
 访问官网
访问官网 Github
Github 文档
文档 论文
论文







用于高度不平衡海量数据分类的自步调整集成学习方法(ICDE 2020)
链接: 论文 | 幻灯片 | 视频 | arXiv | PyPI | API参考 | 相关项目 | 知乎
自步调整集成学习(Self-paced Ensemble,SPE)是一种用于海量高度不平衡分类的集成学习框架。它是一种易于使用的类别不平衡问题解决方案,具有出色的计算效率、良好的性能,以及与不同学习模型的广泛兼容性。此SPE实现支持多类分类。
| 注意: SPE现已成为imbalanced-ensemble的一部分 [文档, PyPI]。尝试使用它以获得更多方法和高级功能! |
引用我们
如果您发现本仓库对您的工作或研究有帮助,我们将非常感谢您引用以下论文:
@inproceedings{liu2020self-paced-ensemble,
title={自步调节集成用于高度不平衡的大规模数据分类},
author={刘志宁, 曹伟, 高志峰, 边江, 陈和昌, 常毅, 刘铁岩},
booktitle={2020年第36届IEEE国际数据工程会议(ICDE)论文集},
pages={841--852},
year={2020},
organization={IEEE}
}
安装
推荐使用pip进行安装。 请确保安装最新版本以避免潜在问题:
$ pip install self-paced-ensemble # 正常安装
$ pip install --upgrade self-paced-ensemble # 如需更新
或者您可以通过克隆此仓库来安装SPE:
$ git clone https://github.com/ZhiningLiu1998/self-paced-ensemble.git
$ cd self-paced-ensemble
$ python setup.py install
需要以下依赖项:
- python (>=3.6)
- numpy (>=1.13.3)
- scipy (>=0.19.1)
- joblib (>=0.11)
- scikit-learn (>=0.24)
- imblearn (>=0.7.0)
- imbalanced-ensemble (>=0.1.3)
目录
背景
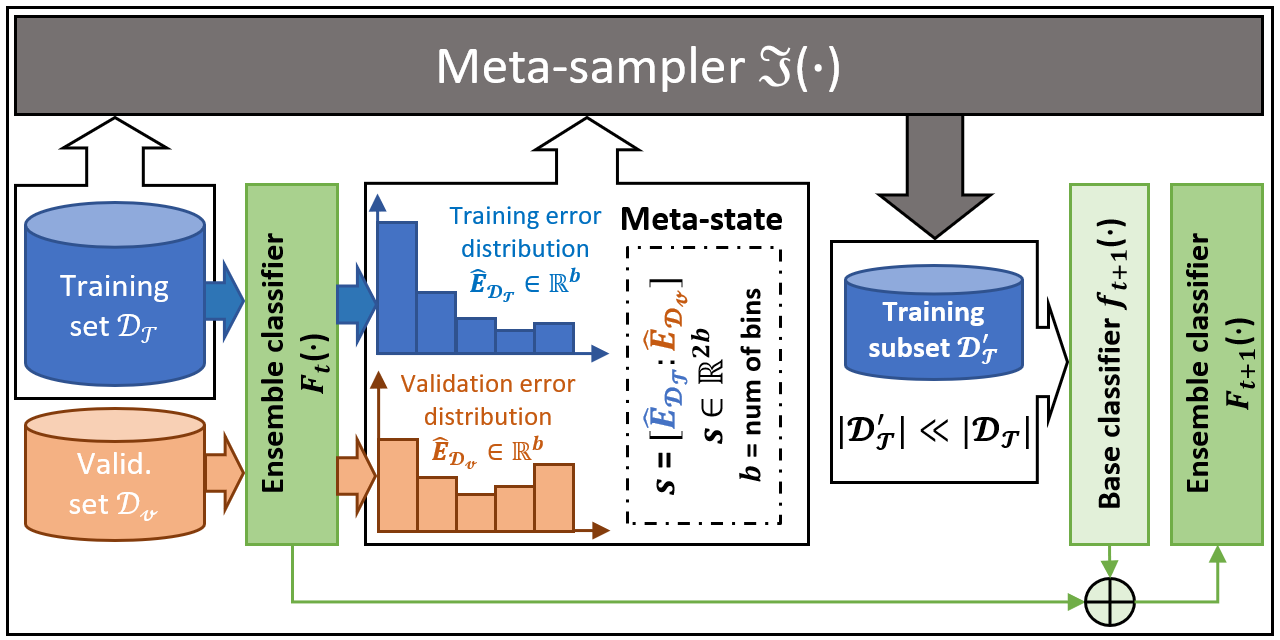
SPE在每次迭代中执行严格的平衡欠采样,因此计算效率非常高。此外,SPE不依赖于计算样本之间的距离来执行重采样。它可以轻松应用于缺乏明确定义的距离度量的数据集(例如具有分类特征/缺失值),无需任何修改。此外,作为一个通用的集成框架,我们的方法可以轻松适应大多数现有的学习方法(例如C4.5、SVM、GBDT和神经网络),以提高它们在不平衡数据上的性能。与现有的不平衡学习方法相比,SPE在大规模、噪声大且高度不平衡的数据集(例如不平衡比例大于100:1)上表现特别出色。这种数据在现实世界的工业应用中广泛存在。下图概述了SPE框架。
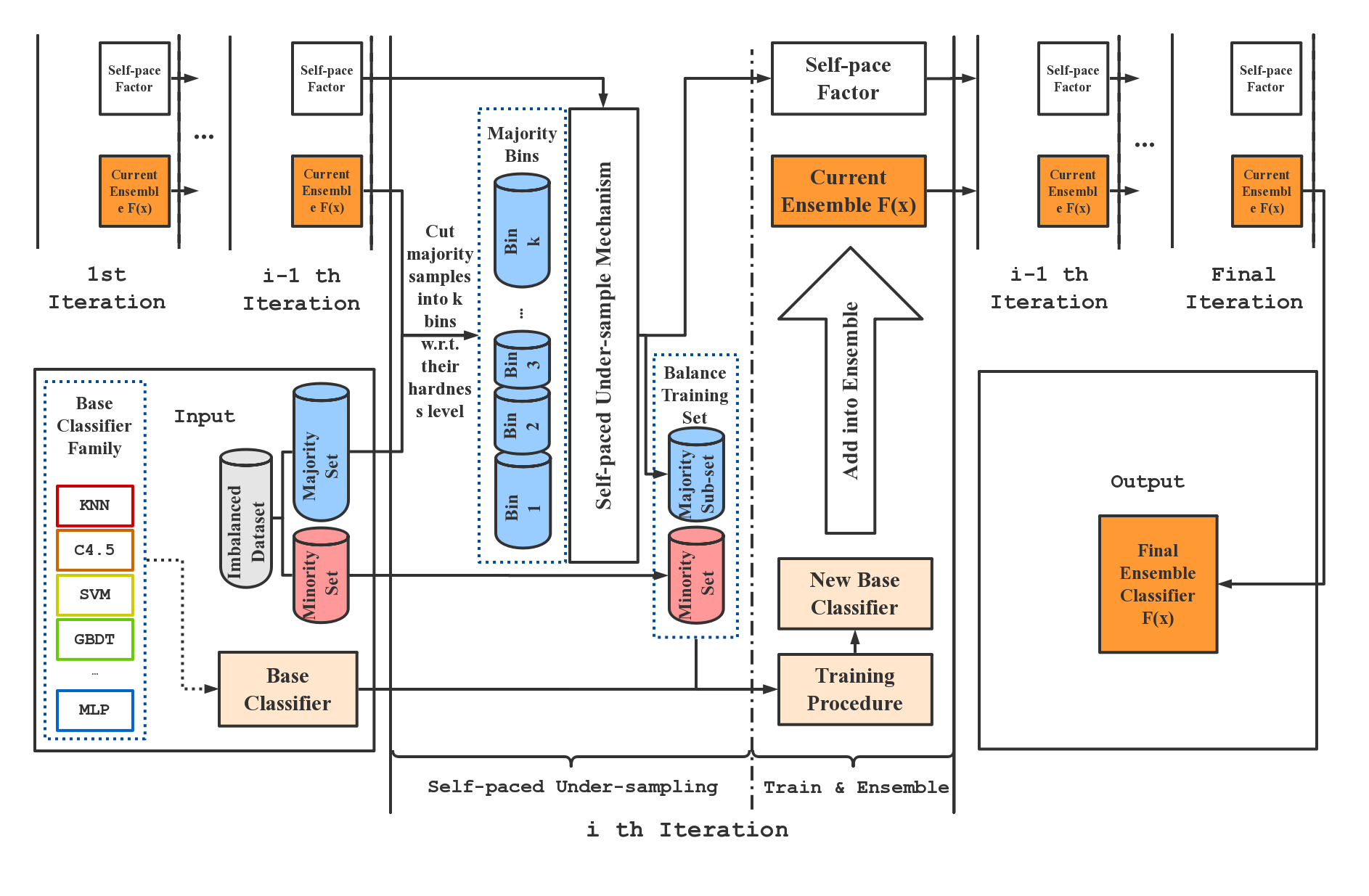
文档
我们的SPE实现可以与sklearn.ensemble分类器以非常相似的方式使用。SelfPacedEnsembleClassifier的详细文档可以在这里找到。
示例
您可以查看使用SPE的示例以获取更全面的使用示例。
API演示
from self_paced_ensemble import SelfPacedEnsembleClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
# 准备类别不平衡的训练和测试数据
X, y = make_classification(n_classes=2, random_state=42, weights=[0.1, 0.9])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.5, random_state=42)
# 训练SPE分类器
clf = SelfPacedEnsembleClassifier(
base_estimator=DecisionTreeClassifier(),
n_estimators=10,
).fit(X_train, y_train)
# 使用SPE分类器进行预测
clf.predict(X_test)
高级用法示例
保存和加载模型
我们建议使用joblib或pickle来保存和加载SPE模型,例如:
from joblib import dump, load
# 保存模型
dump(clf, filename='clf.joblib')
# 加载模型
clf = load('clf.joblib')
您也可以使用SPE提供的替代API:
from self_paced_ensemble.utils import save_model, load_model
# 保存模型
clf.save('clf.joblib') # 选项1
save_model(clf, 'clf.joblib') # 选项2
# 加载模型
clf = load_model('clf.joblib')
将SPE与其他方法进行比较
结果
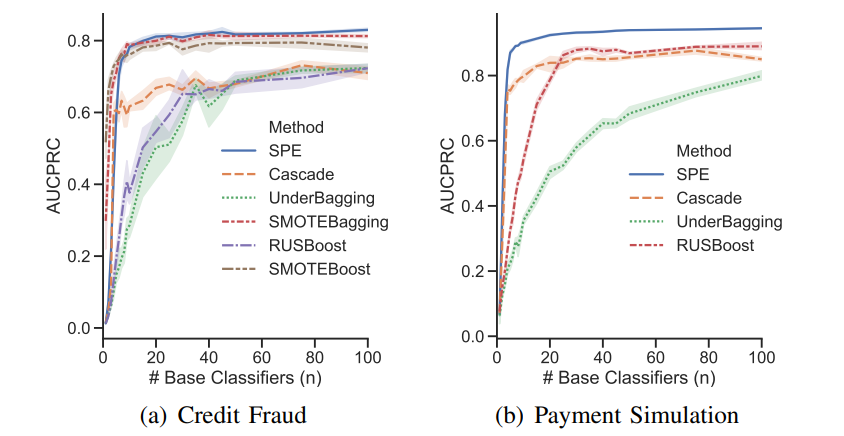
数据集链接: 信用卡欺诈, KDDCUP, 记录链接, 支付模拟。

SPE与传统重采样/集成方法在性能和计算效率方面的比较。
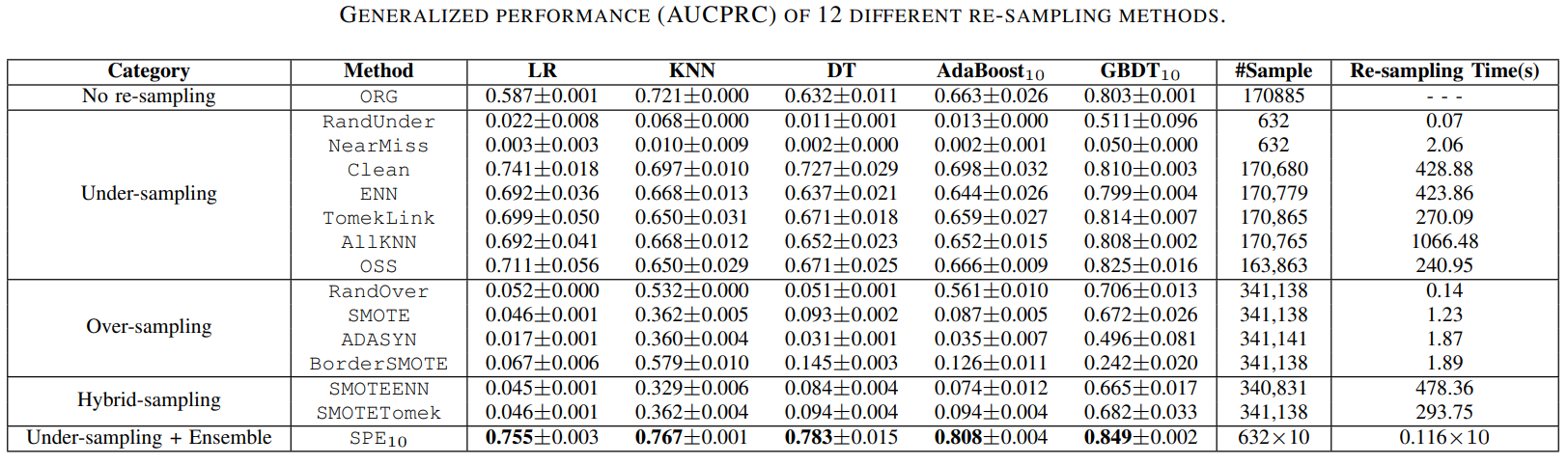
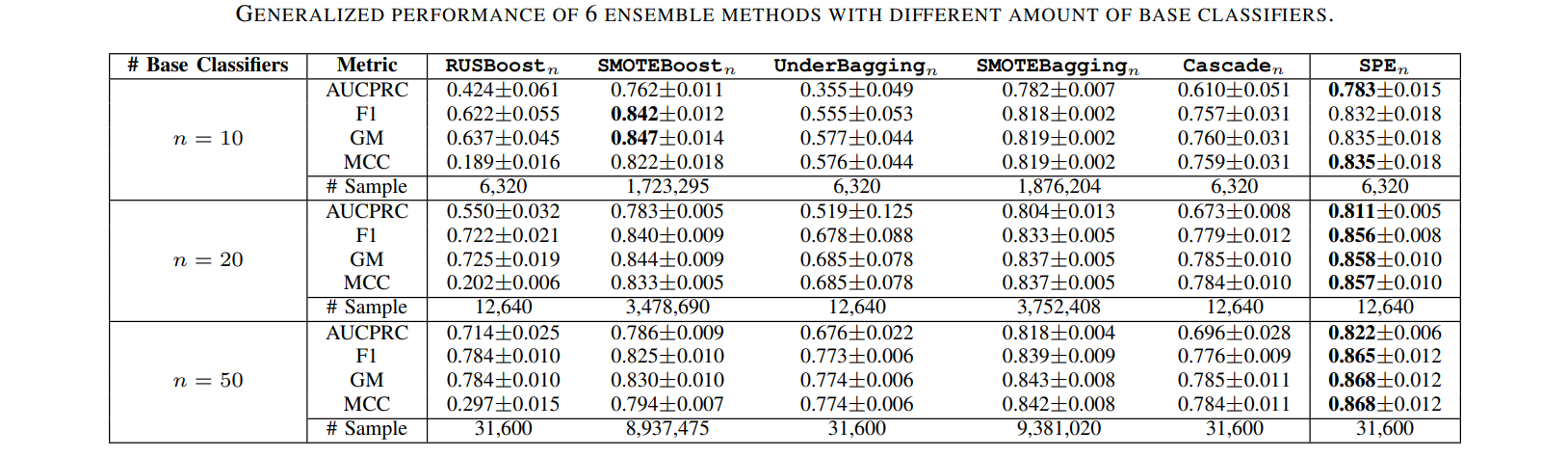
其他
本仓库包含:
- 自步调节集成(Self-paced Ensemble)的实现
- 5种基于集成的不平衡学习基线方法的实现
SMOTEBoost[1]SMOTEBagging[2]RUSBoost[3]UnderBagging[4]BalanceCascade[5]
- 基于重采样的不平衡学习基线方法的实现 [6]
- 额外的实验结果
注意: 其他集成和重采样方法的实现基于 imbalanced-ensemble 和 imbalanced-learn。
参考文献
| # | 参考文献 |
|---|---|
| [1] | N. V. Chawla, A. Lazarevic, L. O. Hall, and K. W. Bowyer, Smoteboost: Improving prediction of the minority class in boosting. in European conference on principles of data mining and knowledge discovery. Springer, 2003, pp. 107–119 |
| [2] | S. Wang and X. Yao, Diversity analysis on imbalanced data sets by using ensemble models. in 2009 IEEE Symposium on Computational Intelligence and Data Mining. IEEE, 2009, pp. 324–331. |
| [3] | C. Seiffert, T. M. Khoshgoftaar, J. Van Hulse, and A. Napolitano, "Rusboost: A hybrid approach to alleviating class imbalance," IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans, vol. 40, no. 1, pp. 185–197, 2010. |
| [4] | R. Barandela, R. M. Valdovinos, and J. S. Sanchez, "New applications´ of ensembles of classifiers," Pattern Analysis & Applications, vol. 6, no. 3, pp. 245–256, 2003. |
| [5] | X.-Y. Liu, J. Wu, and Z.-H. Zhou, "Exploratory undersampling for class-imbalance learning," IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 39, no. 2, pp. 539–550, 2009. |
| [6] | Guillaume Lemaître, Fernando Nogueira, and Christos K. Aridas. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. Journal of Machine Learning Research, 18(17):1–5, 2017. |
相关项目
查看 Zhining 的其他开源项目!







贡献者 ✨
感谢这些优秀的人 (表情符号说明):







本项目遵循all-contributors规范。欢迎任何形式的贡献!











