
 Github
Github 论文
论文[PYTORCH] 使用近端策略优化 (PPO) 训练超级马里奥
引言
以下是我用于训练代理玩超级马里奥的Python源码。通过使用近端策略优化算法 论文中介绍的PPO算法。
关于性能方面,我训练的PPO代理可以完成31/32关卡,这比我一开始预期的要好很多。
供参考,PPO是由OpenAI提出的算法,并用于训练OpenAI Five,这是第一个在电子竞技游戏中击败世界冠军的AI。具体来说,OpenAI Five在2018年8月击败了一支由MMR排名在Dota 2玩家的99.95百分位的主播和前职业选手组成的队伍。


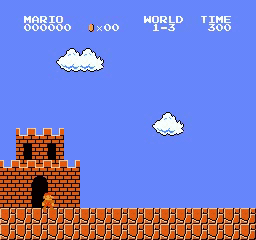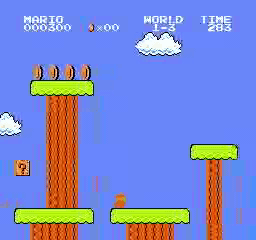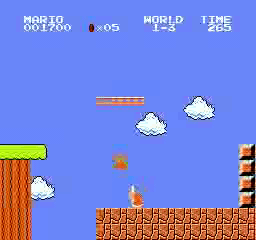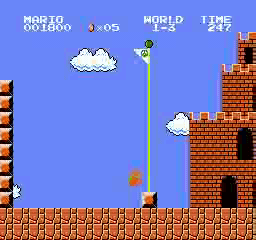


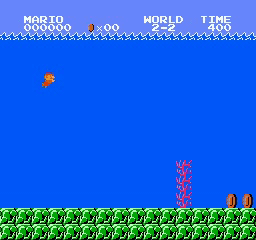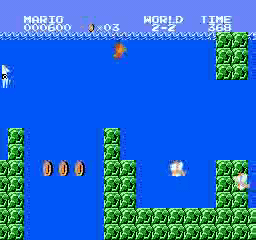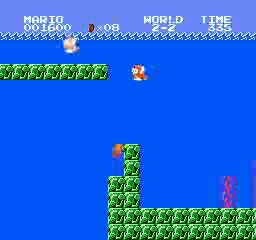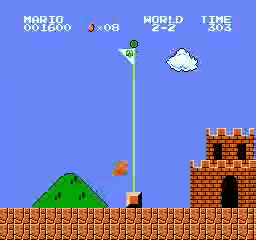

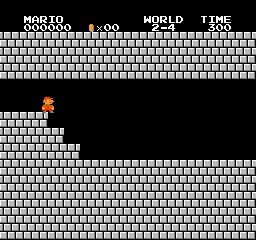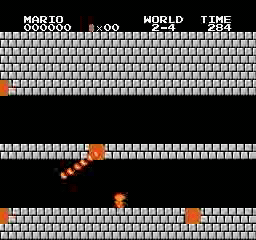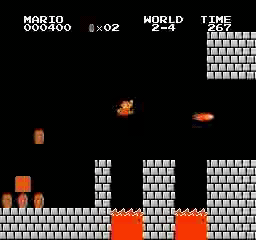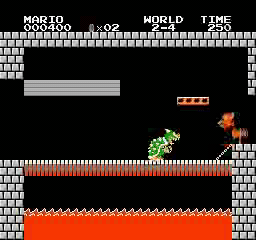



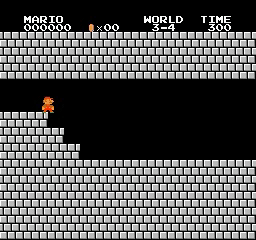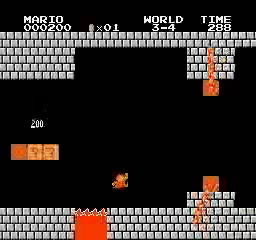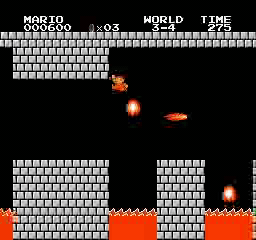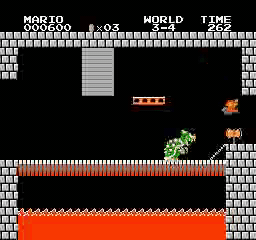


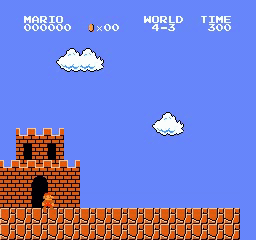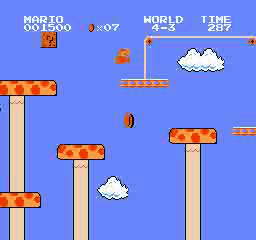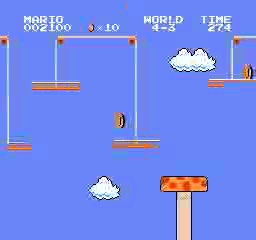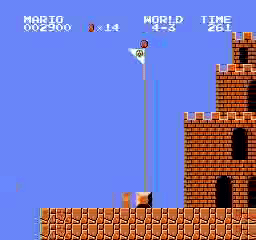
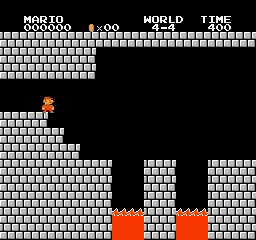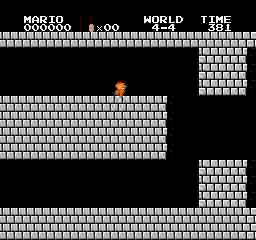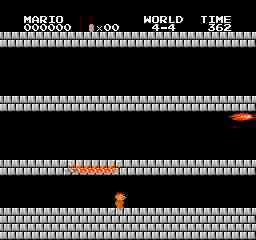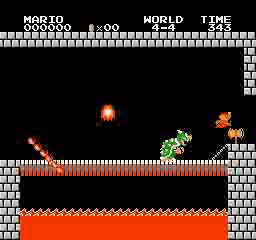
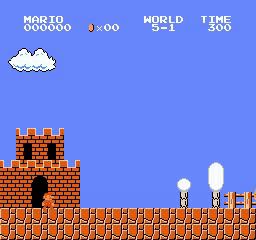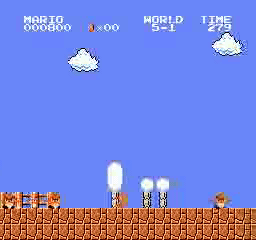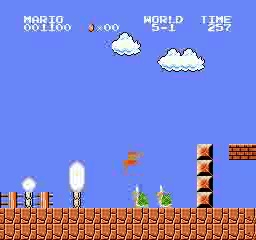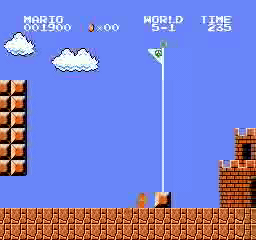












样本结果
动机
自从我发布了我的A3C实现 (A3C源码) 用于训练一个代理玩超级马里奥以来已经有段时间了。虽然训练的代理可以相当快且相当好地完成关卡(至少比我玩的时候快且好:汗:),但它仍然没有完全满足我。主要原因是,使用A3C训练的代理只能完成19/32关卡,无论我如何微调和测试。这促使我寻找一种新的方法。
在我决定选择PPO作为下一个完整的实现之前,我部分实现了其他几个算法,包括A2C和Rainbow。前者没有显示出显著的性能提升,而后者更适用于更随机的环境/游戏,如乒乓球或太空侵略者。
如何使用我的代码
使用我的代码,你可以:
- 训练你的模型,通过运行
python train.py。例如:python train.py --world 5 --stage 2 --lr 1e-4 - 测试你训练的模型,通过运行
python test.py。例如:python test.py --world 5 --stage 2
注意: 如果你在任何关卡卡住了,尝试用不同的学习率重新训练。你可以像我一样仅通过改变学习率来征服31/32关卡。通常我设置学习率为1e-3,1e-4 或 1e-5。然而,有些困难的关卡,包括关卡1-3,最后我用7e-5的学习率在失败70次后成功训练。
Docker
为了方便,我提供了Dockerfile,可以用于运行训练以及测试阶段
假设docker镜像名称是ppo。你只想使用第一个gpu。你已经克隆了这个仓库并进入到它。
构建:
sudo docker build --network=host -t ppo .
运行:
docker run --runtime=nvidia -it --rm --volume="$PWD"/../Super-mario-bros-PPO-pytorch:/Super-mario-bros-PPO-pytorch --gpus device=0 ppo
然后在docker容器内部,你可以简单地运行如上所述的train.py或test.py脚本。
注意: 使用docker时渲染有一个错误。因此,当使用docker进行训练或测试时,请在src/process.py脚本中为训练或test.py脚本中测试时注释掉 env.render() 行。然后,你将无法看到弹出的可视化窗口。但这不是一个大问题,因为训练过程仍然会运行,测试过程将以输出的mp4文件用于可视化结束。
为什么仍然缺少第8-4关卡?
在第4-4关、第7-4关和第8-4关中,地图包含了谜题,玩家必须选择正确的路径才能前进。如果你选择了错误的路径,你必须再次走过你访问过的路径。通过对环境进行一些硬核设置,前两个关卡已经解决。但最后一个关卡还没有解决。











