
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文分离你描述的任何声音



本仓库包含"分离你描述的任何声音"的官方实现。
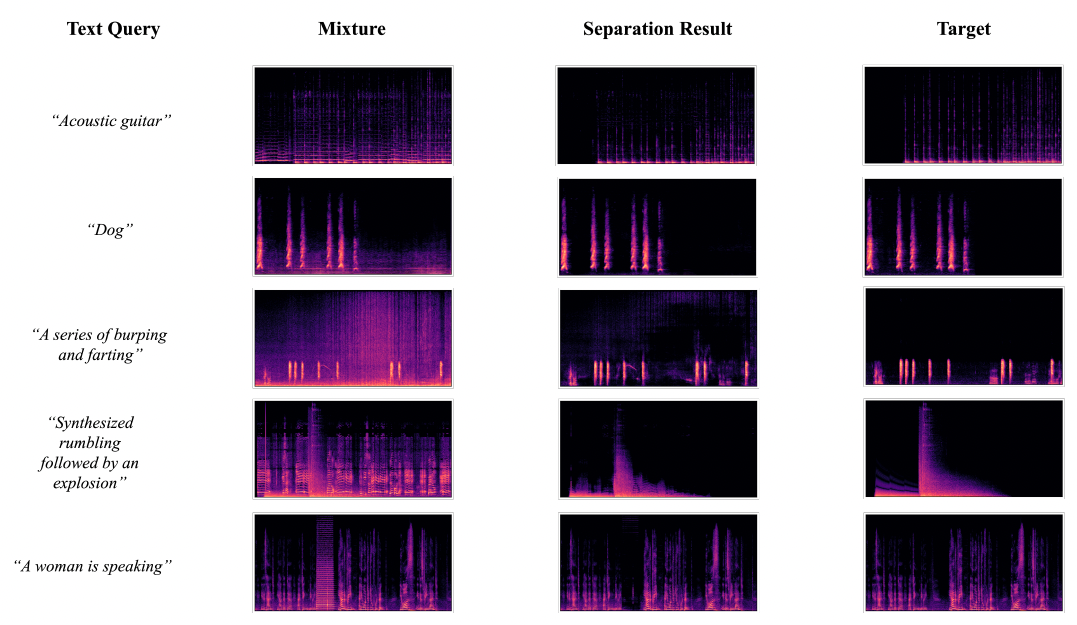
我们推出了AudioSep,一个用于开放域声音分离的基础模型,可通过自然语言查询进行操作。AudioSep在众多任务上展现出强大的分离性能和令人印象深刻的零样本泛化能力,例如音频事件分离、乐器分离和语音增强。请查看演示页面上的分离音频示例!
设置
克隆仓库并设置conda环境:
git clone https://github.com/Audio-AGI/AudioSep.git && \
cd AudioSep && \
conda env create -f environment.yml && \
conda activate AudioSep
在checkpoint/下载模型权重。
如果您将此检查点用于DCASE 2024 Task 9挑战赛参与,请注意此检查点是使用32kHz采样率的音频进行训练的,STFT操作中窗口大小为2048点,跳跃大小为320点,这与提供的挑战基线系统不同(16kHz,窗口大小1024,跳跃大小160)。
推理
from pipeline import build_audiosep, inference
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = build_audiosep(
config_yaml='config/audiosep_base.yaml',
checkpoint_path='checkpoint/audiosep_base_4M_steps.ckpt',
device=device)
audio_file = '音频文件路径'
text = '文本描述'
output_file='分离后的音频.wav'
# AudioSep以32 kHz采样率处理音频
inference(model, audio_file, text, output_file, device)
要直接从Hugging Face加载,您可以执行以下操作:
from models.audiosep import AudioSep
from utils import get_ss_model
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
ss_model = get_ss_model('config/audiosep_base.yaml')
model = AudioSep.from_pretrained("nielsr/audiosep-demo", ss_model=ss_model)
audio_file = '音频文件路径'
text = '文本描述'
output_file='分离后的音频.wav'
# AudioSep以32 kHz采样率处理音频
inference(model, audio_file, text, output_file, device)
使用基于块的推理来节省内存:
inference(model, audio_file, text, output_file, device, use_chunk=True)
训练
要使用您的音频-文本配对数据集:
-
将您的数据集格式化以匹配我们的JSON结构。请参考
datafiles/template.json中提供的模板。 -
更新
config/audiosep_base.yaml文件,在datafiles下列出您格式化的JSON数据文件。例如:
data:
datafiles:
- 'datafiles/your_datafile_1.json'
- 'datafiles/your_datafile_2.json'
...
从头开始训练AudioSep:
python train.py --workspace workspace/AudioSep --config_yaml config/audiosep_base.yaml --resume_checkpoint_path checkpoint/ ''
从预训练检查点微调AudioSep:
python train.py --workspace workspace/AudioSep --config_yaml config/audiosep_base.yaml --resume_checkpoint_path 检查点路径
基准评估
在evaluation/data文件夹下下载评估数据。数据应组织如下:
evaluation:
data:
- audioset/
- audiocaps/
- vggsound/
- music/
- clotho/
- esc50/
运行基准推理脚本,结果将保存在eval_logs/
python benchmark.py --checkpoint_path audiosep_base_4M_steps.ckpt
"""
评估结果:
VGGSound 平均SDRi: 9.144, SISDR: 9.043
MUSIC 平均SDRi: 10.508, SISDR: 9.425
ESC-50 平均SDRi: 10.040, SISDR: 8.810
AudioSet 平均SDRi: 7.739, SISDR: 6.903
AudioCaps 平均SDRi: 8.220, SISDR: 7.189
Clotho 平均SDRi: 6.850, SISDR: 5.242
"""
引用本工作
如果您觉得这个工具有用,请考虑引用
@article{liu2023separate,
title={Separate Anything You Describe},
author={Liu, Xubo and Kong, Qiuqiang and Zhao, Yan and Liu, Haohe and Yuan, Yi, and Liu, Yuzhuo, and Xia, Rui and Wang, Yuxuan, and Plumbley, Mark D and Wang, Wenwu},
journal={arXiv preprint arXiv:2308.05037},
year={2023}
}
@inproceedings{liu22w_interspeech,
title={Separate What You Describe: Language-Queried Audio Source Separation},
author={Liu, Xubo and Liu, Haohe and Kong, Qiuqiang and Mei, Xinhao and Zhao, Jinzheng and Huang, Qiushi, and Plumbley, Mark D and Wang, Wenwu},
year=2022,
booktitle={Proc. Interspeech},
pages={1801--1805},
}











