
ZenML: 连接数据科学和运维的桥梁
在当今的机器学习领域,将数据科学团队的工作成果顺利部署到生产环境中仍然是一个巨大的挑战。ZenML作为一个开源的MLOps框架,正是为了解决这一问题而生。它旨在成为数据科学和运维之间的桥梁,让机器学习项目从实验到生产的过程变得更加顺畅。
🚀 简单易用的MLOps框架
ZenML的核心理念是让MLOps变得简单。它允许数据科学家和ML工程师只需对现有的Python函数进行最小的代码更改,就能创建标准化的机器学习管道。例如:
from zenml import pipeline, step
@step
def load_data() -> dict:
training_data = [[1, 2], [3, 4], [5, 6]]
labels = [0, 1, 0]
return {'features': training_data, 'labels': labels}
@step
def train_model(data: dict) -> None:
total_features = sum(map(sum, data['features']))
total_labels = sum(data['labels'])
print(f"Trained model using {len(data['features'])} data points. "
f"Feature sum is {total_features}, label sum is {total_labels}")
@pipeline
def simple_ml_pipeline():
dataset = load_data()
train_model(dataset)
if __name__ == "__main__":
simple_ml_pipeline()
只需添加@step和@pipeline装饰器,就可以将普通的Python函数转换为ZenML管道的组件。这种简单的语法让数据科学家可以专注于算法和模型,而不必过多关注基础设施的复杂性。
🌐 跨云平台和工具的兼容性
ZenML的另一大优势是其强大的兼容性。无论你使用AWS、GCP、Azure,还是Airflow、Kubeflow等工具,ZenML都能无缝适配。这意味着你可以在不同的云平台和MLOps工具之间自由切换,而无需修改代码。
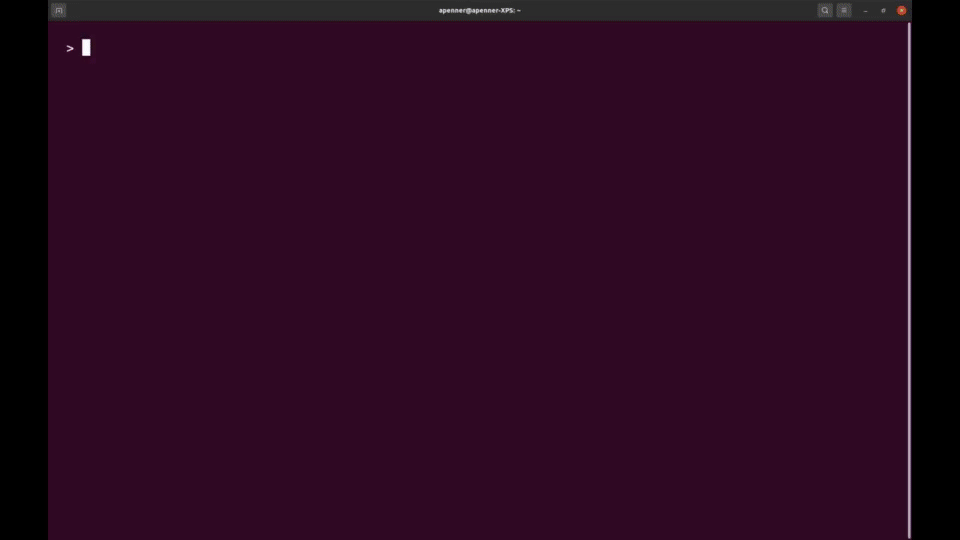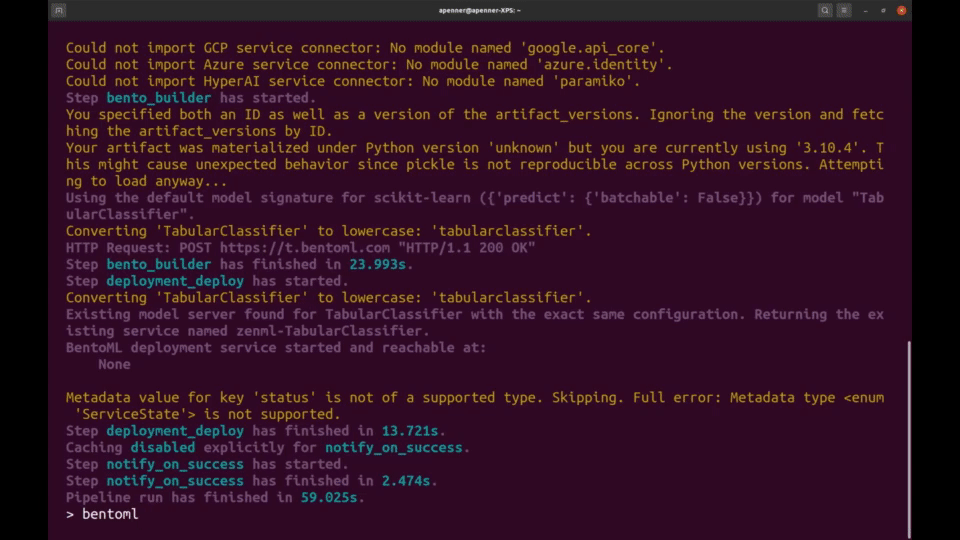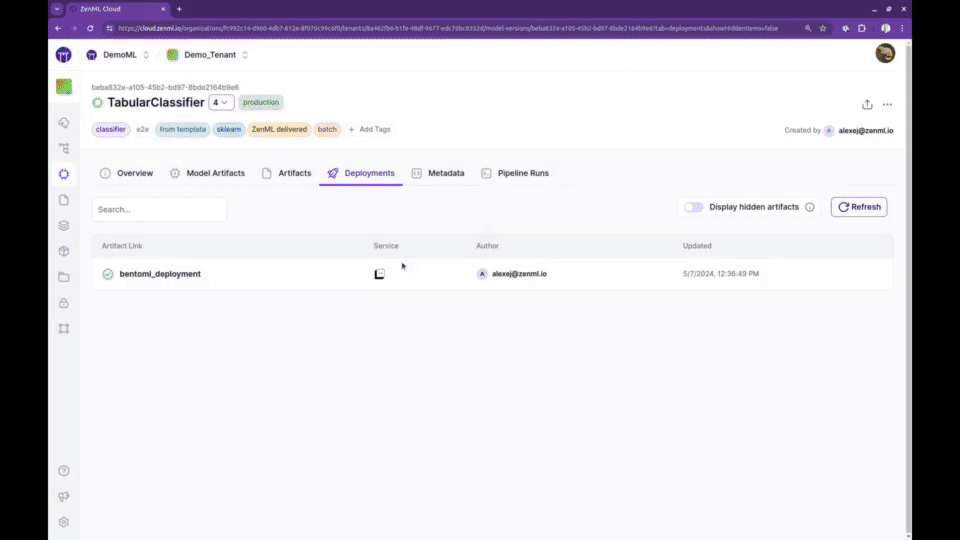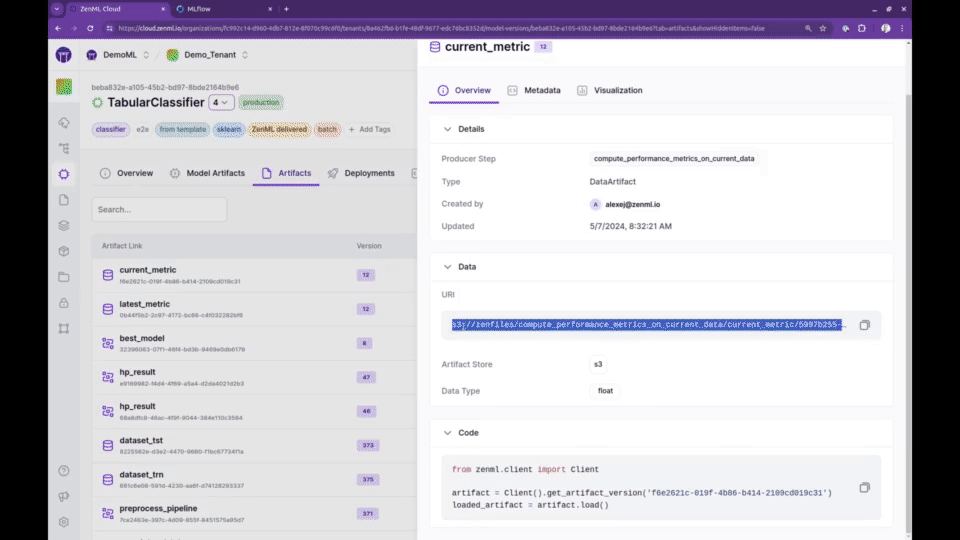
🛠️ 轻松配置MLOps基础设施
ZenML提供了多种方式来帮助团队快速搭建MLOps基础设施:
-
一键部署: 通过ZenML的dashboard或CLI命令,可以在选定的云提供商上一键部署完整的MLOps堆栈。
zenml stack deploy --provider aws -
注册现有基础设施: 如果已经有了必要的基础设施,可以使用ZenML的堆栈向导轻松注册:
zenml stack register <STACK_NAME> --provider aws -
自定义资源配置: 对于特定的工作负载,ZenML允许精细化控制计算资源:
from zenml.config import ResourceSettings, DockerSettings @step( settings={ "resources": ResourceSettings(memory="16GB", gpu_count="1", cpu_count="8"), "docker": DockerSettings(parent_image="pytorch/pytorch:1.12.1-cuda11.3-cudnn8-runtime") } ) def training(...): ...
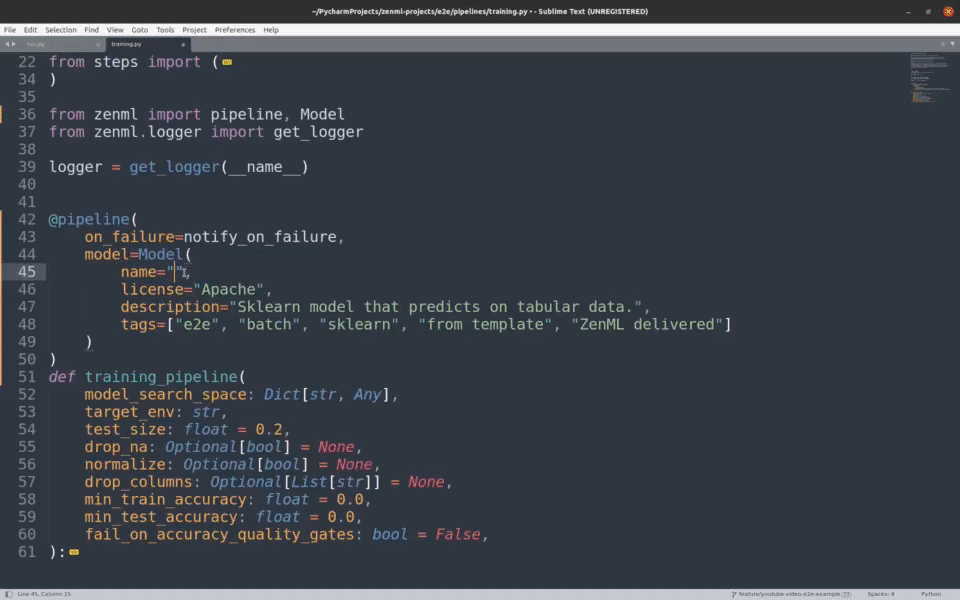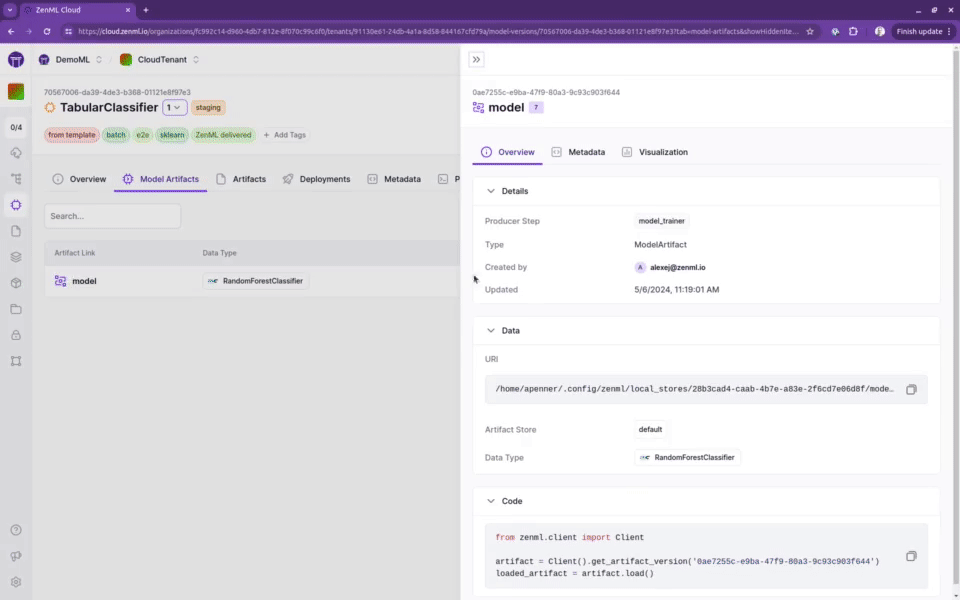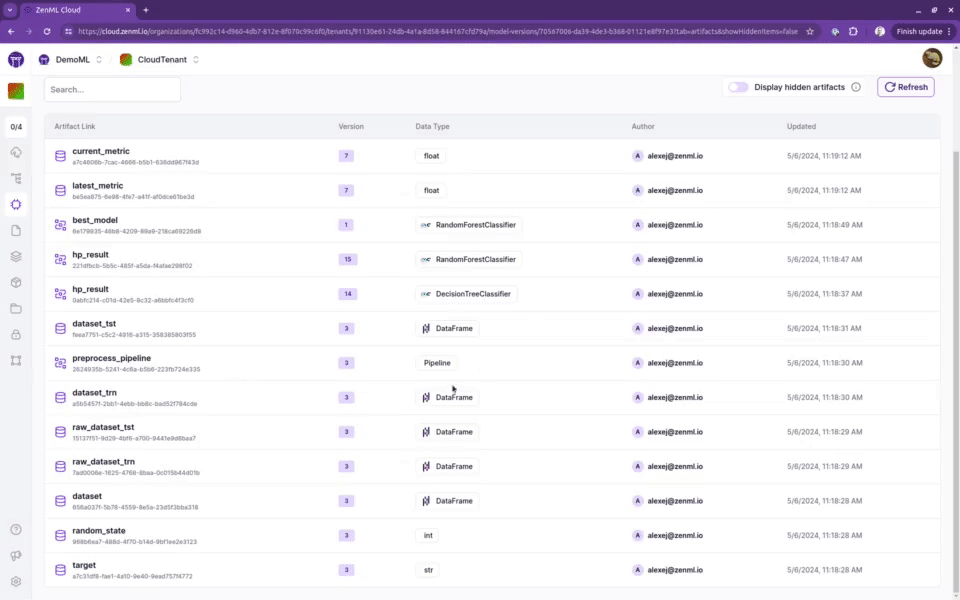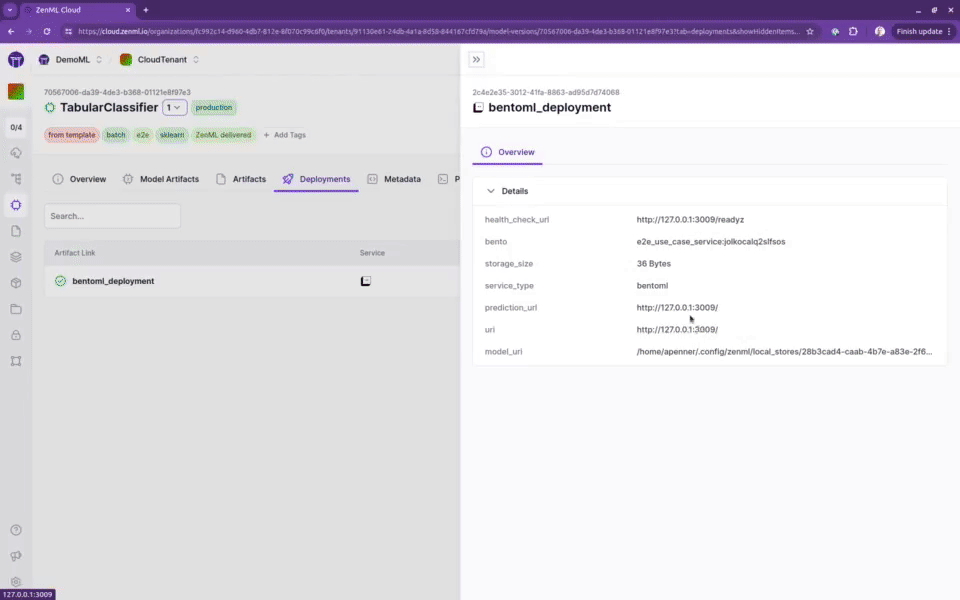
📊 全面的模型和管道追踪
ZenML提供了强大的模型、管道和工件追踪功能。这使得团队可以清晰地了解每个模型的生产过程:由谁生产、在什么时间、使用什么数据、基于哪个版本的代码等。这不仅保证了完全的可重现性,也满足了审计的需求。
from zenml import Model
@step(model=Model(name="classification"))
def trainer(training_df: pd.DataFrame) -> Annotated["model", torch.nn.Module]:
...
🔌 丰富的集成生态系统
ZenML不仅提供了核心的MLOps功能,还集成了许多流行的机器学习工具和服务。例如,你可以轻松地将MLflow用于实验跟踪,使用BentoML进行模型部署,或者通过Slack接收警报:
from bentoml._internal.bento import bento
@step(on_failure=alert_slack, experiment_tracker="mlflow")
def train_and_deploy(training_df: pd.DataFrame) -> bento.Bento:
mlflow.autolog()
...
return bento
🎓 学习资源
ZenML提供了丰富的学习资源,帮助用户快速上手:
此外,ZenML还提供了多个实际案例供学习参考,涵盖了从基础的批量推理到复杂的NLP和LLM应用:
🚀 部署ZenML
为了充分发挥ZenML的协作功能,建议将其部署在云端。目前有两种主要的部署方式:
-
ZenML Pro: 这是一个SaaS版本,提供了一个控制平面来创建和管理多个ZenML服务器。这些服务器由ZenML的专门团队管理和维护,减轻了用户的服务器管理负担。它还提供了额外的功能,如RBAC、模型控制平面等。
-
自托管部署: 用户也可以选择在自己的环境中部署ZenML。这可以通过CLI、Docker、Helm或HuggingFace Spaces等多种方式实现。
🖥️ VS Code扩展
ZenML还提供了一个VS Code扩展,让用户可以直接在编辑器中检查堆栈和管道运行情况,无需使用命令行即可切换堆栈。
🗺 路线图与社区
ZenML是一个开放的项目,其路线图定期更新,让社区了解产品的短期、中期和长期发展方向。用户可以通过多种方式影响路线图:
🤝 贡献与社区
ZenML欢迎社区贡献。新手可以从标记为"good first issue"的问题开始。详细的贡献指南可以在CONTRIBUTING.md中找到。
如果你在使用过程中遇到问题,可以在Slack群组中寻求帮助,或者在GitHub仓库中提出issue。
📜 许可证
ZenML采用Apache License Version 2.0许可证分发。完整的许可证文本可以在仓库的LICENSE文件中找到。对该项目的任何贡献都将受Apache License Version 2.0的约束。
总的来说,ZenML作为一个开源的MLOps框架,正在努力简化机器学习项目从实验到生产的过程。通过提供简单的API、跨平台兼容性、强大的追踪功能以及丰富的集成生态系统,ZenML正在成为连接数据科学团队和云基础设施的重要桥梁。无论你是刚开始探索MLOps,还是寻求优化现有ML工作流程,ZenML都值得一试。













