PPO x Family:开启你的决策智能之旅
深度强化学习作为人工智能领域的前沿技术,正在各行各业掀起一场革命。而PPO(Proximal Policy Optimization)算法因其简洁高效的特点,成为了深度强化学习领域的"万能钥匙"。为了帮助更多人入门这一强大的技术,OpenDILab推出了PPO x Family公开课程,致力于用通俗易懂的方式讲解PPO算法及其在复杂决策智能场景中的应用。
课程概览
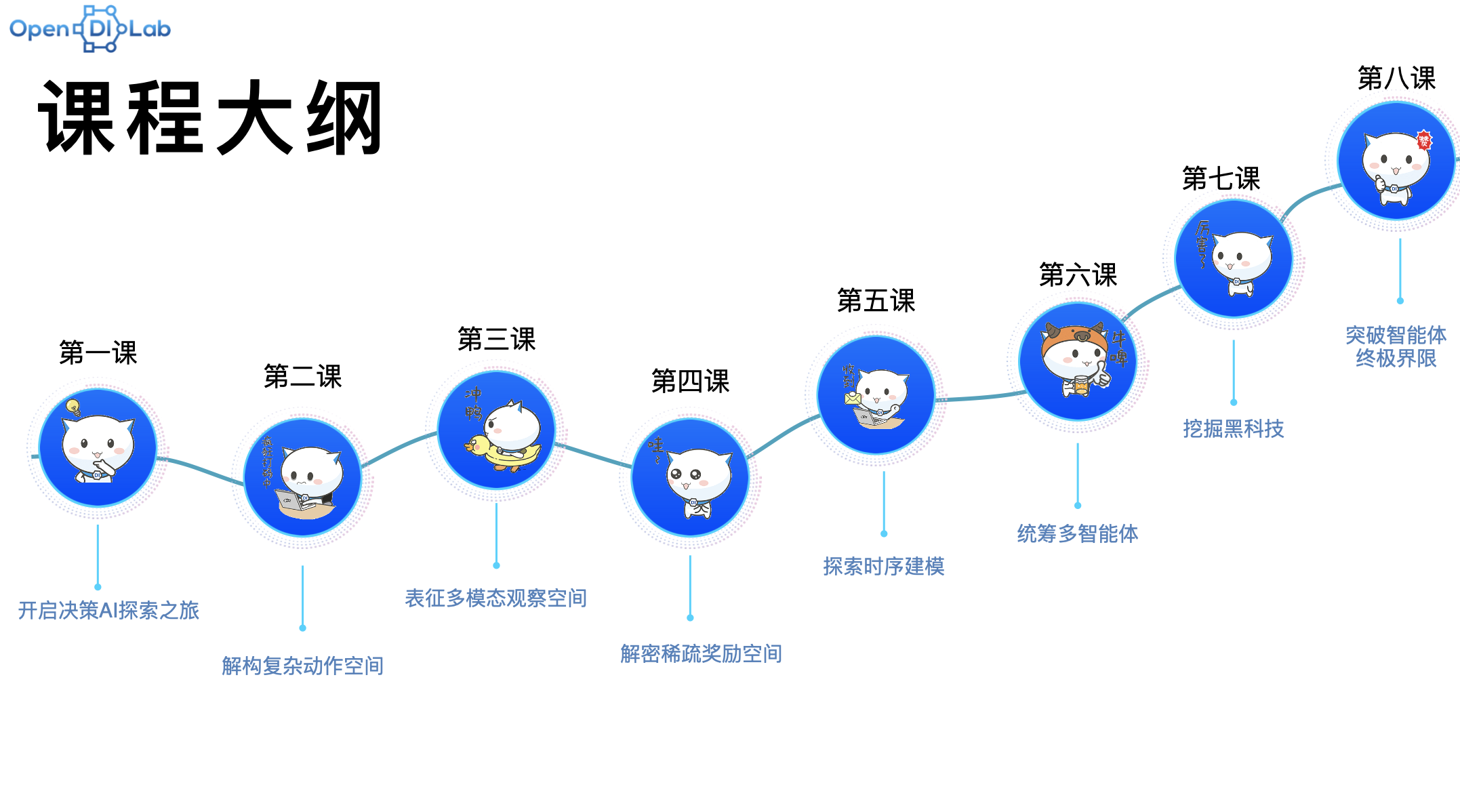
PPO x Family课程共包含8个章节,涵盖了从入门到进阶的全面内容:
- 开启决策AI探索之旅
- 解构复杂动作空间
- 表征多模态观察空间
- 解密稀疏奖励空间
- 探索时序建模
- 统筹多智能体
- 挖掘黑科技
- 突破智能体终极界限
每个章节都包含了详细的PPT讲义、补充资料、习题、代码示例以及实际应用案例,让学习者能够全方位地掌握知识点。
课程特色
PPO x Family课程具有以下几个突出特点:
-
一个算法解决万千应用
课程通过丰富的案例展示了PPO算法在自动驾驶、机器人控制、游戏AI等众多领域的广泛应用,充分体现了其通用性和强大之处。 -
算法理论与代码实现一一对应
课程为每个算法概念都提供了相应的代码实现,并配有详细注释,让学习者能够快速将理论知识转化为实践能力。 -
丰富的补充资料与习题
除了核心内容外,课程还提供了大量拓展阅读材料和习题,帮助学习者加深理解并巩固所学知识。 -
实际应用案例
每个章节都包含了相关的应用示例,让学习者了解如何将所学知识应用到实际问题中。
深入浅出的课程内容
接下来让我们简要了解一下课程的核心内容:
第一章:开启决策AI探索之旅
本章介绍了强化学习的基本概念,包括马尔可夫决策过程、策略梯度等,为后续学习奠定基础。同时还讲解了A2C、TRPO等PPO的前身算法,帮助学习者理解PPO算法的演进过程。
第二章:解构复杂动作空间
这一章探讨了如何处理离散、连续以及混合动作空间。通过对比PPO与DDPG等算法,深入分析了PPO在处理连续动作空间时的优势。
第三章:表征多模态观察空间
本章讲解了如何处理图像、文本等多模态输入,介绍了表征学习的相关概念,以及PPG等改进算法。
第四章:解密稀疏奖励空间
稀疏奖励是强化学习中的一大挑战。本章介绍了好奇心驱动探索、逆强化学习等技术来应对这一问题。
第五章:探索时序建模
针对需要长期记忆的任务,本章讲解了LSTM、Transformer等序列模型在强化学习中的应用。
第六章:统筹多智能体
多智能体学习是一个复杂的话题。本章介绍了独立学习、集中式学习等范式,以及MAPPO、HAPPO等算法。
第七章:挖掘黑科技
本章介绍了一系列提升PPO性能的技巧,如GAE、梯度裁剪、正交初始化等。
第八章:突破智能体终极界限
作为课程的收官之作,本章将探讨如何将PPO应用于大规模语言模型等复杂系统中。
丰富的学习资源
PPO x Family课程不仅提供了详尽的视频讲解,还配套了丰富的学习资源:
-
详细的PPT讲义: 每章都有系统的PPT讲义,方便学习者回顾和复习。
-
补充阅读材料: 针对重要概念提供了深入的理论推导和扩展阅读。
-
习题及解答: 每章都配有习题,帮助学习者巩固所学知识。
-
代码示例: 提供了大量Python代码示例,涵盖了算法实现的关键部分。
-
应用案例: 每章都有相关的实际应用案例,展示了算法的实际应用价值。
开放互动的学习社区
PPO x Family课程非常重视与学习者的互动。课程团队提供了多种交流渠道:
- 微信小助手
- Slack讨论组
- GitHub Issue区
- B站、知乎等社交媒体账号
学习者可以通过这些渠道提出问题、分享心得,与其他学习者和课程团队进行深入交流。
课程影响力
自2022年12月上线以来,PPO x Family课程在B站等平台获得了广泛关注和好评。课程的创新性和实用性得到了学术界和工业界的认可,被机器之心、PaperWeekly等业内知名媒体报道。
未来展望
PPO x Family课程团队表示,他们将持续更新和完善课程内容,探索更多前沿主题。同时,他们也鼓励学习者将所学知识应用到实际问题中,推动深度强化学习技术的发展和应用。
结语
PPO x Family公开课为我们打开了深度强化学习的大门,展示了这一强大技术的无限可能。无论你是AI领域的学生、研究者,还是对决策智能感兴趣的从业者,这门课程都能为你提供宝贵的学习资源。让我们一起踏上这段激动人心的学习之旅,探索AI决策的奥秘,共同推动人工智能技术的发展!
通过PPO x Family课程的学习,相信你将能够:
- 深入理解PPO算法的核心原理
- 掌握处理复杂决策问题的实用技巧
- 了解深度强化学习的前沿进展
- 具备将算法应用于实际问题的能力
让我们携手前行,在这个AI日新月异的时代,成为决策智能领域的探索者和实践者!
















