
YOLOv3:实时目标检测算法的革新者
YOLOv3(You Only Look Once version 3)是由Joseph Redmon和Ali Farhadi于2018年提出的一种实时目标检测算法,它在YOLOv2的基础上做出了多项改进,成为计算机视觉领域的重要里程碑。本文将全面介绍YOLOv3的原理、特点及应用。
YOLOv3的原理
YOLOv3采用单阶段检测方法,将目标检测问题转化为回归问题。它使用单个神经网络直接从完整图像预测边界框和类别概率。这种端到端的方法使得YOLOv3能够以极快的速度进行实时目标检测。
YOLOv3的网络结构主要由以下几部分组成:
-
主干网络:采用Darknet-53作为特征提取网络,它包含53个卷积层,并引入了残差连接。
-
特征金字塔:使用类似FPN(Feature Pyramid Network)的结构,从不同尺度提取特征,以更好地检测不同大小的目标。
-
预测层:在3个不同尺度上进行预测,每个尺度预测3种不同大小的边界框。
-
损失函数:使用二元交叉熵损失进行分类,使用均方误差损失进行边界框回归。
YOLOv3的主要特点
-
速度快:YOLOv3在保持高精度的同时,能够达到实时检测的速度。在Titan X GPU上,YOLOv3可以以30 FPS的速度处理416×416的图像。
-
精度高:相比YOLOv2,YOLOv3在COCO数据集上的mAP@0.5指标提高了2.7%。
-
多尺度预测:通过在3个不同尺度上进行预测,YOLOv3显著提高了对小目标的检测能力。
-
更强大的特征提取器:采用Darknet-53作为主干网络,性能优于ResNet-101,速度快于ResNet-152。
-
更好的分类器:使用逻辑回归代替softmax,更适合处理多标签分类问题。
YOLOv3的应用场景
YOLOv3凭借其快速、准确的特点,在多个领域得到了广泛应用:
-
自动驾驶:实时检测道路上的车辆、行人和交通标志。
-
安防监控:快速识别监控视频中的可疑人员或物品。
-
工业检测:在生产线上实时检测产品缺陷。
-
医疗影像:辅助医生快速定位X光片或CT扫描中的异常区域。
-
零售业:实现无人商店中的商品识别和顾客行为分析。
YOLOv3的实现
要使用YOLOv3进行目标检测,可以按照以下步骤操作:
- 安装依赖:
pip install opencv-python
pip install torch
pip install ultralytics
- 加载预训练模型:
import torch
model = torch.hub.load("ultralytics/yolov3", "yolov3")
- 进行目标检测:
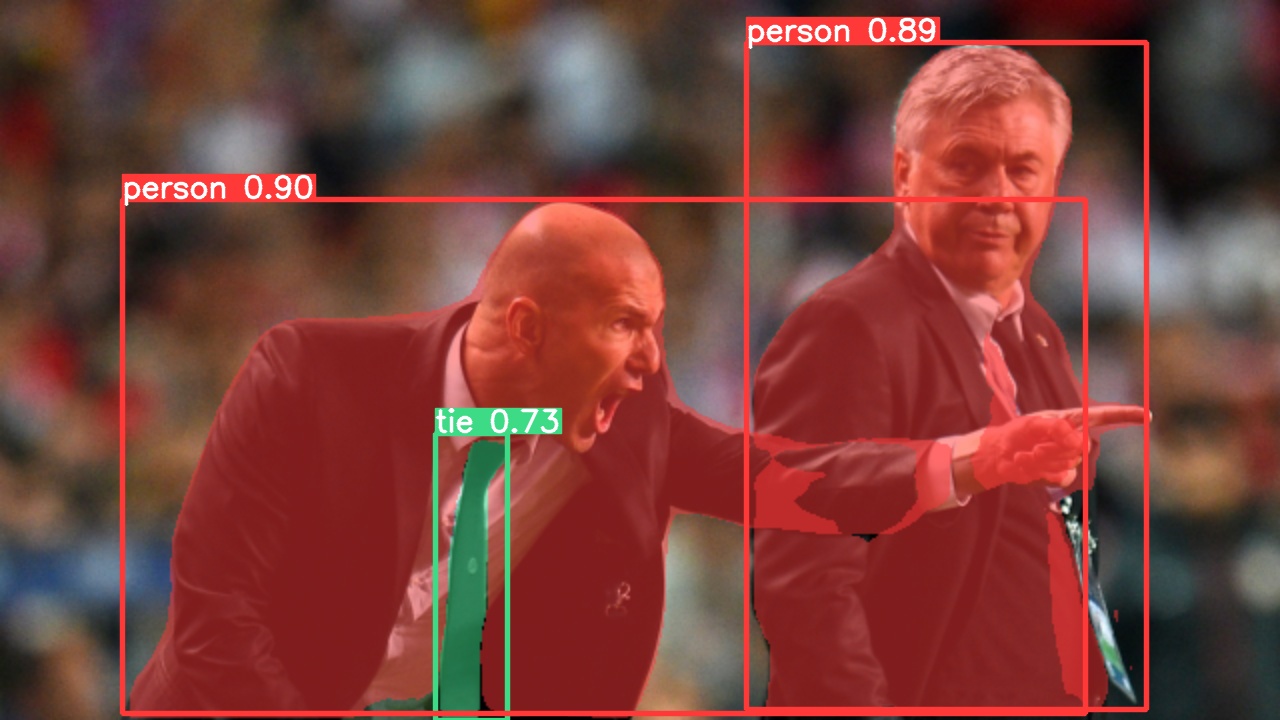
img = "https://ultralytics.com/images/zidane.jpg"
results = model(img)
results.print() # 打印检测结果
results.show() # 显示检测结果图像
YOLOv3的局限性
尽管YOLOv3在多个方面都有显著改进,但它仍然存在一些局限性:
-
对密集目标的检测效果不佳:当图像中存在大量小而密集的目标时,YOLOv3的性能可能会下降。
-
对严重遮挡目标的检测不够理想:当目标被严重遮挡时,YOLOv3可能难以准确定位和分类。
-
对非常规形状目标的适应性不足:YOLOv3主要针对矩形边界框进行优化,对于非矩形目标的检测效果可能不够理想。
YOLOv3之后的发展
自YOLOv3发布以来,YOLO系列算法不断发展,出现了YOLOv4、YOLOv5等新版本。这些新版本在YOLOv3的基础上进行了进一步优化,在速度和精度上都有所提升。然而,YOLOv3凭借其优秀的性能和广泛的应用基础,仍然是许多实际项目中的首选算法之一。
结语
YOLOv3作为实时目标检测算法的代表作之一,在计算机视觉领域产生了深远的影响。它不仅推动了目标检测技术的发展,还为众多实际应用提供了可靠的解决方案。随着深度学习技术的不断进步,我们可以期待未来会出现更加强大的目标检测算法,为人工智能的发展贡献力量。
无论您是研究人员、开发者还是对计算机视觉感兴趣的爱好者,深入了解YOLOv3都将为您打开一扇通向先进目标检测技术的大门。让我们共同期待YOLO系列算法的未来发展,见证人工智能技术改变世界的力量。















