时间序列自监督学习综述:分类、进展与展望
时间序列数据广泛存在于各个领域,如金融、医疗、工业等。然而,获取大量带标签的时间序列数据往往成本高昂。为了充分利用海量无标签时间序列数据,自监督学习(Self-Supervised Learning, SSL)方法近年来备受关注。本文将全面综述时间序列自监督学习(SSL4TS)的最新研究进展。
时间序列自监督学习概述
自监督学习是一种无需人工标注就能从数据中学习有用表示的方法。其核心思想是构造预训练任务(pretext task),通过完成这些任务来学习数据的内在结构和语义信息。对于时间序列数据,典型的预训练任务包括重构输入序列、预测未来时间步、对比不同视图等。
相比于传统的监督学习方法,SSL4TS具有以下优势:
- 可以充分利用大量无标签数据
- 学习到的表示具有更好的泛化性
- 可以缓解标签稀缺和数据不平衡问题
- 提高下游任务的性能和数据效率
近年来,SSL4TS方法在时间序列分类、预测、异常检测等多个任务上取得了显著进展。本文将从生成式、对比式和对抗式三个角度系统地介绍主流SSL4TS方法。
SSL4TS方法分类
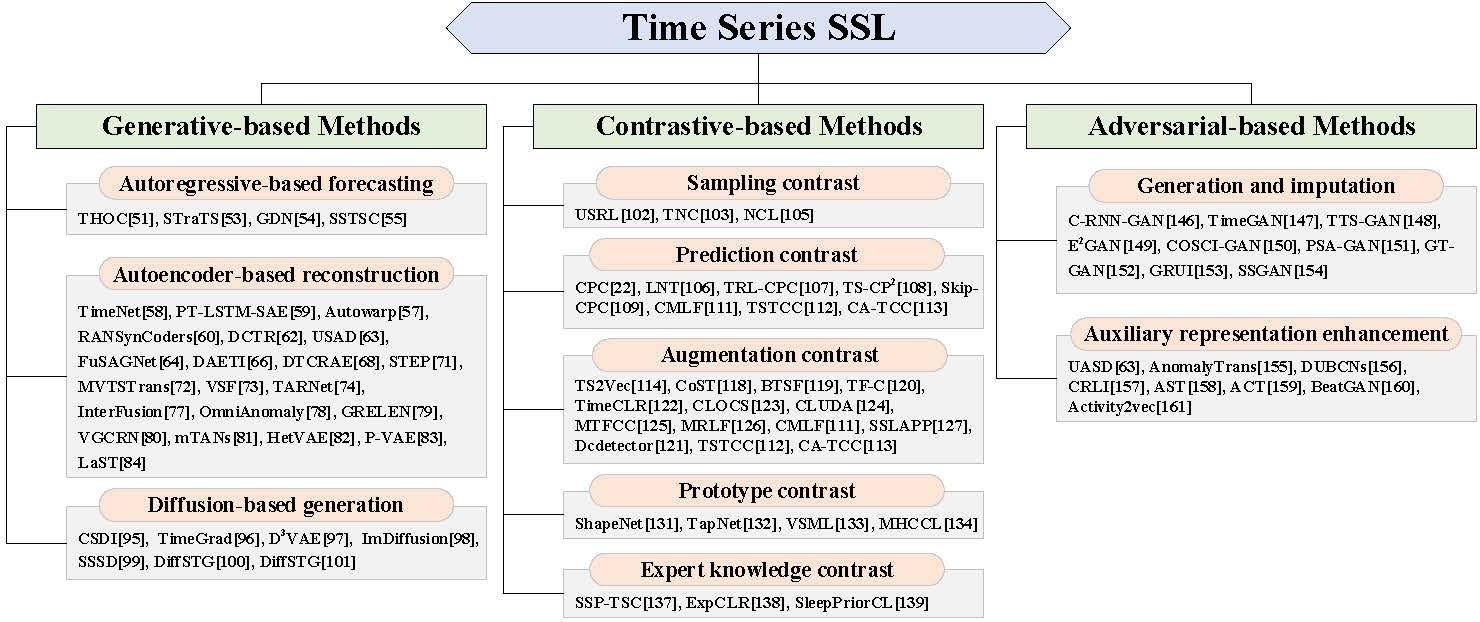
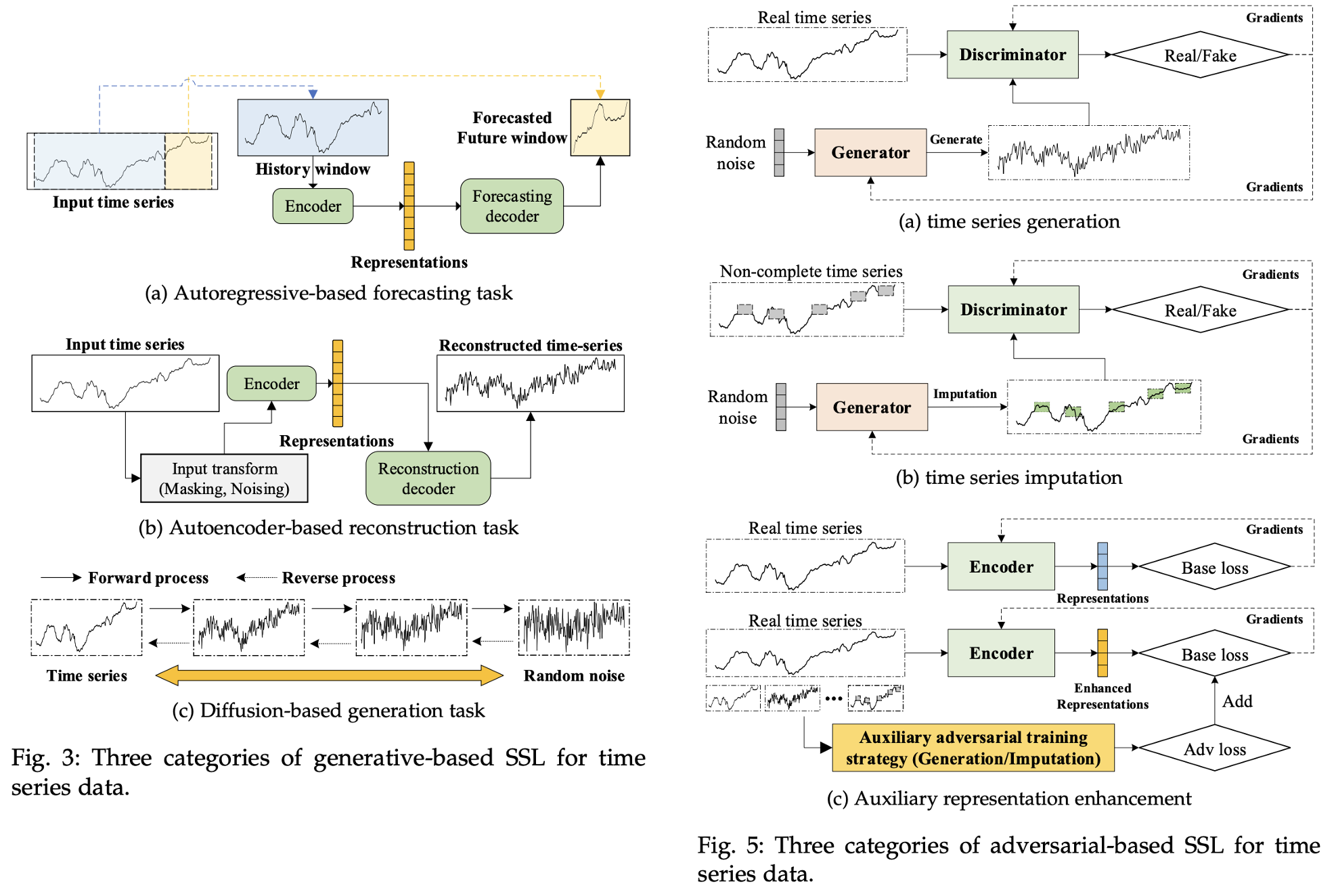
生成式方法
生成式SSL4TS方法通过重构或生成时间序列数据来学习表示。主要包括以下几类:
-
自回归预测:利用历史数据预测未来时间步。
例如,NeurIPS 2020的工作提出了时间层次一类神经网络进行异常检测。
-
自编码器重构:通过编码器-解码器结构重构输入序列。
代表性工作如KDD 2020的USAD,利用对抗训练的自编码器进行多变量时间序列异常检测。
-
扩散模型生成:利用扩散过程生成高质量时间序列样本。
如NeurIPS 2021的CSDI模型,用于概率时间序列插值。
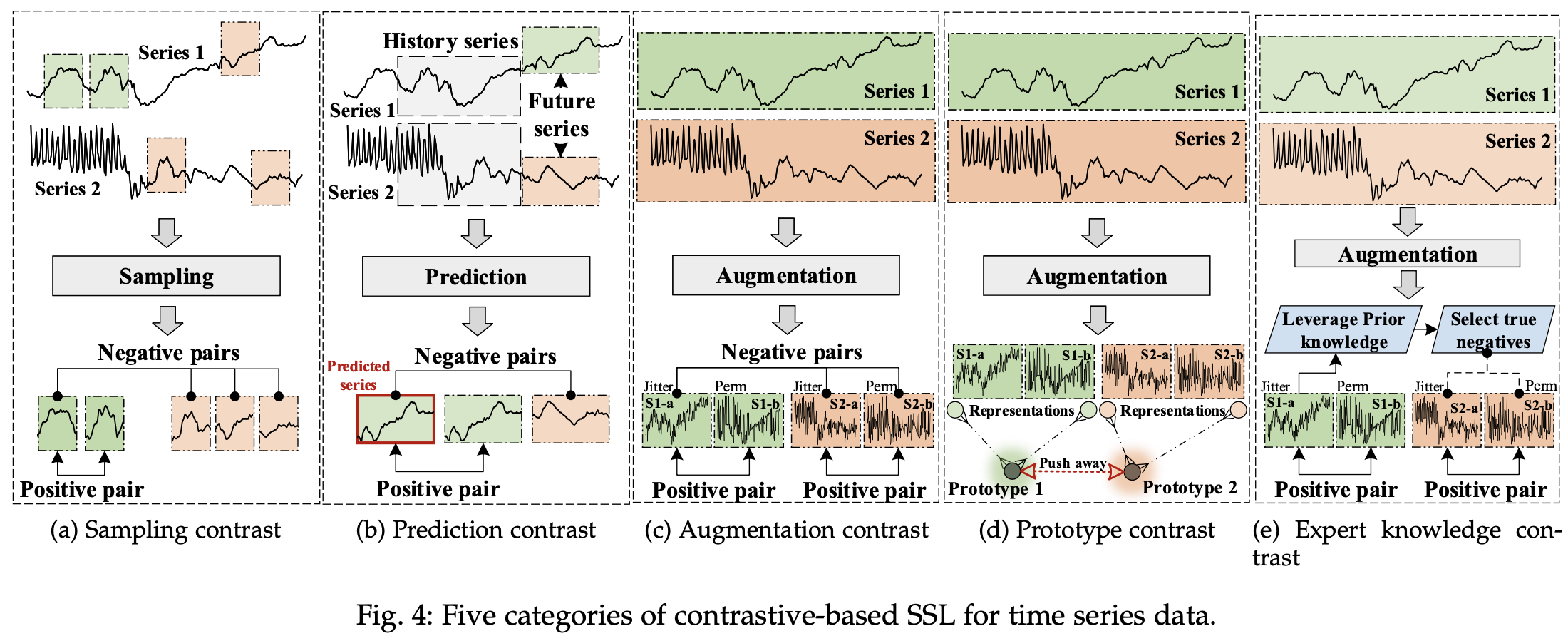
对比式方法
对比式SSL4TS方法通过对比不同视图或样本来学习判别性表示。主要包括:
-
采样对比:对比不同时间步或序列片段。
-
预测对比:预测未来时间步并进行对比学习。
-
增强对比:对比原始序列与增强后的序列。
-
原型对比:学习类别原型并与样本进行对比。
-
专家知识对比:利用领域知识指导对比学习。
对抗式方法
对抗式SSL4TS方法利用生成对抗网络(GAN)的思想构造预训练任务。主要包括:
-
时间序列生成与插值:生成高质量的合成时间序列数据。
-
辅助表示增强:通过对抗训练提升表示质量。
SSL4TS的应用
SSL4TS方法在多个时间序列分析任务中取得了显著进展,主要包括:
-
异常检测:如PSM、SMD等数据集上的异常检测任务。
-
预测:如ETT、Wind、Electricity等数据集上的预测任务。
-
分类与聚类:如HAR、UCR等数据集上的分类任务。
未来研究方向
尽管SSL4TS取得了显著进展,但仍存在一些挑战和机遇:
- 针对时间序列特性设计更有效的预训练任务
- 探索多模态时间序列的自监督学习方法
- 提高SSL4TS方法的可解释性
- 研究SSL4TS与迁移学习、元学习等的结合
- 将SSL4TS应用于更多实际场景
总结
本文系统地综述了时间序列自监督学习的最新进展,介绍了主流方法的分类、代表性工作及应用。SSL4TS作为一种有效利用无标签数据的学习范式,在多个时间序列分析任务中表现出色。未来,随着新技术的不断涌现,SSL4TS有望在更广泛的领域发挥重要作用。
🔗 更多相关资源请参考:Awesome-SSL4TS


















