
 Github
Github 文档
文档Auto_TS:自动时间序列
使用单行代码自动构建多个时间序列模型。现已更新支持Dask。

auto_timeseries是一个复杂的时间序列数据模型构建工具。由于它自动化了许多复杂任务,因此它假设了许多智能默认值。但你可以更改它们。
Auto_Timeseries将快速构建基于Statsmodels ARIMA、季节性ARIMA、Prophet和Scikit-Learn机器学习的预测模型。它将自动选择给出最佳指定分数的最佳模型。
目录
最新
如果你正在寻找我们库的最新和最重要的更新,请查看我们的更新页面。
引用
如果你在研究项目或论文中使用Auto_TS,请使用以下格式进行引用:
"Seshadri, Ram (2020). GitHub - AutoViML/Auto_TS: 使用机器学习和统计技术通过单行代码构建和部署多个时间序列模型。源代码:https://github.com/AutoViML/Auto_TS"
简介
Auto_TS(Auto_TimeSeries)使你能够使用ARIMA、SARIMAX、VAR、可分解(趋势+季节性+节假日)模型和集成机器学习模型等技术构建和选择多个时间序列模型。
Auto_TimeSeries是一个用于时间序列数据的自动化机器学习库。Auto_TimeSeries最初由Ram Seshadri构思和开发,后来由Nikhil Gupta在功能和范围上进行了大幅扩展和升级,达到了现在的状态。
auto-ts.Auto_TimeSeries是你将使用训练数据调用的主要函数。你可以选择想要的模型类型:统计、机器学习或基于Prophet的模型。你还可以告诉它根据你想要的评分参数自动选择最佳模型。它将返回最佳模型和包含你指定的预测期数(默认为2)的预测字典。
安装
pip install auto-ts
如果上面的方法不起作用,请使用pip3 install auto-ts
pip install git+https://github.com/AutoViML/Auto_TS.git
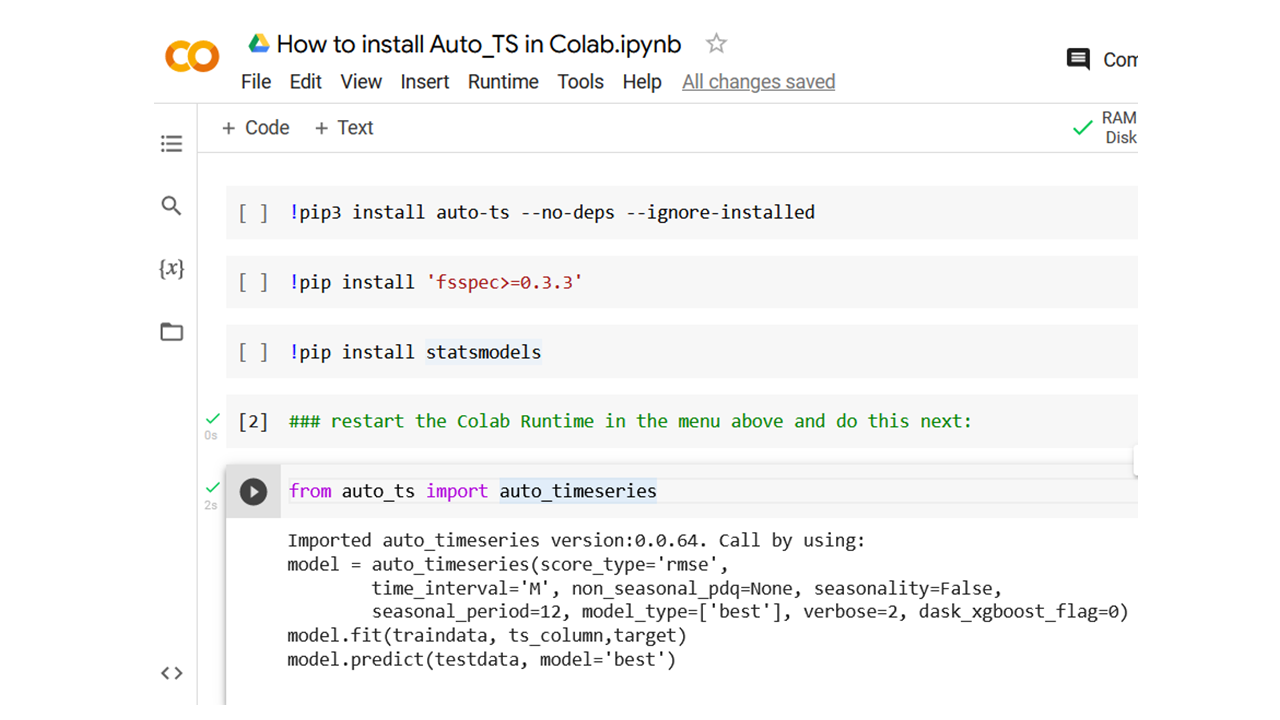
在Colab上安装
如果你正在使用Colab或Kaggle内核并想安装auto_ts,请使用以下步骤(否则你会收到错误!):
!pip install auto-ts --no-deps --ignore-installed
!pip install 'fsspec>=0.3.3'
!pip install statsmodels --upgrade
!pip install pmdarima
在Windows上安装
Windows用户在安装Prophet和pystan依赖项时可能会遇到困难。因此,我们建议在安装auto-ts之前按照Prophet文档页面的说明安装Prophet。对于Anaconda用户,可以通过以下方式完成:
conda install -c conda-forge prophet
pip install auto-ts
使用方法
首先,你需要从auto_ts库中导入auto_timeseries:
from auto_ts import auto_timeseries
其次,初始化一个auto_timeseries模型对象,该对象将包含所有参数:
model = auto_timeseries(
score_type='rmse',
time_interval='Month',
non_seasonal_pdq=None, seasonality=False,
seasonal_period=12,
model_type=['Prophet'],
verbose=2,
)
以下是输入参数的定义:
- score_type (默认为'rmse'): 用于对模型进行评分的指标。类型为字符串。
目前仅支持以下两种类型:
- "rmse": 均方根误差(RMSE)
- "normalized_rmse": RMSE与实际值标准差的比率
- time_interval (默认为None): 用于指示数据收集的频率。
它有两个用途:(1)构建Prophet模型,(2)在用户未提供(None)的情况下用于推断SARIMAX的季节性周期。类型为字符串。我们使用以下pandas日期范围频率别名,这些别名被Prophet用于创建预测数据框。
因此,请注意以下是允许使用的频率别名列表:
['B','C','D','W','M','SM','BM','CBM', 'MS','SMS','BMS','CBMS','Q','BQ','QS','BQS', 'A,Y','BA,BY','AS,YS','BAS,BYS','BH', 'H','T,min','S','L,ms','U,us','N']首先,您可以为您的数据测试以下代码并查看结果(或者您可以将其保留为None,auto_timeseries将尝试为您推断):'MS', 'M', 'SM', 'BM', 'CBM', 'SMS', 'BMS'用于月度频率数据'D', 'B', 'C'用于日频率数据'W'用于周频率数据'Q', 'BQ', 'QS', 'BQS'用于季度频率数据'A,Y', 'BA,BY', 'AS,YS', 'BAS,YAS'用于年度频率数据'BH', 'H', 'h'用于小时频率数据'T,min'用于分钟频率数据'S', 'L,milliseconds', 'U,microseconds', 'N,nanoseconds'用于秒频率数据
- non_seasonal_pdq (默认为(3,1,3)): 指示在搜索统计ARIMA模型时要使用的(p, d, q)的最大值。
如果为None,则假定以下值:
max_p = 3, max_d = 1, max_q = 3。类型为元组。 - seasonality (默认为False): 目前仅用于构建SARIMAX模型。True或False。类型为布尔值。
- seasonal_period (默认为None): 指示数据中的季节性周期。这取决于数据中定期出现的峰值(或谷值)周期。
目前仅用于构建SARIMAX模型。
如果seasonality设置为False,则此参数无影响。
如果为None,程序将尝试从数据的time_interval(频率)推断此值。
我们假设以下默认值,但您可以随意更改:
- 如果频率为月度,则seasonal_period假定为12
- 如果频率为日度,则seasonal_period假定为30(但也可能是7)
- 如果频率为周度,则seasonal_period假定为52
- 如果频率为季度,则seasonal_period假定为4
- 如果频率为年度,则seasonal_period假定为1
- 如果频率为小时,则seasonal_period假定为24
- 如果频率为分钟,则seasonal_period假定为60
- 如果频率为秒,则seasonal_period假定为60 类型为整数
- conf_int (默认为0.95): 用于构建Prophet模型的置信区间。默认:0.95。类型为浮点数。
- model_type (默认:'stats'): 要构建的模型类型。默认仅构建统计模型。如果提供列表,则仅构建这些模型。可以是字符串或模型列表。允许的值为:
'best', 'prophet', 'stats', 'ARIMA', 'SARIMAX', 'VAR', 'ML'。 "prophet"将使用 Prophet 构建模型 -> 这意味着你必须安装 Prophet"stats"将构建基于 statsmodels 的 ARIMA、SARIMAX 和 VAR 模型"ML"将使用随机森林构建机器学习模型,前提是提供了解释变量"best"将尝试构建所有模型并选择最佳模型- verbose (默认值=0): 表示打印的详细程度。类型为整数。
警告:"best" 对于大型数据集可能需要一些时间。我们建议在尝试运行整个数据之前,先从数据集中选择一个小样本。
定义模型对象后的下一步是用一些真实数据来拟合它:
model.fit(
traindata=train_data,
ts_column=ts_column,
target=target,
cv=5,
sep=","
)
以下是参数的定义方式:
- traindata (必需): 可以是数据框或文件。如果是文件,必须给出文件名及其数据路径。如果你的笔记本中已经加载了数据框,它也接受 pandas 数据框。
- ts_column (必需): 数据集中日期时间列的名称(可以是列名或列索引中的索引号)。
- target (必需): 你试图预测的列名。目标也可以是数据集中唯一的列。
- cv (默认值=5): 你可以输入任何整数作为交叉验证数据集中想要的折数。
- sep (默认值=","): Sep 是训练数据文件中的分隔符。如果你的分隔符是 ","、"\t"、";",请确保在这里输入。如果不是,则忽略。
训练模型对象后的下一步是用测试数据进行一些预测:
predictions = model.predict(
testdata = ..., # 可以是数据框或代表预测期的整数
model = 'best' # 或任何其他代表已训练模型的字符串
)
以下是参数的定义方式。你可以选择以数据框的形式发送测试数据,或发送一个整数来决定你想预测多少期。你只需要
- testdata (必需): 可以是包含测试数据的数据框,或者你可以使用代表预测期(你想要的)的整数。
- model (可选,默认值 = 'best'): 你想在多个已训练模型中使用的模型名称。记住默认是最佳模型。但你可以选择任何你想用来预测的模型。类型是字符串。
要求
dask, scikit-learn, prophet, statsmodels, pmdarima, XGBoost许可证:
Apache License 2.0提示
- 我们建议在尝试运行整个数据之前,先从数据集中选择一个小样本。以及评估指标,以便选择最佳模型。目前,"stats" 内的模型使用 AIC 和 BIC 进行比较。然而,不同类型的模型之间使用 RMSE 进行比较。模型的结果使用 RMSE 和标准化 RMSE(RMSE 与实际值标准差的比率)显示。
- 你必须清理数据,不能有任何缺失值。确保目标变量是数值型,否则无法运行。如果你的数据集中有多个目标变量,现在只需指定一个,如果你知道数据中的时间间隔,可以指定它。否则,auto-ts 将尝试自行推断时间间隔。
- 如果你给 Auto_Timeseries 一个与数据不同的时间间隔,它会自动将数据重新采样到给定的时间间隔,并使用重新采样期间的目标均值。
- 注意,除了必需的 filename 和 ts_column 输入参数外,所有其他参数都是可选的。
- 注意,你可以选择为文件中的数据指定分隔符。默认为逗号(",")。
- "time_interval" 选项是你可以在下面这个页面找到的任何代码。 Pandas 日期范围频率别名
- 可选地,你可以给出 seasonal_period 作为衡量数据中季节性的任何整数。如果未给出,seasonal_period 自动假定如下:
- 月 = 12,
- 日 = 30,
- 周 = 52,
- 季度 = 4,
- 年 = 1,
- 小时 = 24,
- 分钟 = 60 和
- 秒数 = 60。
- 如果你想给出自己的非季节性阶数,请以non_seasonal_pdq的形式输入,对于季节性阶数,则使用seasonal_PDQ作为输入。使用元组格式。例如,
seasonal_PDQ = (2,1,2)和non_seasonal_pdq = (0,0,3)。它只接受元组格式。默认值为None,Auto_Timeseries将自动搜索最佳的p,d,q(非季节性)和P,D,Q(季节性)阶数,方法是对每个p,d,q值搜索0到12的所有参数,对每个P,Q搜索0到3,对D搜索0到1。
免责声明:
这不是Google官方支持的项目。











