
QFormer:突破性的四边形注意力视觉Transformer
近年来,视觉Transformer在计算机视觉领域取得了巨大成功。然而,传统基于窗口的注意力机制在处理不同尺寸、形状和方向的目标时存在局限性。为了解决这一问题,来自澳大利亚悉尼大学的研究团队提出了一种新型视觉Transformer架构——QFormer,通过创新的四边形注意力(Quadrangle Attention)机制实现了更加灵活和高效的特征提取。
QFormer的核心创新:四边形注意力机制
QFormer的核心创新在于其四边形注意力机制。与传统的基于固定矩形窗口的注意力不同,四边形注意力引入了一个端到端可学习的四边形回归模块。该模块能够预测一个变换矩阵,将默认的矩形窗口转换为目标四边形,用于token采样和注意力计算。这种设计使得网络能够自适应地建模不同形状和方向的目标,捕获更丰富的上下文信息。
四边形注意力的工作流程如下:
- 首先定义默认的矩形窗口
- 四边形回归模块预测变换矩阵
- 应用变换矩阵将矩形窗口转换为目标四边形
- 在目标四边形内进行token采样
- 基于采样的tokens计算注意力
这种灵活的注意力机制使QFormer能够更好地适应不同尺度和形状的视觉特征,从而在各种视觉任务中取得优异性能。
QFormer的网络架构
QFormer提供了两种网络架构变体:
-
平面QFormer (QFormerp):保持原始Vision Transformer的整体架构,仅将自注意力模块替换为四边形注意力。
-
层次化QFormer (QFormerh):采用类似Swin Transformer的层次化设计,在不同尺度上应用四边形注意力。
这两种变体使QFormer能够灵活应对不同的任务需求。平面架构更适合需要全局信息的任务,而层次化架构则在需要多尺度特征的任务中表现更好。
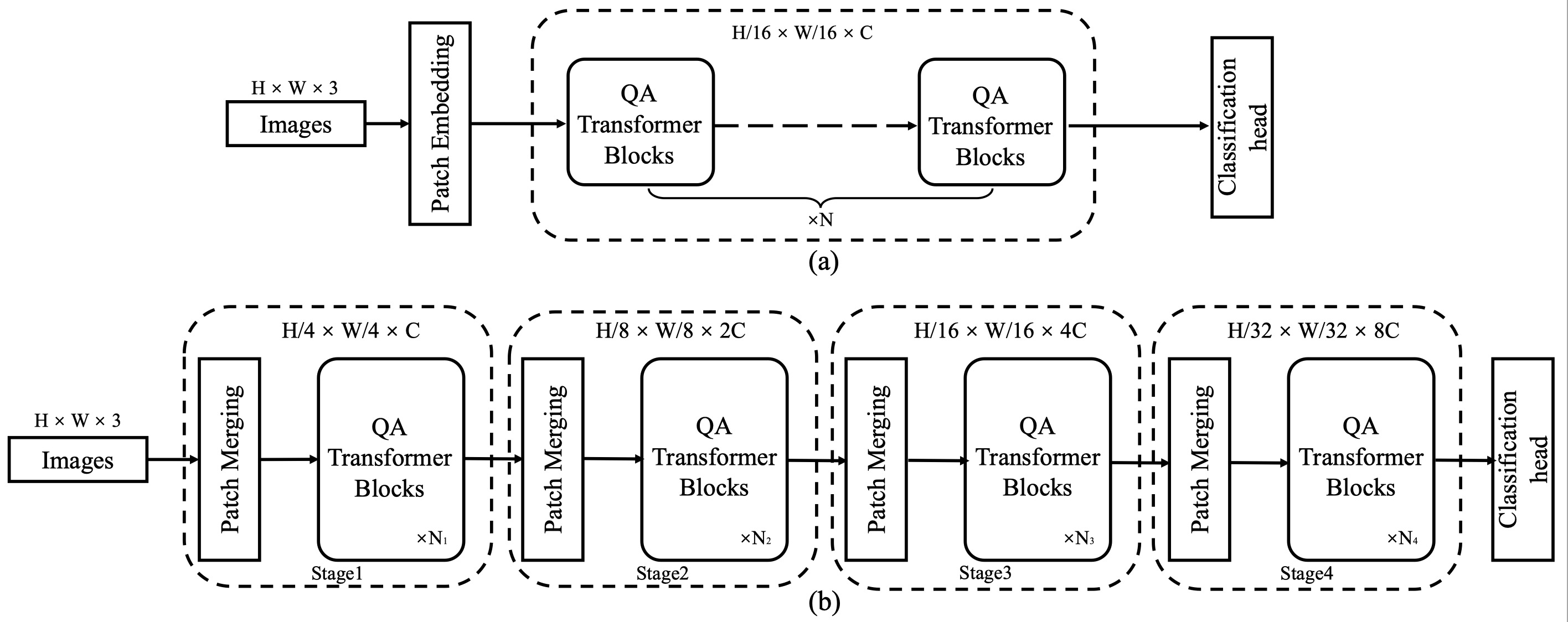
图1: QFormer的平面架构(a)和层次化架构(b)
QFormer的优越性能
QFormer在多个计算机视觉任务上进行了广泛的实验评估,包括图像分类、目标检测、语义分割和人体姿态估计。实验结果表明,QFormer在各项任务中均优于现有的代表性视觉Transformer模型。
图像分类
在ImageNet-1K数据集上的分类结果显示,QFormer相比于其他模型具有明显优势:
| 模型 | 分辨率 | Top-1准确率 |
|---|---|---|
| Swin-T | 224x224 | 81.2% |
| DW-T | 224x224 | 82.0% |
| Focal-T | 224x224 | 82.2% |
| QFormerh-T | 224x224 | 82.5% |
可以看到,QFormerh-T以82.5%的Top-1准确率领先其他同等规模的模型。在更大规模的模型上,QFormer的优势更加明显,QFormerh-B达到了84.1%的Top-1准确率。
目标检测
在COCO数据集上使用Mask R-CNN检测器进行的实验也展示了QFormer的卓越性能:
| 骨干网络 | box mAP | mask mAP |
|---|---|---|
| Swin-T | 43.7 | 39.8 |
| DAT-T | 44.4 | 40.4 |
| Focal-T | 44.8 | 41.0 |
| QFormerh-T | 45.9 | 41.5 |
QFormerh-T在box mAP和mask mAP上均优于其他模型,分别达到45.9和41.5。这说明QFormer提取的特征更有利于目标检测任务。
语义分割
在ADE20K数据集上使用UperNet进行语义分割的实验结果如下:
| 骨干网络 | mIoU | mIoU* |
|---|---|---|
| Swin-T | 44.5 | 45.8 |
| DAT-T | 45.5 | 46.4 |
| DW-T | 45.7 | 46.9 |
| Focal-T | 45.8 | 47.0 |
| QFormerh-T | 46.9 | 48.1 |
QFormerh-T在mIoU和mIoU*指标上均达到最佳,分别为46.9和48.1,这进一步证明了QFormer在密集预测任务中的优势。
人体姿态估计
在COCO数据集上的人体姿态估计任务中,QFormer同样表现出色:
| 注意力机制 | AP | AR |
|---|---|---|
| Window | 66.4 | 72.9 |
| Shifted window | 76.4 | 81.6 |
| Quadrangle | 77.0 | 82.0 |
| Quadrangle + Full | 77.4 | 82.4 |
四边形注意力(Quadrangle)相比窗口注意力和移位窗口注意力均有明显提升,特别是在与全局注意力结合后,AP和AR分别达到77.4和82.4,实现最佳效果。
这些实验结果充分证明了QFormer在各类视觉任务中的卓越性能和泛化能力。四边形注意力机制使QFormer能够更好地适应不同尺度和形状的视觉特征,从而在多种任务中取得领先结果。
QFormer的实现与使用
QFormer的实现基于PyTorch深度学习框架,并提供了详细的使用说明。以下是在ImageNet-1K数据集上训练QFormer的示例命令:
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
python -m torch.distributed.launch \
--nnodes ${NNODES} \
--node_rank ${SLURM_NODEID} \
--master_addr ${MHOST} \
--master_port 25901 \
--nproc_per_node 8 \
./main.py \
--cfg configs/swin/qformer_tiny_patch4_window7_224.yaml \
--data-path ${IMAGE_PATH} \
--batch-size 128 \
--tag 1024-dpr20-coords_lambda1e-1 \
--distributed \
--coords_lambda 1e-1 \
--drop_path_rate 0.2 \
这个命令使用分布式训练在8个GPU上训练QFormer-Tiny模型。用户可以通过修改配置文件和命令行参数来调整模型结构和训练超参数。
QFormer的代码仓库还提供了预训练模型和详细的实验日志,方便研究者复现论文结果并在自己的任务中应用QFormer。
QFormer的意义与展望
QFormer的提出为视觉Transformer的设计提供了新的思路。四边形注意力机制突破了传统基于窗口注意力的局限性,为处理不同尺度和形状的视觉特征提供了更灵活的解决方案。这一创新不仅提升了模型性能,还增强了模型的可解释性,因为四边形注意力的变换过程可以直观地展示模型关注的区域。
未来,QFormer的研究方向可能包括:
- 进一步优化四边形回归模块,提高注意力计算的效率。
- 将四边形注意力机制扩展到更多视觉任务,如图像生成、视频理解等。
- 探索四边形注意力与其他注意力机制的结合,如全局注意力、跨尺度注意力等。
- 研究QFormer在大规模预训练中的表现,开发面向通用视觉任务的基础模型。
总的来说,QFormer为视觉Transformer的发展开辟了新的道路,有望在未来的计算机视觉研究和应用中发挥重要作用。
结论
QFormer通过创新的四边形注意力机制,成功地扩展了视觉Transformer的能力边界。它在图像分类、目标检测、语义分割和人体姿态估计等多个任务上的出色表现,证明了其作为一种通用视觉骨干网络的潜力。随着进一步的研究和优化,QFormer有望成为计算机视觉领域的重要工具,推动各种视觉智能应用的发展。
研究者和开发者可以通过QFormer的GitHub仓库获取更多信息,包括完整的代码实现、预训练模型和详细文档。我们期待看到QFormer在更多领域的应用和进一步的改进。


















