
 访问官网
访问官网 Github
Github 文档
文档实现用于自动驾驶的深度强化学习模型
人工智能(AI)在几乎所有技术领域中都在迅速发展,自驾车的研究就是其中之一。在这项工作中,我们将利用最先进的方法,通过深度强化学习(DRL)方法来训练我们的代理自主驾驶。我们将使用一个开源模拟器,CARLA,来进行我们的实验,提供一个超真实的城市模拟环境来训练我们的模型。由于直接在真实世界中使用我们的算法带有许多风险和道德问题,所以我们使用这些模拟器来帮助我们进行测试。
此外,DRL在学习复杂决策任务方面显示出令人鼓舞的成果,从战略游戏到困难的谜题。在这里,我们将研究一种叫做近端策略优化(PPO)的按照策略学习的DRL算法在模拟驾驶环境中如何学会在预定路线上导航。这项工作的主要目标是研究DRL模型如何在连续的状态和动作空间中训练一个代理。我们的主要贡献是一个基于PPO的代理,它可以在我们的基于CARLA的环境中可靠地学会驾驶。此外,我们还实现了一个变分自编码器(VAE),它将高维观察压缩成一个可能更易学习的低维潜空间,从而帮助我们的代理更快地学习。
项目简介
这项工作的目标是开发一个端到端的自动驾驶解决方案,它可以向车辆发送指令,以帮助其朝正确的方向行驶并尽量避免碰撞,分为以下几个部分:
- CARLA环境设置
- 变分自编码器
- 近端策略优化
我们使用了CARLA(版本0.9.8)作为我们的环境(城市模拟器)。我们还总结了一些结果和分析,以进一步简化这个问题。
请查看文档工作这里以更好地理解整个项目。
前提条件
我们使用的是CARLA(0.9.8)+附加地图。我们主要关注的是两个城镇,即城镇2和城镇7,所以建议您下载附加地图文件和CARLA服务器一起。您可以将附加地图目录中的地图复制粘贴到主CARLA目录中,以确保一切顺利。
接下来我们建议您在Windows或Linux上设置您的项目,因为这是目前CARLA支持的两个操作系统。
项目设置(安装)
为了设置这个项目,建议您克隆这个存储库,并确保您安装了Python v3.7.+(64位)版本。在克隆这个存储库后,我们可以为这个项目创建一个Python虚拟环境 💥 我们称之为venv python -m venv venv。如果愿意,您可以叫它别的名字 :) 现在我们可以激活我们的虚拟环境 source venv/Script/activate,在安装任何依赖项之前不要忘记这样做。接下来我们可以使用pip安装依赖项,使用以下命令 pip install -r requirements.txt。我们不仅使用pip作为我们的依赖项管理器,还使用poetry,因此在仓库中执行以下命令 cd poetry/ && poetry update。这将使用poetry安装所有其他依赖项。一旦一切设置完毕,我们就差不多完成了!
下载CARLA服务器(0.9.8)+附加地图,并确保您已经阅读了本仓库的前提条件。一旦服务器启动并运行,我们可以使用python continuous_driver.py --exp-name=ppo --train=False命令启动我们的客户端。在此之前不要忘记启动Carla服务器。耶!!!
构建工具
- Python - 编程语言
- PyTorch - 开源机器学习框架
- CARLA - 一个城市驾驶模拟器
- Poetry - 包和依赖管理器
- Tensorboard - 可视化工具包
方法论
封装三个最基本组件的架构布局:
- CARLA模拟。
- VAE。
- PPO代理。
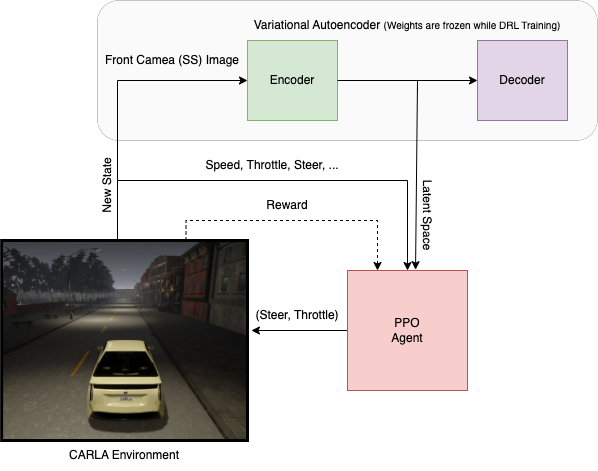
架构方法论
如何运行
运行训练好的代理
在项目中,我们为您提供了两个预训练的PPO代理,每个城镇一个(城镇02和城镇07)。
该模型的预训练序列化文件放置在preTrained_models/PPO/<town>文件夹中。
python continuous_driver.py --exp-name ppo --train False
默认情况下,我们在城镇07,但我们可以通过以下参数改为城镇02:
python continuous_driver.py --exp-name ppo --train False --town Town02
训练一个新代理
为了训练一个新代理,请使用以下命令:
python continuous_driver.py --exp-name ppo
这将开始使用默认参数训练一个代理,检查点将写入checkpoints/PPO/<town>/,其他指标将记录到logs/PPO/<town>/。与上面一样,默认情况下我们在城镇07进行训练,但我们可以通过添加此参数改为城镇02 --town Town02。
我们的训练是这样的。

城镇 7
城镇 2
变分自编码器
变分自编码器(VAE)训练过程从自动和手动驾驶开始,收集12,000张160x80的语义分割图像用于训练。然后,我们将SS图像作为变分自编码器的输入(h ∗ 𝑤 ∗ 𝑐 = 38400输入单元)。在我们的DRL网络训练时,VAE的权重被冻结。
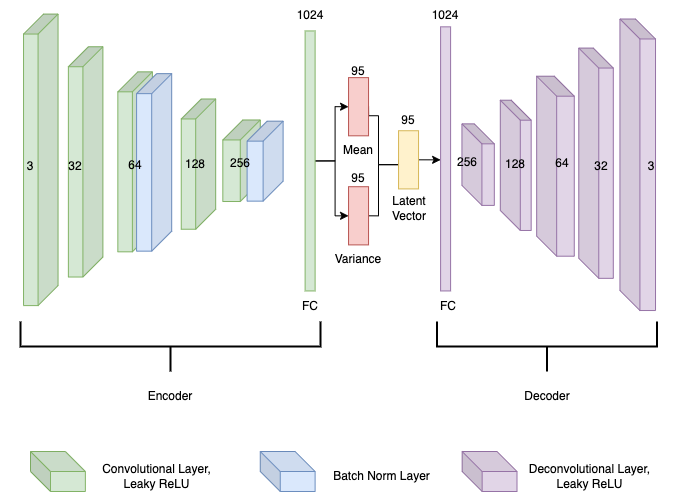
变分自编码器
一旦我们训练好了我们的VAE,我们可以使用以下命令来检查重建图像:
cd autoencoder && python reconstructor.py
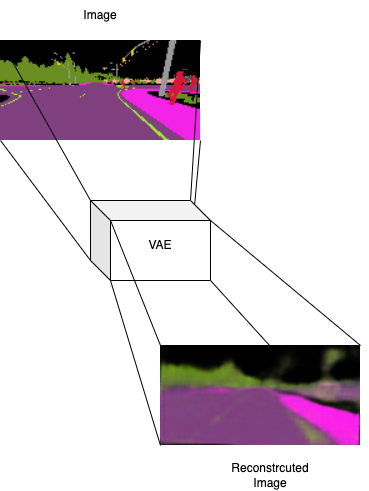
原始图像到重建图像
项目架构管道(编码器到PPO)
以下图表描述了VAE+PPO训练管道。注意:所有变量名缺少下标𝑡。
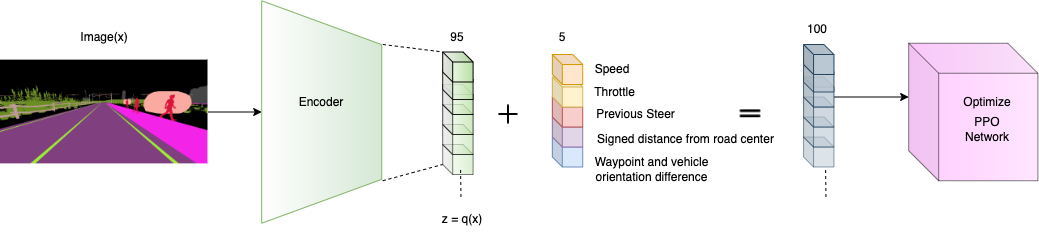
VAE + PPO训练管道
文件概述
| 文件 | 描述 |
|---|---|
| continuous_driver.py | 训练/测试我们连续代理(如PPO代理)的脚本 |
| discrete_driver.py | 训练我们离散代理(如决斗DQN代理)的脚本(在进行中) |
| encoder_init.py | 使用经过训练的编码器将传入图像(状态)转换为潜在空间的脚本 |
| parameters.py | 包含项目的超参数 |
| simulation/connection.py | CARLA环境类,负责与CARLA服务器建立连接 |
| simulation/environment.py | 欢CARLA环境类,包含大部分环境设置功能(受gym启发的类结构) |
| simulation/sensors.py | CARLA环境文件,包含所有代理的传感器类(设置) |
| simulation/settings.py | CARLA环境文件,包含环境设置参数 |
| runs/ | 包含Tensorboard图表/图形的文件夹 |
| preTrained_models/ppo | 包含预训练模型序列化文件的文件夹 |
| networks/on_policy/agent.py | 包含我们PPO代理代码 |
| networks/on_policy/ppo.py | 包含我们PPO网络代码 |
| logs/ | 包含我们代理在训练期间记录的指标的文件夹 |
| info/ | 包含项目图像、动图、图表和文档的信息文件夹 |
| checkpints/ | 包含我们代理在训练期间保存的序列化参数的文件夹 |
| carla/ | 包含CARL egg文件的文件夹,用于与服务器建立连接 |
| autoencoder/ | 包含我们变分自编码器(VAE)代码的文件夹 |
查看Tensorboard中的训练进度/图表:
tensorboard --logdir runs/
作者
Idrees Razak - GitHub, LinkedIn
许可证
该项目根据MIT许可进行许可,请参见LICENSE.md文件了解详情
致谢
感谢Dr. Toka László教授在这项工作中的卓越领导和不懈支持。











