
使用深度学习和几何方法进行3D边界框估计
如果有兴趣,欢迎加入讨论该论文、解决问题等的Slack工作区!点击此链接加入。
简介
这是该论文的PyTorch实现。
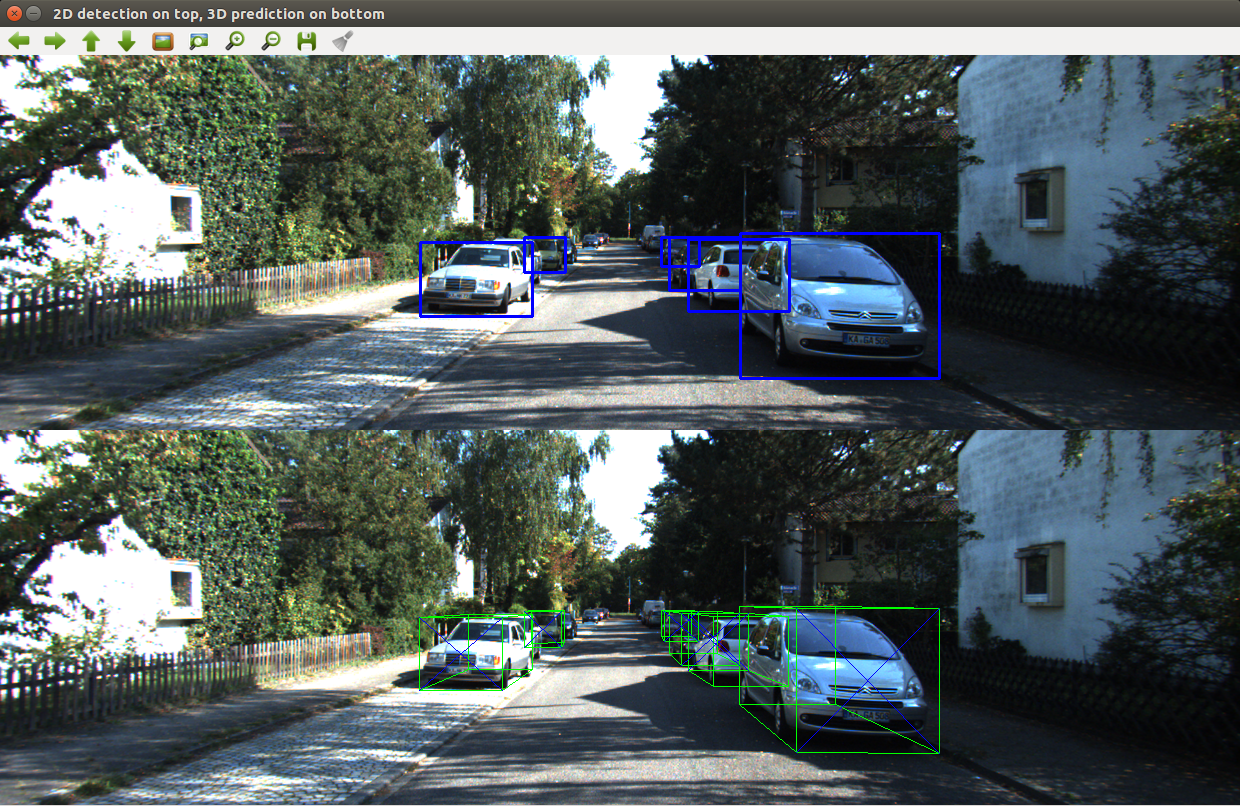
目前,每帧处理大约需要0.4秒,具体取决于检测到的物体数量。速度优化将很快推出。以下是当前最快的效果:

要求
- PyTorch
- Cuda
- OpenCV >= 3.4.3
使用方法
下载权重文件:
cd weights/
./get_weights.sh
这将下载3D边界框网络的预训练权重以及官方yolo来源的YOLOv3权重。
查看所有选项:
python Run.py --help
遍历默认目录(eval/image_2/)中的所有图像,可选择同时绘制2D边界框。按空格键继续下一张图像,按任意其他键退出。
python Run.py [--show-yolo]
注意:请参阅训练部分了解从哪里下载数据
还提供了一个脚本来下载./eval/video中的默认Kitti视频。或者,下载任何Kitti视频及其对应的校准文件,并使用--image-dir和--cal-dir指定获取帧的位置。
python Run.py --video [--hide-debug]
训练
首先,必须从Kitti下载数据。 下载左侧彩色图像、训练标签和相机校准矩阵。总共约13GB。 将下载的文件解压到Kitti/目录中。
python Train.py
默认情况下,每10个epoch在weights/目录保存一次模型。 每10个批次打印一次损失。损失不应收敛到0!方向的损失函数驱动到-1,因此预期会出现负损失。需要调整的超参数是alpha和w(见论文)。我在仅10个epoch后就获得了不错的结果,但训练脚本将运行到100个epoch。
工作原理
PyTorch神经网络接收224x224大小的图像,并预测该物体相对于类别平均值的方向和相对尺寸。因此,另一个神经网络必须给出2D边界框和物体类别。我选择通过OpenCV使用YOLOv3。 利用方向、尺寸和2D边界框,计算3D位置,然后将其投影回图像上。
做出了2个关键假设:
- 2D边界框非常紧密地包围物体
- 物体的俯仰角和横滚角约为0(适用于道路上的汽车)
未来目标
- 在Kitti数据集上训练自定义YOLO网络
- 某种姿态可视化(ROS?)











