
YOLOv8 TensorRT C++:高性能目标检测、语义分割和姿态估计实现
随着计算机视觉技术的快速发展,YOLOv8作为目前最先进的目标检测算法之一,以其卓越的性能和灵活性备受关注。而TensorRT作为NVIDIA推出的高性能深度学习推理优化器和运行时环境,能够显著提升模型在GPU上的推理速度。本文将详细介绍一个将YOLOv8与TensorRT结合的C++实现项目,该项目不仅支持目标检测,还扩展到语义分割和人体姿态估计等多种计算机视觉任务。
项目概述
YOLOv8-TensorRT-CPP项目由开发者Cyrus Behroozi在GitHub上开源,旨在提供一种高效的方法,使用TensorRT C++ API在GPU上运行YOLOv8推理。该项目支持多种视觉任务,包括:
- 目标检测
- 语义分割
- 人体姿态估计
项目的核心优势在于其高性能和灵活性。通过利用TensorRT的优化能力,该实现可以显著提升YOLOv8模型的推理速度,同时保持较高的精度。
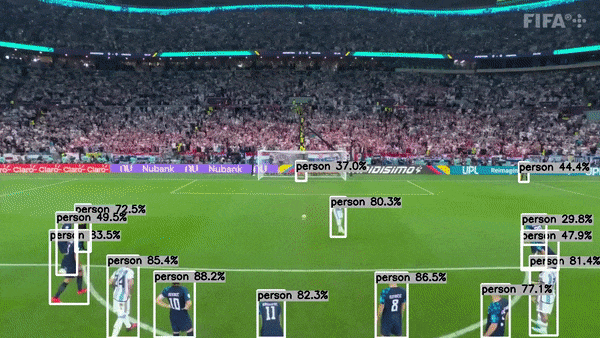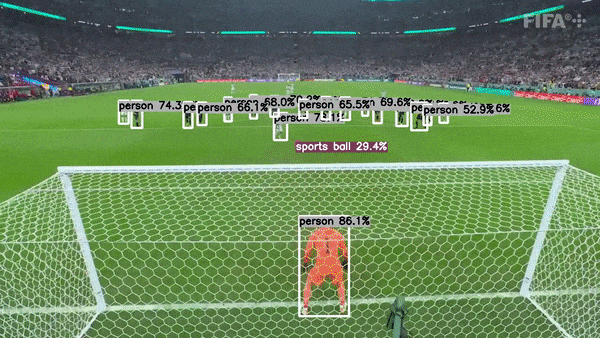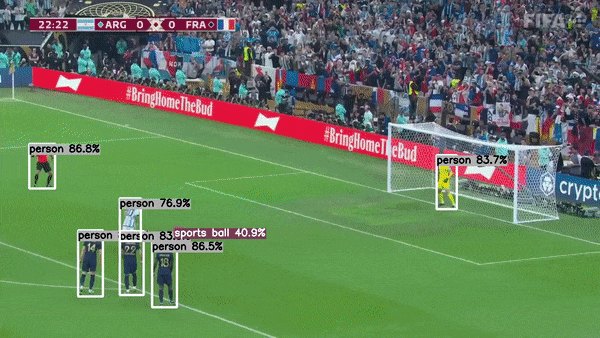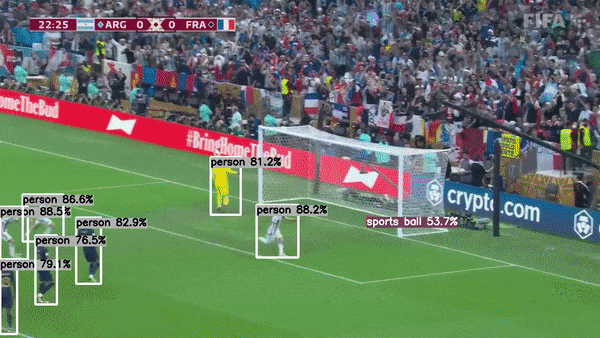
主要特性
-
多任务支持:项目不仅支持传统的目标检测任务,还扩展到语义分割和人体姿态估计,满足多样化的计算机视觉应用需求。
-
高性能推理:通过使用TensorRT优化,项目实现了GPU上的高速推理,大幅提升了模型的运行效率。
-
C++实现:使用C++编写,提供了更接近硬件的性能优化可能,同时保持了良好的跨平台兼容性。
-
灵活的模型转换:提供了从PyTorch模型到ONNX格式的转换脚本,简化了模型部署流程。
-
丰富的运行选项:支持图像和视频推理,以及实时的网络摄像头推理,满足不同场景的应用需求。
-
精度选项:支持FP32、FP16和INT8等多种精度模式,用户可以根据需求在性能和精度之间进行权衡。
-
详细的性能基准测试:项目提供了在不同硬件和精度设置下的性能基准,帮助用户了解和优化模型性能。
技术细节
环境要求
项目主要在Ubuntu 20.04和22.04上进行了测试,目前不支持Windows平台。主要的环境要求包括:
- CUDA >= 12.0
- cuDNN >= 8
- OpenCV >= 4.8(需要CUDA支持)
- TensorRT >= 10.0
安装与配置
-
克隆项目仓库:
git clone https://github.com/cyrusbehr/YOLOv8-TensorRT-CPP --recursive -
安装必要的依赖:
sudo apt install build-essential python3-pip pip3 install cmake ultralytics -
编译OpenCV(带CUDA支持)。
-
下载并配置TensorRT 10。
模型转换
项目提供了从PyTorch模型到ONNX格式的转换脚本:
- 从官方YOLOv8仓库下载所需的模型。
- 使用提供的转换脚本:
python3 pytorch2onnx.py --pt_path <path to your pt file>
项目编译
mkdir build
cd build
cmake ..
make -j
运行推理
项目提供了多种运行选项:
-
基准测试:
./benchmark --model /path/to/your/onnx/model.onnx --input /path/to/your/benchmark/image.png -
图像推理:
./detect_object_image --model /path/to/your/onnx/model.onnx --input /path/to/your/image.jpg -
实时视频推理:
./detect_object_video --model /path/to/your/onnx/model.onnx --input 0
性能优化
项目提供了详细的性能基准测试结果,以下是在NVIDIA GeForce RTX 3080笔记本GPU上,使用640x640 BGR图像和FP16精度的测试结果:
| 模型 | 总时间 | 预处理时间 | 推理时间 | 后处理时间 |
|---|---|---|---|---|
| yolov8n | 3.613 ms | 0.081 ms | 1.703 ms | 1.829 ms |
| yolov8n-pose | 2.107 ms | 0.091 ms | 1.609 ms | 0.407 ms |
| yolov8n-seg | 15.194 ms | 0.109 ms | 2.732 ms | 12.353 ms |
对于yolov8x模型,项目还提供了不同精度设置下的性能对比:
| 精度 | 总时间 | 预处理时间 | 推理时间 | 后处理时间 |
|---|---|---|---|---|
| FP32 | 25.819 ms | 0.103 ms | 23.763 ms | 1.953 ms |
| FP16 | 10.147 ms | 0.083 ms | 7.677 ms | 2.387 ms |
| INT8 | 7.32 ms | 0.103 ms | 4.698 ms | 2.519 ms |
这些基准测试结果显示,通过使用FP16和INT8精度,可以显著提升模型的推理速度。特别是对于yolov8x模型,从FP32到FP16的转换可以将总推理时间缩短约60%,而使用INT8精度则可以进一步将时间缩短到FP32的约28%。
INT8量化
为了进一步提高推理速度,项目支持INT8量化。然而,使用INT8精度可能会导致一定程度的精度损失。要启用INT8推理,需要遵循以下步骤:
-
准备校准数据集(建议使用1000+张图像)。
-
运行推理时添加额外的命令行参数:
--precision INT8 --calibration-data /path/to/your/calibration/data -
如果遇到内存不足的问题,可以通过减小
Options.calibrationBatchSize来解决。
调试与优化
对于在创建TensorRT引擎文件时遇到的问题,项目提供了详细的调试建议。通过修改libs/tensorrt-cpp-api/src/engine.cpp中的日志级别,可以获得更多关于构建过程的信息。
此外,项目还指出了一个待优化的点:需要使用CUDA内核来改进后处理时间。这为有兴趣进一步优化项目性能的开发者提供了一个切入点。
应用场景与前景
YOLOv8-TensorRT-CPP项目的应用前景广泛,可以在多个领域发挥重要作用:
-
智能安防:高效的目标检测和人体姿态估计可用于视频监控系统,提高安全监控的效率和准确性。
-
自动驾驶:实时的目标检测和语义分割对自动驾驶车辆的环境感知至关重要。
-
工业自动化:在工业生产线上,可用于质量控制、缺陷检测等任务。
-
增强现实(AR):快速的人体姿态估计可以应用于AR应用,提供更自然的人机交互体验。
-
零售分析:通过目标检测和人体姿态估计,可以分析店内顾客行为,优化商品陈列和店面布局。
-
医疗影像分析:虽然需要进一步的特定领域训练,但该项目的架构可以应用于医疗影像的快速分析和诊断辅助。
-
体育分析:人体姿态估计功能可用于运动员动作分析,帮助改善训练效果和预防伤害。
总结与展望
YOLOv8-TensorRT-CPP项目为计算机视觉任务提供了一个高效、灵活的实现方案。通过结合YOLOv8的先进算法和TensorRT的优化能力,该项目在保持高精度的同时,显著提升了推理速度。这使得它特别适合需要实时处理的应用场景。

然而,项目仍有进一步优化的空间,特别是在后处理阶段的性能提升上。未来的发展方向可能包括:
- 实现CUDA内核来优化后处理时间。
- 扩展对更多YOLOv8变体和任务的支持。
- 提供更多的预训练模型和应用示例。
- 改进INT8量化过程,以在保持高推理速度的同时最小化精度损失。
- 探索在边缘设备上的部署可能性,如NVIDIA Jetson系列。
对于有兴趣深入了解或贡献该项目的开发者,项目的GitHub仓库提供了详细的文档和指南。通过不断的优化和社区贡献,YOLOv8-TensorRT-CPP项目有潜力成为计算机视觉应用开发的重要工具,推动高性能视觉AI在各个领域的应用和创新。
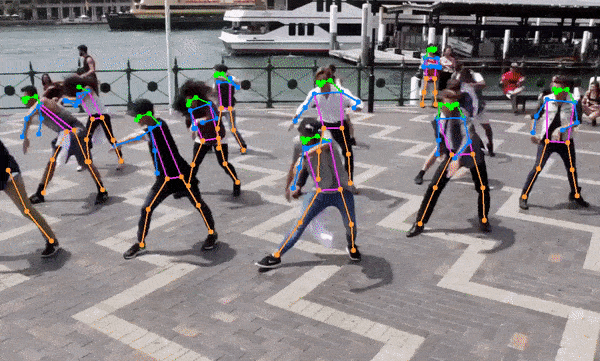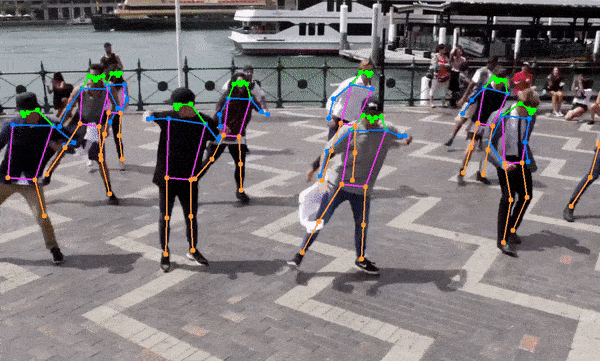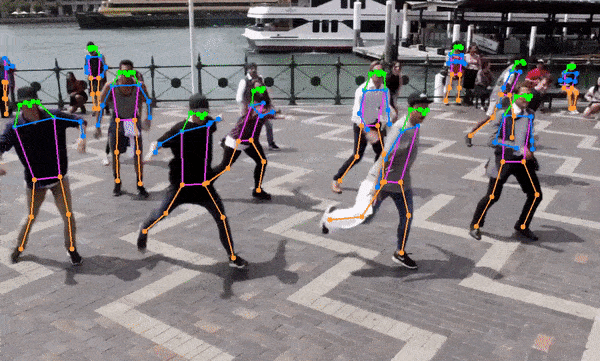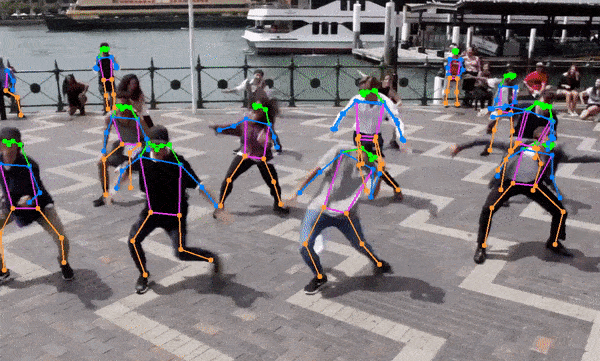
总的来说,YOLOv8-TensorRT-CPP项目展示了深度学习模型优化和高效部署的重要性和可能性。随着AI技术在各行各业的深入应用,类似的高性能实现将在推动实时、高效的AI应用落地方面发挥越来越重要的作用。🚀🔬🖥️


















