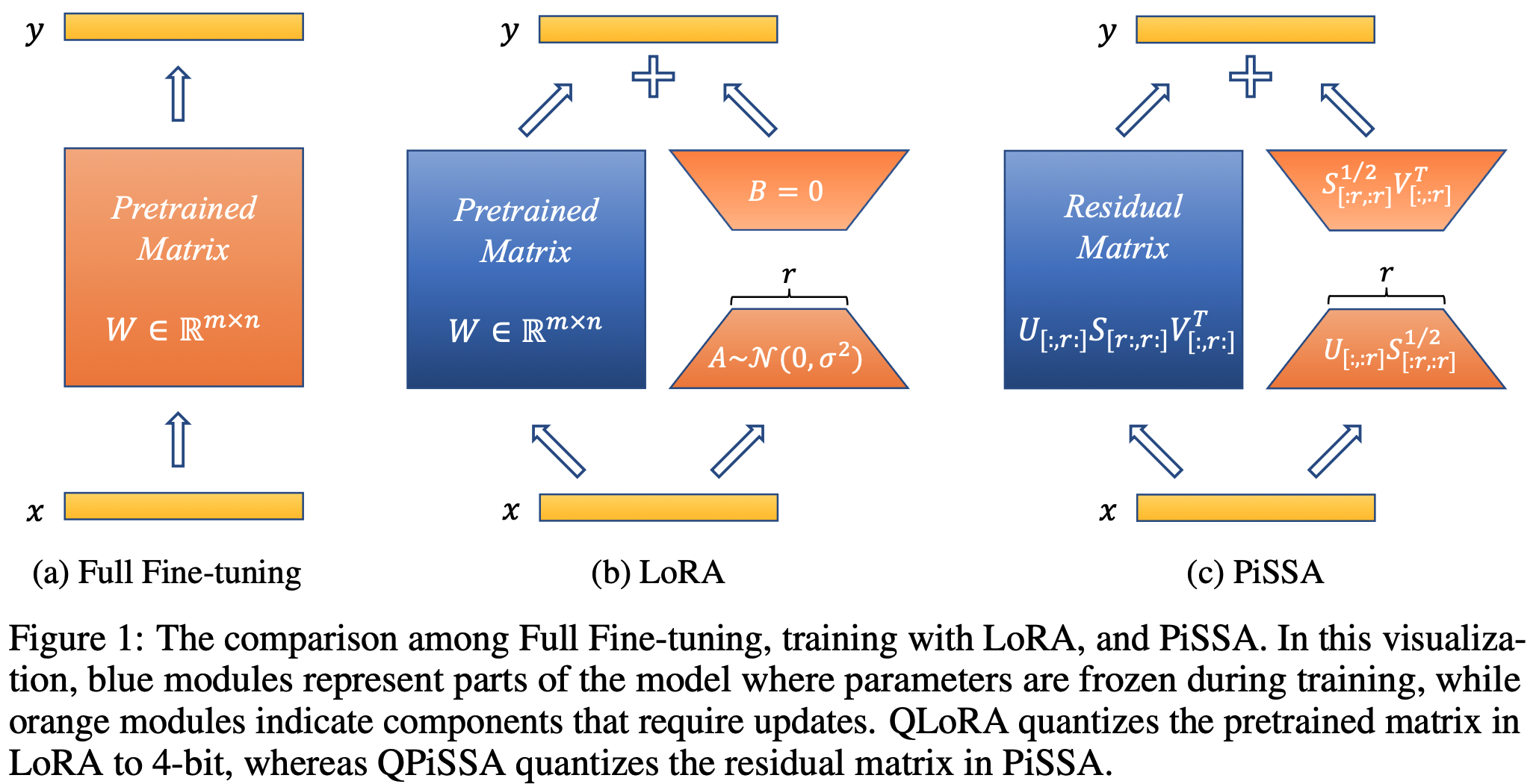
针对这些挑战,研究人员提出了一种新的PEFT方法——PiSSA(Principal Singular values and Singular vectors Adaptation)。PiSSA的核心思想是优化模型中最重要的奇异值和奇异向量,同时冻结"噪声"部分。这种方法与LoRA形成鲜明对比,后者冻结原始矩阵而更新"噪声"。正是这种本质上的区别,使得PiSSA能够实现更快的收敛速度和更优的性能表现。
PiSSA的技术原理与实现
PiSSA的技术实现基于对预训练模型权重矩阵的奇异值分解(SVD)。具体来说,对于一个预训练模型的权重矩阵W,PiSSA将其分解为U、Σ和V三个矩阵的乘积:
W = UΣV^T
其中,U和V分别是左奇异向量和右奇异向量矩阵,Σ是奇异值矩阵。PiSSA的核心就是对这些矩阵中的主要成分进行更新,而保持次要成分不变。
在实际应用中,PiSSA与LoRA共享相同的架构,但在初始化方式上有所不同。这种设计使得PiSSA能够继承LoRA的诸多优势,如参数效率高、与量化技术兼容等,同时又能克服LoRA的一些局限性。
PiSSA的性能优势
通过在多个常见基准测试中的实验,PiSSA展现出了显著的性能优势:
-
更快的收敛速度: 相比LoRA,PiSSA能够更快地达到理想的性能水平。
-
更好的最终性能: 在相同的设置下,PiSSA在所有测试基准上都优于LoRA。
-
与量化技术的良好兼容性: PiSSA显著降低了LLaMA 2-7B模型4比特量化的误差,提升了量化后模型的微调性能。
以GSM8K基准为例,使用PiSSA微调的Mistral-7B模型达到了72.86%的准确率,比LoRA的67.7%高出了5.16个百分点。这一结果充分展示了PiSSA在复杂数学推理任务上的优越性。
在量化场景下,PiSSA的优势更为明显。在GSM8K基准上,PiSSA实现了49.13%的准确率,大幅超越了QLoRA的39.8%和LoftQ的40.71%。这表明PiSSA在保持模型压缩效果的同时,能够更好地保留模型的性能。
PiSSA的实际应用
PiSSA不仅在理论上有优势,在实际应用中也展现出了强大的潜力:
-
广泛的模型支持: PiSSA已经在多个主流大语言模型上进行了测试,包括LLaMA系列、Qwen2系列等。这意味着研究者和开发者可以在多种模型架构上应用PiSSA。
-
简单的使用方式: 研究团队已经将PiSSA初始化后的模型共享在Hugging Face上,用户可以直接下载使用,无需每次都进行SVD操作。
-
与深度学习框架的集成: PiSSA已被合并到PEFT库的主分支中,作为LoRA的一种可选初始化方法。这使得开发者能够更方便地在现有项目中应用PiSSA。
-
多领域应用: 除了自然语言处理任务,PiSSA还支持卷积神经网络和嵌入层,使其可以应用于计算机视觉等更广泛的领域。
PiSSA的未来发展
作为一种新兴的PEFT技术,PiSSA的提出已经引发了学术界的广泛关注和后续研究:
- LoRA-XS提出了对主成分奇异值和奇异向量进行基底适应的方法。
- SVFT探索了冻结奇异向量而稀疏微调奇异值的策略。
- OLoRA利用QR分解实现了正交矩阵初始化。
- CorDA通过上下文导向分解实现了知识保留适应和指令预览适应。
- MiLoRA关注了次要奇异分量的适应。
- LaMDA提出了基于谱分解的低维适应方法。
- LoRA-GA尝试在第一步对齐低秩矩阵乘积与全量微调的梯度。
这些后续工作不仅验证了PiSSA思路的价值,也为PEFT领域的进一步发展提供了新的方向和灵感。
结语
PiSSA作为一种创新的参数高效微调技术,通过优化大语言模型中的主要奇异值和奇异向量,实现了快速收敛和卓越性能。它不仅在理论上有坚实的基础,在实际应用中也展现出了强大的潜力。随着更多研究的开展和技术的完善,PiSSA有望在未来的AI应用中发挥更大的作用,为大语言模型的高效适应和部署提供有力支持。
对于希望深入了解或应用PiSSA的研究者和开发者,可以访问PiSSA的GitHub仓库获取更多详细信息和代码实现。同时,关注相关的学术论文和后续研究也将有助于更全面地把握这一技术的发展动态和应用前景。










