TensorRT-LLM 后端简介
TensorRT-LLM 后端是一个专门为 Triton 推理服务器设计的后端,旨在高效部署和服务 TensorRT-LLM 模型。它结合了 NVIDIA TensorRT 的高性能深度学习推理能力和 TensorRT-LLM 框架对大型语言模型的优化,为开发者提供了一个强大的工具来部署最新的 LLM 模型。
主要特性
- 支持多种并行技术,包括张量并行、流水线并行和专家并行
- 提供 inflight batching 和 paged attention 等优化技术
- 支持多种解码策略,如 Top-k、Top-p、Beam Search 等
- 支持模型量化,可以显著降低内存占用和提高推理速度
- 多实例和多节点部署支持,可以充分利用硬件资源
- 与 Triton 无缝集成,提供统一的推理 API 和管理界面
快速入门
要开始使用 TensorRT-LLM 后端,您可以按照以下步骤操作:
- 更新 TensorRT-LLM 子模块:
git clone -b v0.11.0 https://github.com/triton-inference-server/tensorrtllm_backend.git
cd tensorrtllm_backend
git submodule update --init --recursive
git lfs install
git lfs pull
- 启动 Triton TensorRT-LLM 容器:
docker run --rm -it --net host --shm-size=2g \
--ulimit memlock=-1 --ulimit stack=67108864 --gpus all \
-v </path/to/tensorrtllm_backend>:/tensorrtllm_backend \
-v </path/to/engines>:/engines \
nvcr.io/nvidia/tritonserver:24.07-trtllm-python-py3
- 准备 TensorRT-LLM 引擎:
可以使用 TensorRT-LLM 提供的脚本来转换和构建模型引擎。以 GPT-2 模型为例:
cd /tensorrtllm_backend/tensorrt_llm/examples/gpt
# 下载权重
rm -rf gpt2 && git clone https://huggingface.co/gpt2-medium gpt2
pushd gpt2 && rm pytorch_model.bin model.safetensors && wget -q https://huggingface.co/gpt2-medium/resolve/main/pytorch_model.bin && popd
# 转换检查点
python3 convert_checkpoint.py --model_dir gpt2 \
--dtype float16 \
--tp_size 4 \
--output_dir ./c-model/gpt2/fp16/4-gpu
# 构建 TensorRT 引擎
trtllm-build --checkpoint_dir ./c-model/gpt2/fp16/4-gpu \
--gpt_attention_plugin float16 \
--remove_input_padding enable \
--paged_kv_cache enable \
--gemm_plugin float16 \
--output_dir /engines/gpt/fp16/4-gpu
- 准备模型仓库:
mkdir /triton_model_repo
cp -r /tensorrtllm_backend/all_models/inflight_batcher_llm/* /triton_model_repo/
- 修改模型配置:
使用提供的脚本填充模型配置文件中的参数:
ENGINE_DIR=/engines/gpt/fp16/4-gpu
TOKENIZER_DIR=/tensorrtllm_backend/tensorrt_llm/examples/gpt/gpt2
MODEL_FOLDER=/triton_model_repo
TRITON_MAX_BATCH_SIZE=4
INSTANCE_COUNT=1
MAX_QUEUE_DELAY_MS=0
MAX_QUEUE_SIZE=0
FILL_TEMPLATE_SCRIPT=/tensorrtllm_backend/tools/fill_template.py
DECOUPLED_MODE=false
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/ensemble/config.pbtxt triton_max_batch_size:${TRITON_MAX_BATCH_SIZE}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/preprocessing/config.pbtxt tokenizer_dir:${TOKENIZER_DIR},triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},preprocessing_instance_count:${INSTANCE_COUNT}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/tensorrt_llm/config.pbtxt triton_backend:tensorrtllm,triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},decoupled_mode:${DECOUPLED_MODE},engine_dir:${ENGINE_DIR},max_queue_delay_microseconds:${MAX_QUEUE_DELAY_MS},batching_strategy:inflight_fused_batching,max_queue_size:${MAX_QUEUE_SIZE}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/postprocessing/config.pbtxt tokenizer_dir:${TOKENIZER_DIR},triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},postprocessing_instance_count:${INSTANCE_COUNT},max_queue_size:${MAX_QUEUE_SIZE}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/tensorrt_llm_bls/config.pbtxt triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},decoupled_mode:${DECOUPLED_MODE},bls_instance_count:${INSTANCE_COUNT}
- 启动 Triton 服务:
python3 /tensorrtllm_backend/scripts/launch_triton_server.py --world_size=4 --model_repo=${MODEL_FOLDER}
- 发送推理请求:
可以使用 curl 命令或提供的客户端脚本来发送推理请求:
curl -X POST localhost:8000/v2/models/ensemble/generate -d '{"text_input": "What is machine learning?", "max_tokens": 20, "bad_words": "", "stop_words": ""}'
高级特性
多实例支持
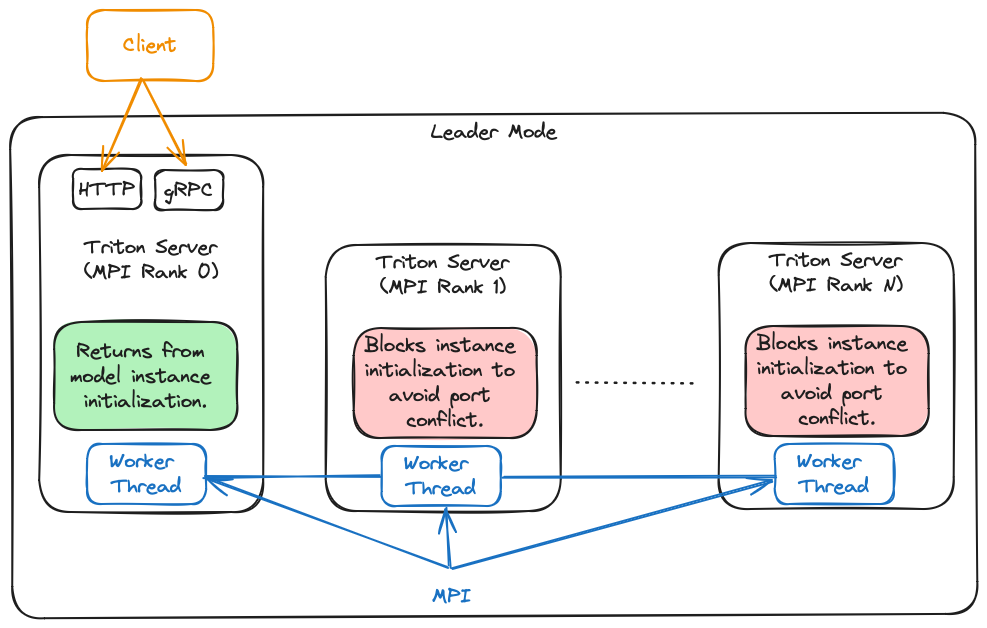
TensorRT-LLM 后端支持两种多实例运行模式:
- Leader 模式: 为每个 GPU 生成一个 Triton 服务器进程,其中 rank 0 进程作为leader。
- Orchestrator 模式: 生成一个作为协调器的 Triton 服务器进程,然后为每个模型需要的 GPU 生成一个 Triton 服务器进程。
多节点支持
TensorRT-LLM 后端支持跨多个节点部署模型,可以充分利用分布式计算资源。
模型并行
支持张量并行、流水线并行和专家并行等多种并行技术,可以有效地将大型模型分布在多个 GPU 上。
解码策略
提供多种解码策略,包括 Top-k、Top-p、Beam Search 和 Medusa 等,可以根据需求选择最适合的生成方式。
量化支持
支持多种量化技术,如 INT8、INT4 等,可以显著减小模型大小并提高推理速度。
结论
TensorRT-LLM 后端为在 Triton 推理服务器上部署大型语言模型提供了一个强大而灵活的解决方案。通过结合 TensorRT 的高性能推理能力和 TensorRT-LLM 的优化技术,它能够实现高效的模型服务。无论是单机多 GPU 还是多节点部署,TensorRT-LLM 后端都能够提供出色的性能和可扩展性。对于需要在生产环境中部署最新 LLM 模型的开发者和企业来说,TensorRT-LLM 后端是一个值得考虑的选择。