
引言
在现实世界的许多机器学习应用中,类别不平衡问题普遍存在且难以解决。随着大数据时代的到来,我们越来越多地面临着规模庞大、极度不平衡且质量参差不齐的数据集。传统的学习方法在这种情况下往往表现不佳或计算效率低下。为了应对这一挑战,研究人员提出了Self-paced Ensemble (SPE)这一创新的集成学习框架。
SPE的核心思想
Self-paced Ensemble的核心思想是通过自步调节的欠采样方式来协调数据的难度,从而生成一个强大的集成分类器。SPE在每次迭代中执行严格平衡的欠采样,因此计算效率极高。此外,SPE不依赖于计算样本之间的距离来进行重采样,这使得它可以轻松应用于缺乏明确定义距离度量的数据集(例如具有分类特征或缺失值的数据集),而无需任何修改。
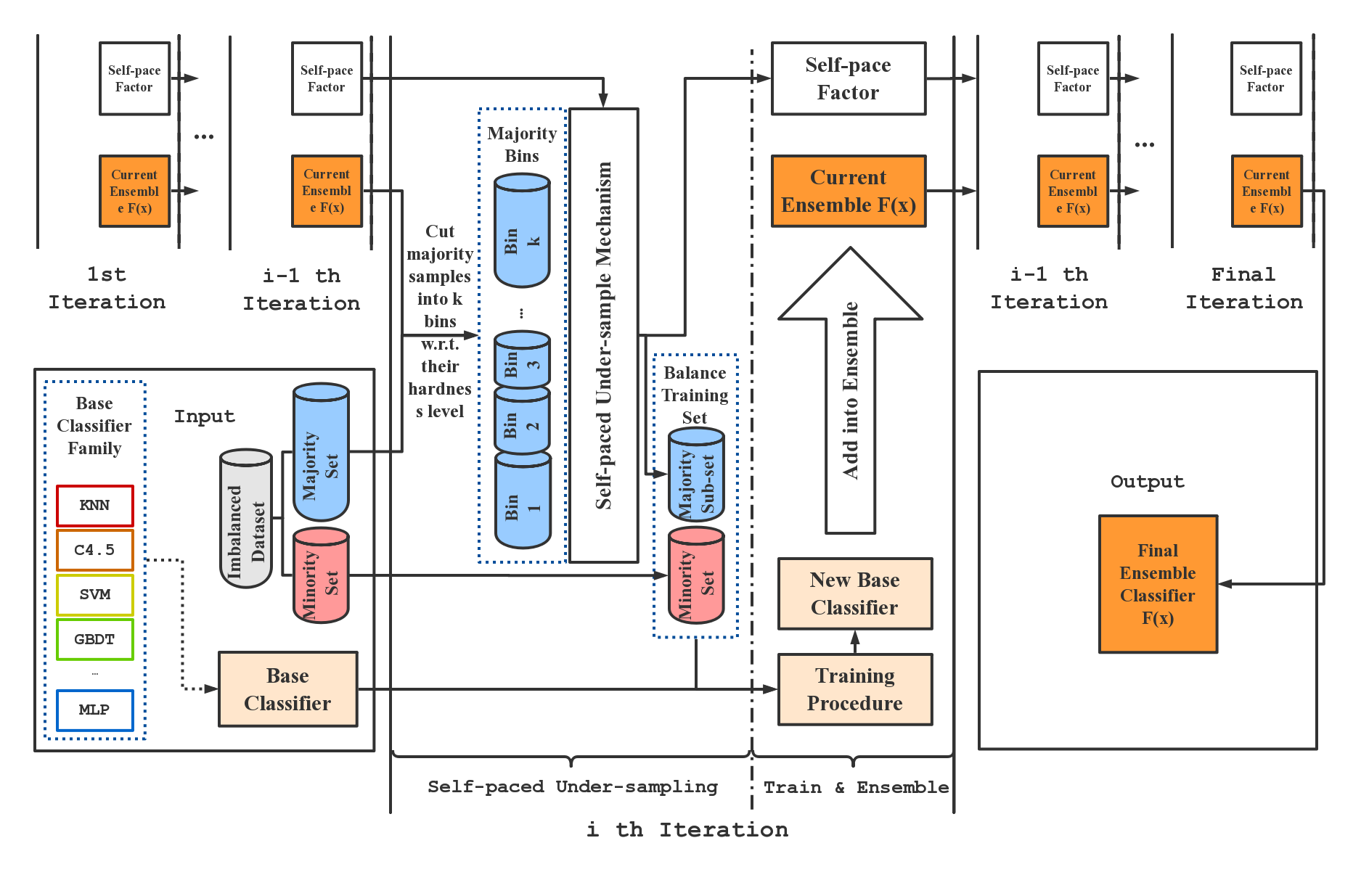
SPE的主要优势
-
计算效率高: SPE采用严格平衡的欠采样策略,大大提高了计算效率。
-
广泛适用性: 作为一个通用的集成框架,SPE可以轻松适应大多数现有的学习方法(如C4.5、SVM、GBDT和神经网络等),以提高它们在不平衡数据上的性能。
-
性能出色: 与现有的不平衡学习方法相比,SPE在大规模、噪声大且高度不平衡的数据集上表现特别出色(例如,不平衡比例大于100:1的情况)。
-
易于使用: SPE的实现可以像使用
sklearn.ensemble分类器一样简单直观地使用。
SPE的工作原理
SPE通过以下步骤来处理不平衡数据:
-
初始化: 从原始数据集中随机抽样创建一个平衡子集。
-
训练基分类器: 使用当前平衡子集训练一个基分类器。
-
难度评估: 使用当前基分类器对多数类样本进行预测,评估每个样本的难度。
-
采样更新: 根据样本难度,从多数类中选择一部分"困难"样本,与少数类样本组成新的平衡子集。
-
迭代: 重复步骤2-4,直到达到预设的迭代次数。
-
集成: 将所有训练得到的基分类器集成,形成最终的分类器。
SPE的实际应用
SPE在多个真实世界的大规模不平衡数据集上展现出了优异的性能。以下是一些具有代表性的实验结果:
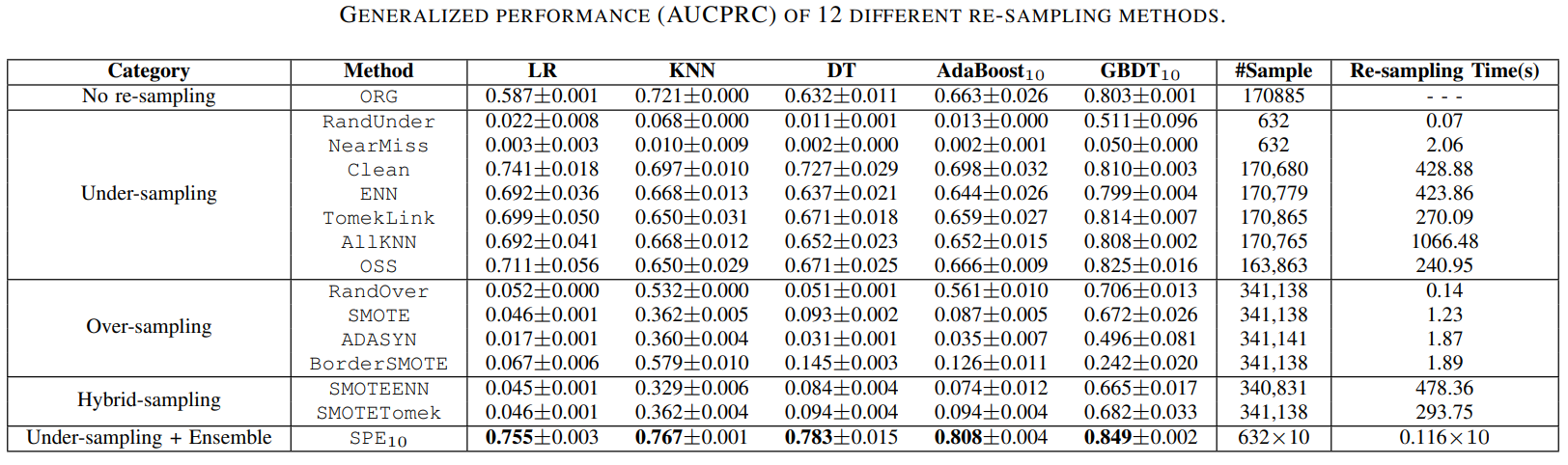
从上图可以看出,SPE在各种评估指标上都优于传统的重采样和集成方法。特别是在Credit Fraud、KDDCUP、Record Linkage和Payment Simulation等大规模数据集上,SPE展现出了显著的优势。
如何使用SPE
SPE已经被实现为一个易用的Python库。以下是一个简单的使用示例:
from self_paced_ensemble import SelfPacedEnsembleClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 准备类别不平衡的训练和测试数据
X, y = make_classification(n_classes=2, weights=[0.1, 0.9], random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
# 训练SPE分类器
clf = SelfPacedEnsembleClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=10,
).fit(X_train, y_train)
# 使用SPE分类器进行预测
predictions = clf.predict(X_test)
总结与展望
Self-paced Ensemble为解决类别不平衡问题提供了一种新的思路。它不仅在性能上超越了传统方法,还具有计算效率高、适用范围广等优点。随着大数据和人工智能技术的不断发展,我们相信SPE将在更多领域发挥重要作用,为处理不平衡数据集带来新的机遇。
未来的研究方向可能包括:
- 将SPE与深度学习模型结合,探索在更复杂的数据结构中的应用。
- 研究SPE在多类别不平衡问题中的扩展。
- 探索SPE在流数据或在线学习场景中的应用。
总的来说,Self-paced Ensemble为机器学习领域解决类别不平衡问题提供了一个强有力的工具,其简单而有效的思想值得我们进一步探索和应用。
参考资料
-
Liu, Z., Cao, W., Gao, Z., Bian, J., Chen, H., Chang, Y., & Liu, T. Y. (2020). Self-paced ensemble for highly imbalanced massive data classification. In 2020 IEEE 36th International Conference on Data Engineering (ICDE) (pp. 841-852). IEEE.
-
Self-paced Ensemble GitHub仓库: https://github.com/ZhiningLiu1998/self-paced-ensemble
-
Imbalanced-Ensemble 文档: https://imbalanced-ensemble.readthedocs.io/
通过本文的介绍,我们深入了解了Self-paced Ensemble这一创新的类别不平衡学习框架。它不仅在理论上提出了新的思路,还在实践中展现出了优异的性能。相信随着进一步的研究和应用,SPE将为机器学习领域解决类别不平衡问题带来更多突破。









