
0️⃣1️⃣🤗 BitNet-Transformers: Huggingface Transformers在pytorch中实现“BitNet: Scaling 1-bit Transformers for Large Language Models”,并采用Llama(2)架构
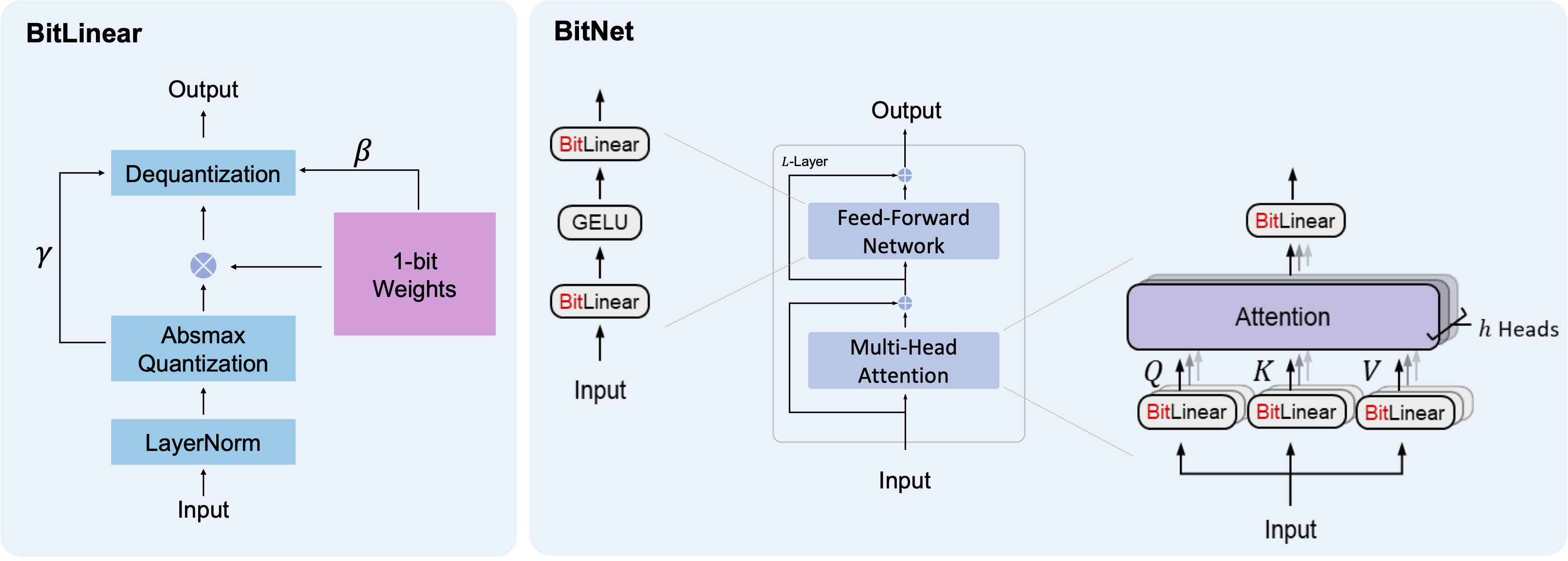
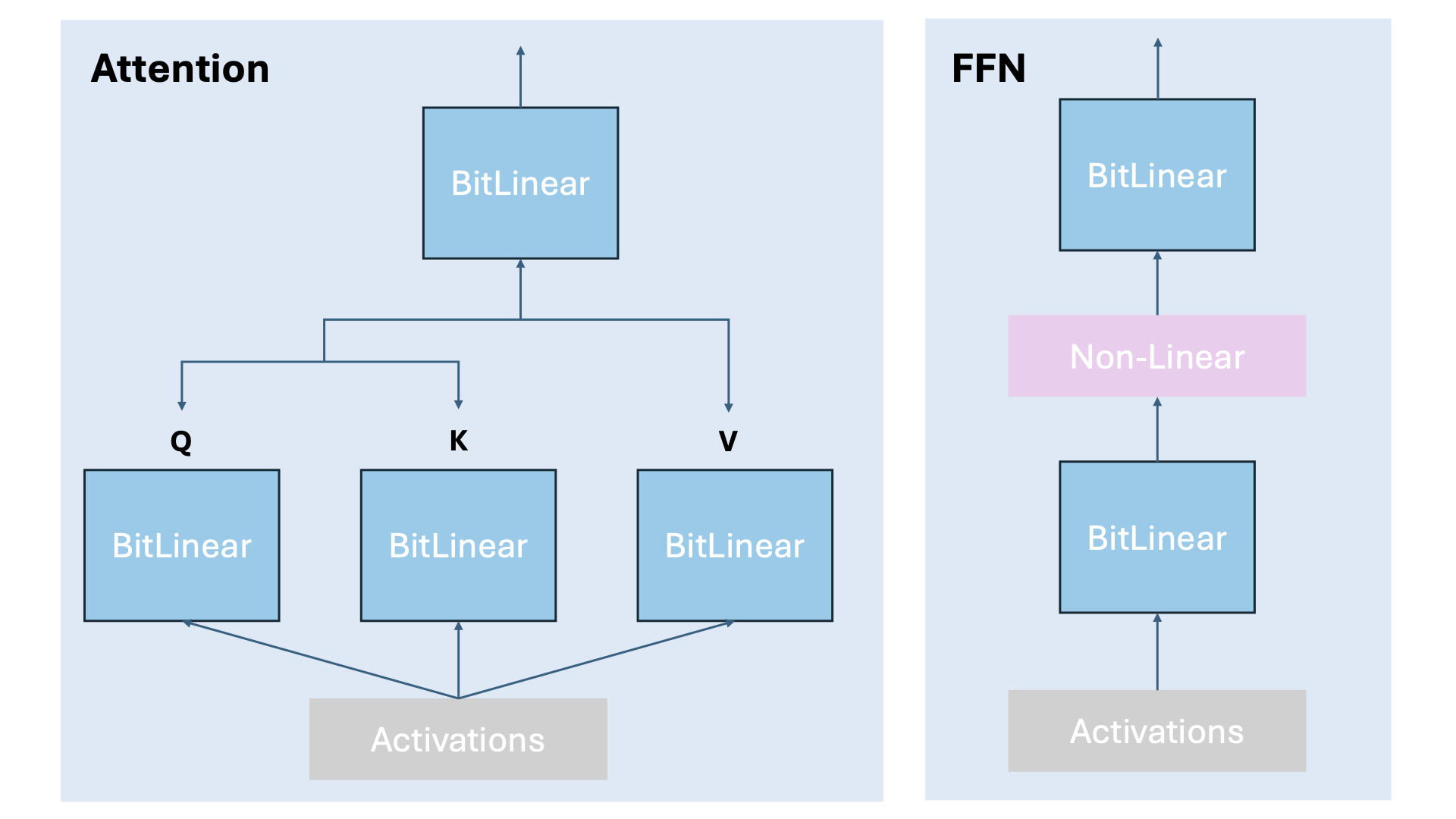
准备开发环境
# 克隆此仓库
git clone https://github.com/beomi/bitnet-transformers
cd bitnet-transformers
# 安装依赖
pip install -r clm_requirements.txt
# 克隆transformers仓库
git clone https://github.com/huggingface/transformers
pip install -e transformers
# 更新Llama(2)模型
rm ./transformers/src/transformers/models/llama/modeling_llama.py
ln -s $(pwd)/bitnet_llama/modeling_llama.py ./transformers/src/transformers/models/llama/modeling_llama.py
我们将把bitnet_llama/modeling_llama.py覆盖到transformers中。由于文件是链接的,对文件所做的任何更改都会反映在transformers仓库中。
训练Wikitext-103
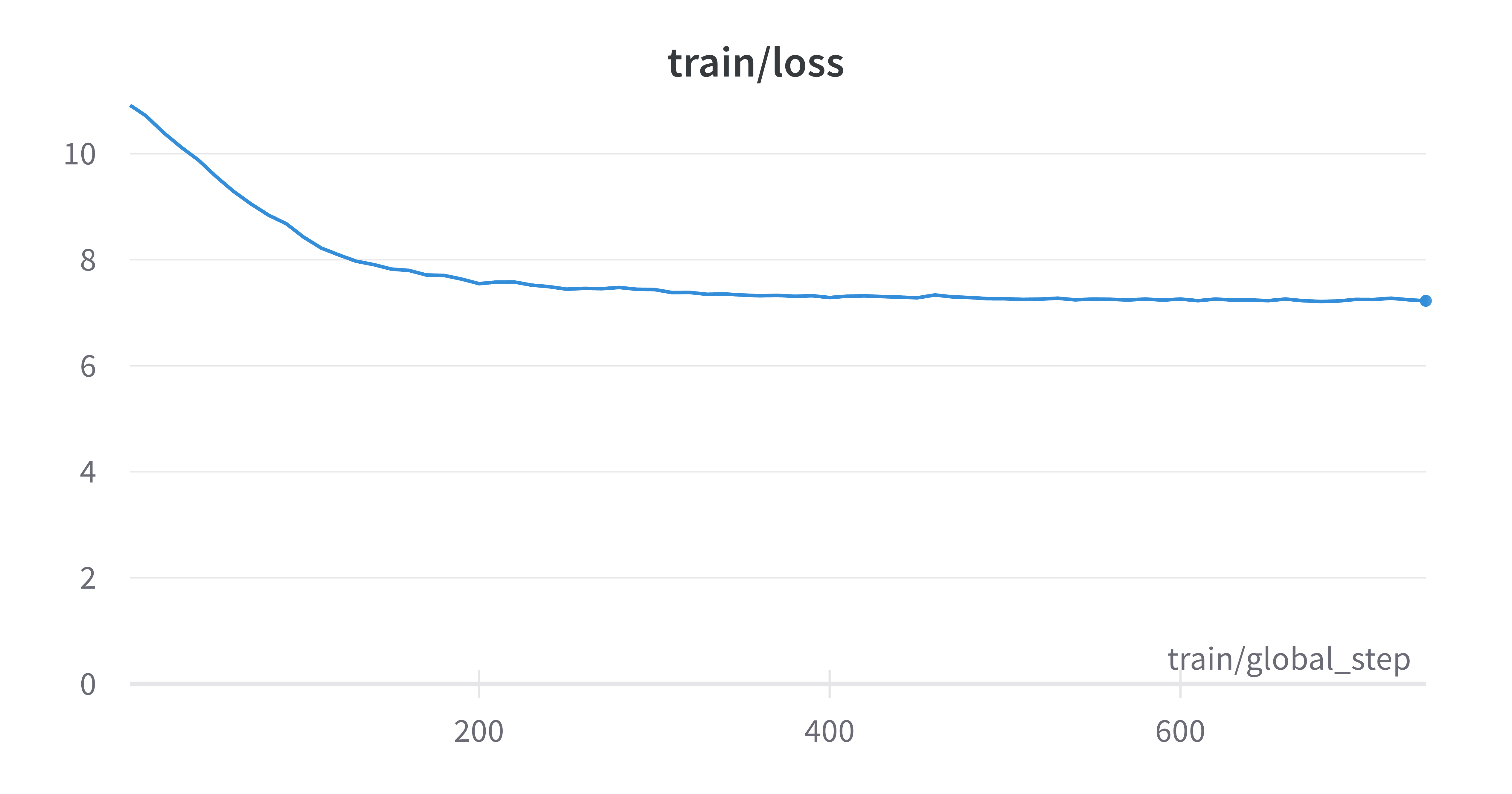
你可以通过wandb追踪指标
./train_wikitext.sh
GPU内存使用比较
训练配置
- 批次大小: 1
- 梯度累积: 1
- 序列长度: 2048
- 模型:
LLamaForCausalLM,带BitLinear层 - 模型大小: 47,452,672 (47.5M)
原始LLAMA - 16bit
- 使用250MB GPU内存存储模型权重
BitLLAMA - 混合16bit
- 使用200MB GPU内存存储模型权重
- 使用bf16或fp16存储模型权重
- 使用int8存储
-1/1的1-bit权重 - 训练时比原始LLAMA使用更多内存: 它同时保存1-bit权重和16bit权重
BitLLAMA - 8bit
- 使用100MB GPU内存存储模型权重
- 需要时即时使用bf16或fp16
- 使用8bit来保存1-bit BitLinear权重和其他权重
BitLLAMA - 1bit
- 需要时即时使用bf16或fp16
- 使用1bit来保存1-bit权重
TBD
待办事项
- 添加
BitLinear层 - 添加带有
BitLinear层的LLamaForCausalLM模型- 更新
.save_pretrained方法(用于1-bit权重保存)
- 更新
- 添加LM训练示例代码
- 更新
BitLinear层以使用1-bit权重- 使用uint8代替bfloat16
- 使用自定义CUDA内核保存1-bit权重











