
 访问官网
访问官网 Github
Github Huggingface
Huggingface
「遇见李白」 meet-libai
meet-libai







:vertical_traffic_light: 哔哩哔哩详细视频介绍和引导
1. 项目背景
李白 :bust_in_silhouette: 作为唐代杰出诗人,其诗歌作品在中国文学史上具有重要地位。近年来,随着数字技术和人工智能的快速发展,传统文化普及推广的形式也面临着创新与变革。国内外对于李白诗歌的研究虽已相当深入,但在数字化、智能化普及方面仍存在不足。因此,本项目旨在通过构建李白知识图谱,结合大模型训练出专业的AI智能体,以生成式对话应用的形式,推动李白文化的普及与推广。
随着人工智能技术的发展,知识图谱技术也得到了广泛的应用。知识图谱是一种基于语言知识库的语义表示模型,它能够将结构化的知识表示为图的形式,从而使得机器能够更好地理解和处理自然语言。 在知识图谱技术的基础上,开发一个问答系统可以利用知识图谱中的知识来回答用户的问题。该系统可以利用知识图谱来构建以诗人李白为核心的古诗词文化知识图谱 :globe_with_meridians: ,并实现基于该知识图谱的问答功能。另外,对图谱进行可视化探索,以更好地理解知识图谱的结构和内容。同时提供,大模型以及rag检索增强的代码实现。
2. 项目目标
2.1 :1st_place_medal: 收集整理李白诗歌及其相关文化资料:通过文献调研、数据挖掘等方法,全面收集李白的诗歌作品、生平事迹、历史背景等相关资料,为构建李白知识图谱提供基础数据。
2.2 :2nd_place_medal: 构建李白知识图谱:利用自然语言处理、信息抽取等技术,对收集到的资料进行整理和分析,构建出一个完整的李白知识图谱。该图谱将涵盖李白的生平、诗歌风格、艺术成就等多个方面,为后续的AI智能体训练提供丰富的知识库。
2.3 :3rd_place_medal: 训练专业的AI智能体:基于构建好的李白知识图谱,利用大模型技术训练出具有专业水平的AI智能体。该智能体将具备对李白诗歌的深入理解和鉴赏能力,能够与用户进行高质量的互动。
2.4 :four:开发生成式对话应用:在训练好的AI智能体基础上,开发一款生成式对话应用。该应用将能够实现与用户的实时互动,为用户提供个性化的李白诗歌鉴赏体验。
3. 项目技术栈
- Python
- PyTorch
- Transformers
- fastAPI
- DGL
- DGL-KE
- Neo4j
- AC自动机
- RAG
- langchain
- edge-tts
- modelscope
- gradio
- zhipuai
4. 项目功能
-
Data preprocessing: Clean, tokenize, and construct knowledge graph for ancient poetry data
-
Knowledge graph construction: Utilize knowledge graph technology to build a cultural knowledge graph centered on Li Bai for ancient poetry
- Question answering system construction: Utilize knowledge from the graph to answer user questions
- Graph visualization: Visualize the knowledge graph to better understand its structure and content
- Question answering system construction: Utilize knowledge from the graph to answer user questions
-
:hotsprings:Graph Q&A approach:
-
:smile_cat:General streaming Q&A
-
:recycle: Relational Q&A:
- What is the relationship between Li Bai and Du Fu
-
:package:Attribute Q&A:
- In which year was Li Bai born
-
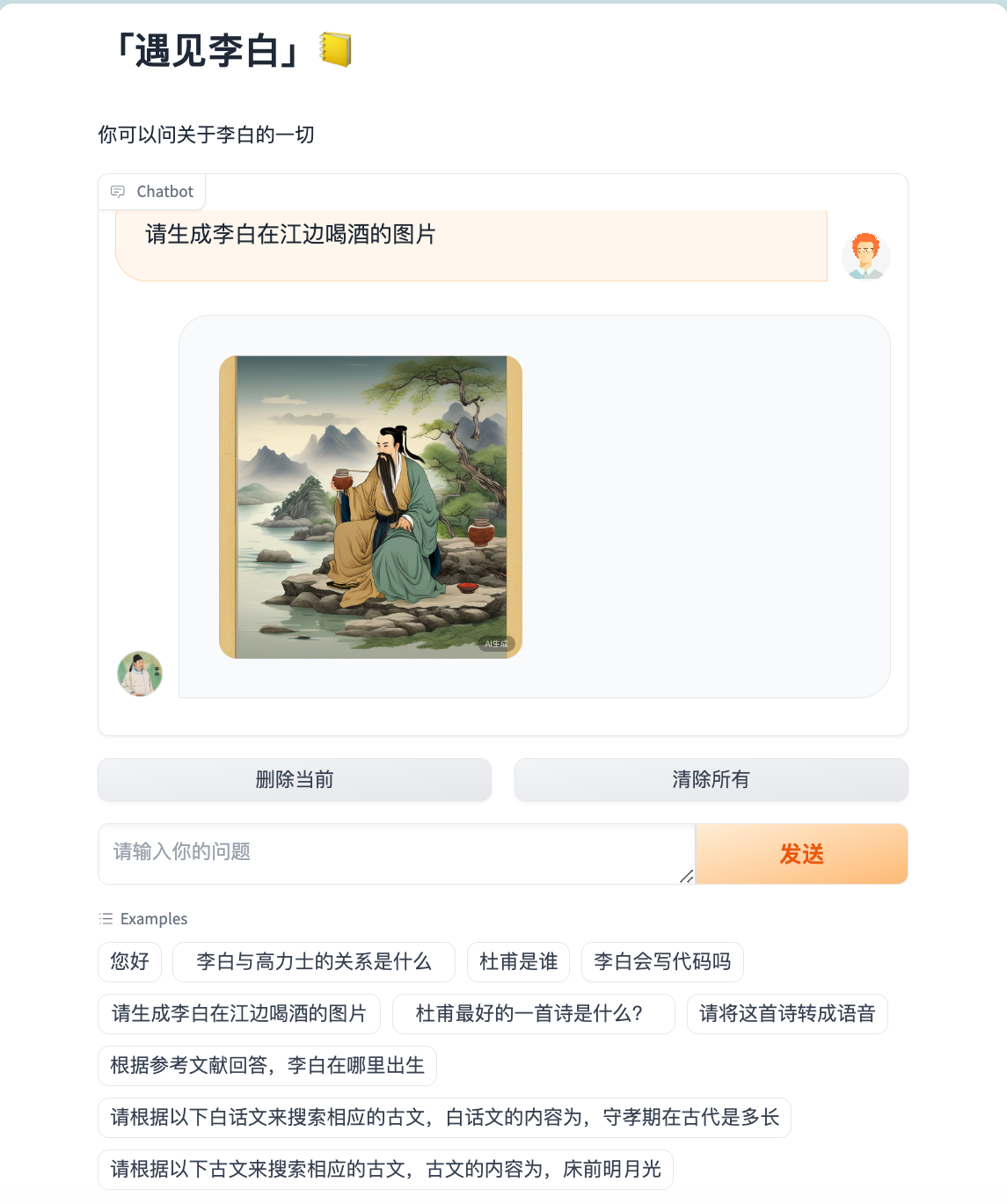
:gift: Generate audio and images:
-
Please generate an image of Li Bai drinking by the river
-
Please generate audio for the poem "Spring View"
-
-
5. Current Project Status
- Built a knowledge graph-based Q&A system that can use knowledge from the graph to answer user questions.
- Visualized the graph for better understanding of its structure and content.
- Provided code implementation for large models and RAG retrieval augmentation.
6. Project Challenges
- Construction and maintenance of the knowledge graph
- Implementation and optimization of the Q&A system
- Visualization exploration of the graph
- Code implementation for large models and RAG retrieval augmentation
7. Project Outlook
- Further optimize the answer quality and efficiency of the Q&A system
- Explore other types of Q&A tasks, such as common sense questions, knowledge reasoning, etc.
- Continuously update and maintain the knowledge graph to ensure its accuracy, completeness and effectiveness
8. Project Technical Architecture
Through the implementation of this project, we have not only realized a knowledge graph-based Q&A system, but also accumulated rich practical experience and knowledge graph technology application experience. In future work, we will continuously optimize the answer quality and efficiency of the Q&A system, and explore other types of Q&A tasks to meet the needs of more users. Meanwhile, we will continue to update and maintain the knowledge graph to ensure its accuracy, completeness and effectiveness, contributing to the development and application of knowledge graph technology. The following is the project technical architecture diagram:
9. Project Code Structure
Please click here to jump to Code Structure:cityscape:
10. Core Functions
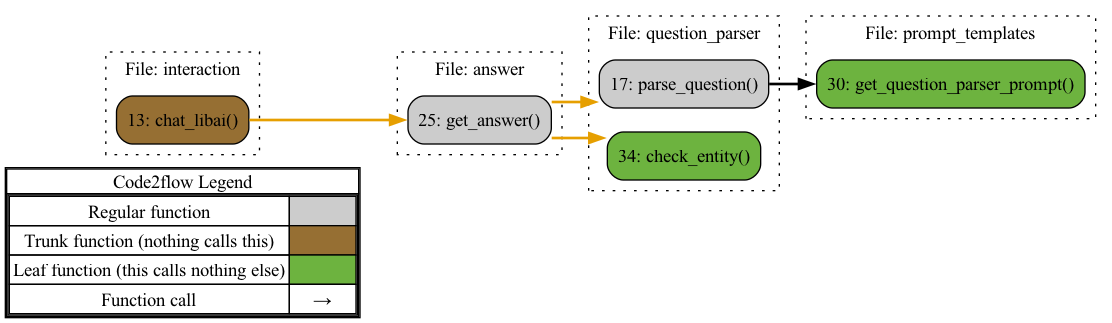
Main Underlying Dependencies
How to Start the Project
1. Configure third-party large model API key
:key:Use the Zhipu AI open platform, please jump to that platform to apply for an API key. Then, fill in the API key in the .env file.
2. Create Python environment (>=python3.10)
-
Use conda to manage Python environments, so please install conda first (Install Conda):smile_cat:
-
Use conda command to create Python environment
#Create a new environment: Use the following command to create a new Python environment with a specific version. (Of course, in China you may need to configure conda and pip mirrors) conda create --name myenv python=3.10 #This will create a new environment named myenv with the specified Python version. #Activate the environment: Once the environment is created, you need to activate it. conda activate myenv -
Install dependencies
pip install -r requirements.txt
3. Set up graph database
-
Please follow the instructions below to install neo4j

You can start a Neo4j container like this:
docker run \ --publish=7474:7474 --publish=7687:7687 \ --volume=$HOME/neo4j/data:/data \ neo4j:5.12.0which allows you to access neo4j through your browser at http://localhost:7474.
This binds two ports (
7474and7687) for HTTP and Bolt access to the Neo4j API. A volume is bound to/datato allow the database to be persisted outside the container.By default, this requires you to login with
neo4j/neo4jand change the password. You can, for development purposes, disable authentication by passing--env=NEO4J_AUTH=noneto docker run.
-
Of course, you can also install neo4j directly on your operating system without using Docker and start the service.
-
After installation, import the data into neo4j :smiling_imp:
:warning:Note: As the establishment and organization of data involves third-party copyrights, this project does not provide complete Li Bai data, only sample data
Cypher query statement is as follows:
# 创建`李白`节点
CREATE (p:`人物`:`唐`{name: '李白', PersonId:32540})
# 创建'高力士'节点
CREATE (p:`人物`:`唐`{name: '高力士', PersonId:32541})
# 创建李白和高力士的关系
MATCH (a:`人物`:`唐` {PersonId: 32540}), (b:`人物`:`唐` {PersonId: 32541})
CREATE (a)-[r:`李白得罪高力士` {since: 2022, strength: 'strong', Notes: '《李太白全集》卷三五《李太白年譜》:天寶三載,甲申。(五月改"年"爲"載"。四十四歲)太白在翰林,代草王言。然性嗜酒,多沉飮,有時召令撰述,方在醉中,不可待,左右以水沃面,稍解,卽令秉筆,頃之而成。帝甚才之,數侍宴飮。因沉醉引足令高力士脫靴,力士恥之,因摘其詩句以激太眞妃。帝三欲官白,妃輒沮之。又爲張垍讒譖,公自知不爲親近所容,懇求還山,帝乃賜金放歸。又引《松窗錄》:會高力士終以脫靴爲深恥,異日,太眞妃重吟前詞,力士戲曰:"比以妃子怨李白深入骨髓,何反拳拳如是?"太眞妃驚曰:"何翰林學士能辱人如斯!"力士曰:"以飛燕指妃子,是賤之甚矣!"太眞妃深然之。上嘗三欲命李白官,卒爲宮中所捍而止。'}]->(b)
RETURN r
以上数据导入完毕之后,再导入元数据节点(该节点用于记录数据版本号的基本信息)
CREATE (meta_node:Meta{
id: 'meta-001',
title: 'libai-graph meta node',
text: 'store some meta info',
timestamp: datetime(),
version: 1,
status: 'active'
})
-
确认neo4j数据正常之后,配置config文件(以config-local.yaml为例) :pager: (连接数据库的url,用户名,密码)
neo4j:
url: bolt://localhost:7687
database: neo4j
username: neo4j
password: *****
# 注意: 以上参数,根据你的数据库实际连接为准
4. 配置文件
有3个配置文件(根据你的需求,决定使用哪个配置,如果没有对应的配置文件,可以拷贝./config/config-local.yaml作为副本,再修改):
部署环境配置./config/config-deploy.yaml
测试环境配置./config/config-dev.yaml
本地开发配置./config/config-local.yaml
在项目根目录下新建.env文件作为环境变量配置,并在文件中指定启用哪个环境配置,下面给出一个完整的.env内容
#PY_ENVIRONMENT=dev
PY_ENVIRONMENT=local # 启用本地开发环境
#PY_ENVIRONMENT=deploy
PY_DEBUG=true
# ---------注意-----------------------------------
# 如下模型中只能使用其中的某一个模型,不能同时配置多个模型
# 去对应的官网申请api-key,并替换YOUR API-KEY
# 也可以使用ollama本地运行的模型,api-key设置为ollama
# ⚠️文生图的模型暂时使用zhipuai,因此要配置zhipuai的api-key
# -----------------------------------------------
# 智普ai
LLM_BASE_URL=https://open.bigmodel.cn/api/paas/v4/
LLM_API_KEY=YOUR API-KEY
MODEL_NAME=glm-4
# kimi
#LLM_BASE_URL=https://api.moonshot.cn/v1
#LLM_API_KEY=YOUR API-KEY
#MODEL_NAME=moonshot-v1-8k
# 百川大模型
#LLM_BASE_URL=https://api.baichuan-ai.com/v1/
#LLM_API_KEY=YOUR API-KEY
#MODEL_NAME=Baichuan4
# 通义千问
#LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
#LLM_API_KEY=YOUR API-KEY
#MODEL_NAME=qwen-long
# 零一万物
#LLM_BASE_URL=https://api.lingyiwanwu.com/v1
#LLM_API_KEY=YOUR API-KEY
#MODEL_NAME=yi-large
# deepseek
# LLM_BASE_URL=https://api.deepseek.com
# LLM_API_KEY=ollama
# MODEL_NAME=deepseek-chat
# 豆包
#LLM_BASE_URL=https://ark.cn-beijing.volces.com/api/v3/
#LLM_API_KEY=YOUR API-KEY
# 注意:对于豆包api,model_name参数填入ENDPOINT_ID,具体申请操作在豆包api官网提供。
#MODEL_NAME=
# ollama
#LLM_BASE_URL=http://localhost:11434/v1/
#LLM_API_KEY=ollama
#MODEL_NAME=qwen2:0.5b
#文生图模型,暂时使用zhipuai
#OPENAI_API_KEY=YOUR API-KEY
ZHIPUAI_API_KEY=YOUR API-KEY
# 这里填入你的组织名
ORGANIZATION_NAME= xxx团队
5. 白话文搜古文、古文搜古文
:smiley:由于涉及到内存问题,这两个服务独立部署。目前暂不开源,感兴趣的读者,可以自己按照如下接口规则独立开发。如果没有这个服务接口,不影响程序运行。
古文搜古文,接口访问示例:
data = {
"text": '床前明月光', # 古诗
"conf_key": "chinese-classical", # 预留参数
"group": "default", # 预留参数
"size": 5, # 返回结果数量
"searcher": 3 # 预留参数
}
resp = requests.post("http://172.16.67.150:18880/api/search/nl", data=json.dumps(data))
接口返回数据示例:
{
"retCode": 0,
"errMsg": null,
"values": [
{
"value": "明##@##申佳允##@##天际秋云薄|床前明月光|无由一化羽|回立白苍苍##@##秋兴集古 其八##@##苍苍 天际 秋云 明月",
"score": 1.0000004768371582
},
{
"value": "唐##@##李白##@##床前明月光|疑是地上霜|举头望山月|低头思故乡##@##静夜思##@##山月 霜 明月 低头",
"score": 1.0000004768371582
},
{
"value": "唐##@##李白##@##床前明月光|疑是地上霜|举头望明月|低头思故乡##@##静夜思##@##霜 光 明月 低头",
"score": 1.0000004768371582
},
{
"value": "明##@##高启##@##堂上织流黄|堂前看月光|羞见天孙度|低头入洞房##@##子夜四时歌 其三##@##天孙 月光 洞房 低头",
"score": 0.7958479523658752
},
{
"value": "明##@##黄渊耀##@##凉风落柳梢|微云淡河面|怀中明月光|多赊不为贱##@##夜坐##@##凉风 柳梢 明月 微云",
"score": 0.7571470737457275
}
]
}
score表示得分,value表示一条数据,value中的各个字段值用##@##隔开 ["朝代","作者", "完整诗篇", "篇名", "关键词"]
6. 程序启动(三种方式)
- 后台启动
启动shell脚本为restart.sh
> chmod +x ./restart.sh
> ./restart.sh
启动成功后可以访问
-
webui http://localhost:7860
-
python启动所有任务包括api和webui
python app.py
启动成功后可以访问
-
webui http://localhost:7860
-
python命令启动webui
python webui.py
启动成功后可以访问
- webui http://localhost:7860
7. 调用程序api构建图数据库的实体索引(在本地创建ac自动机),这一步成功后才可使用图数据
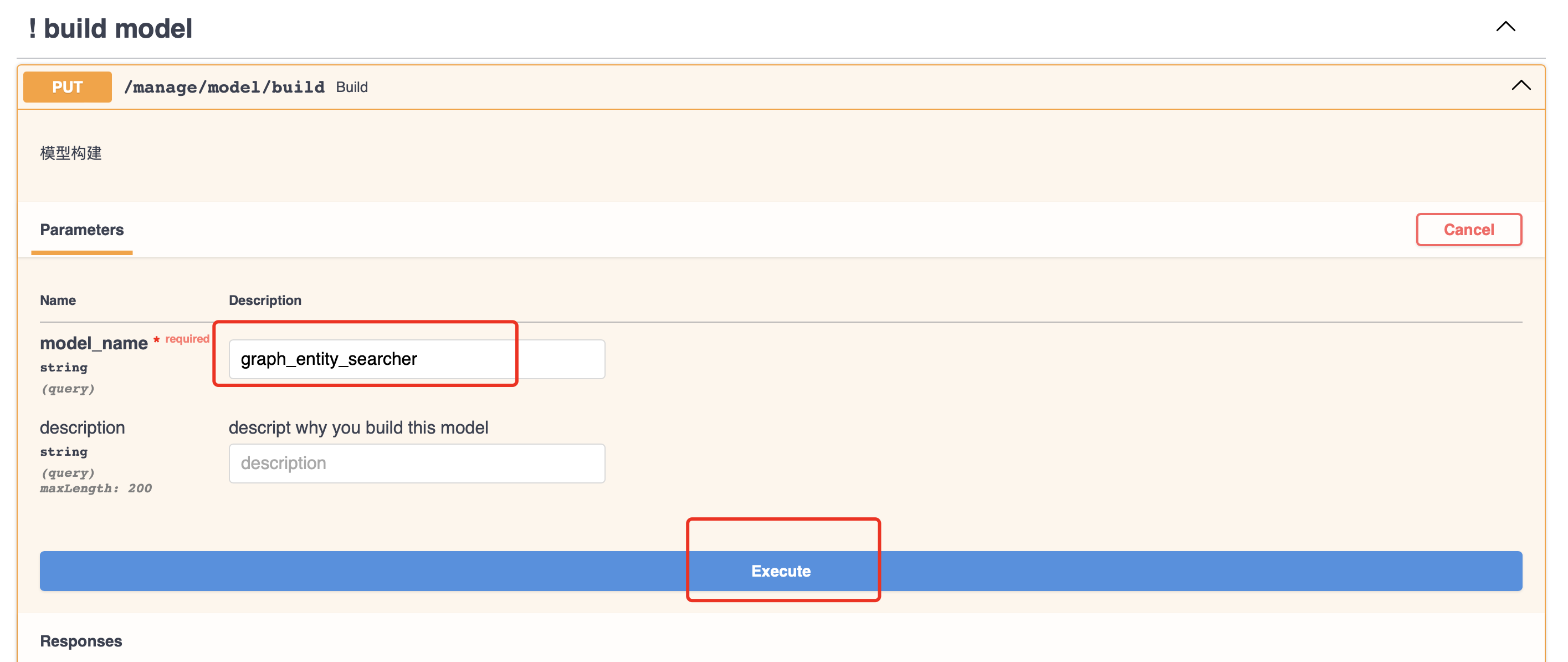
访问api: http://localhost:18881/docs 打开如下图所示, 然后点击构建模型:
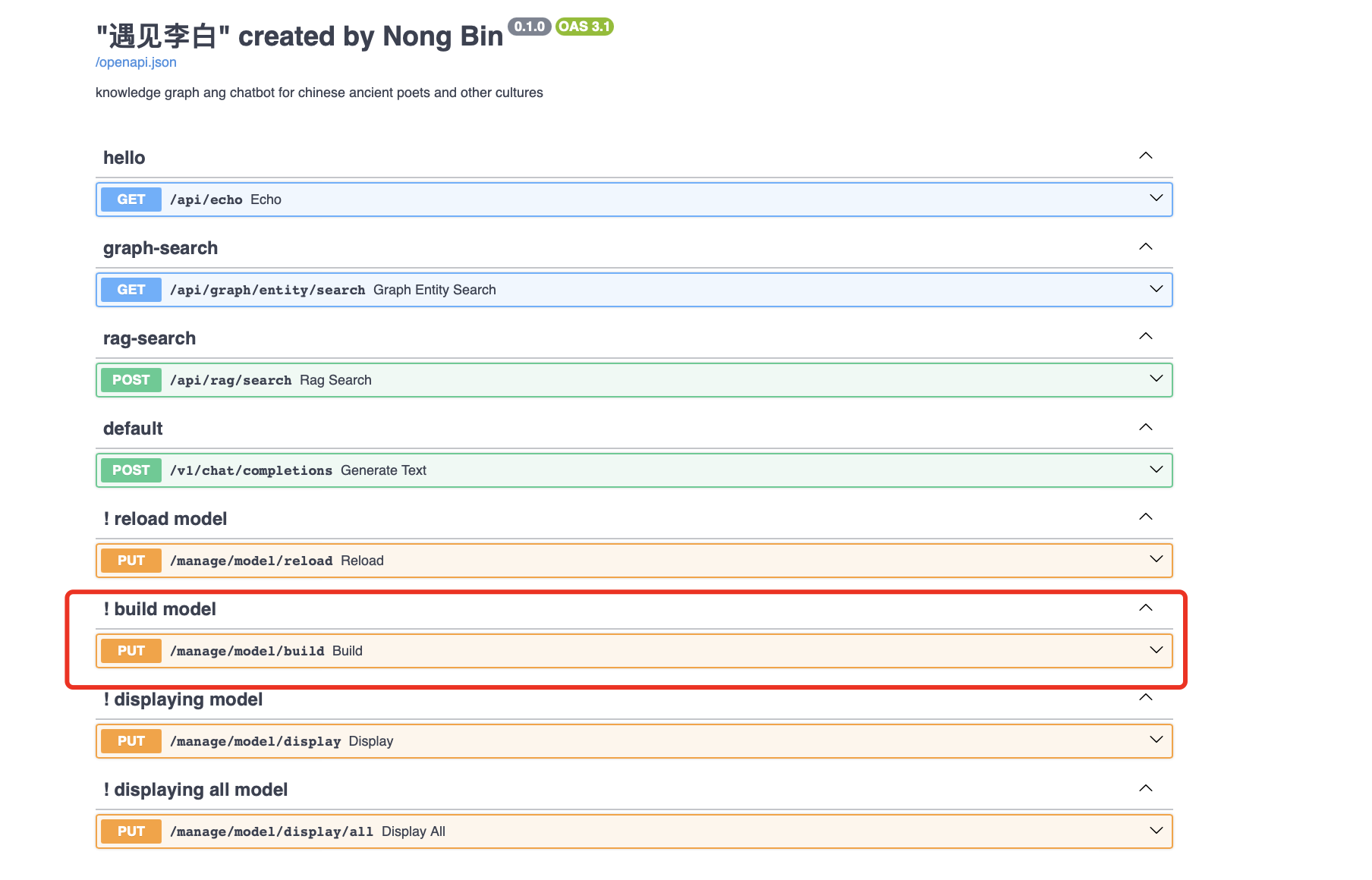
接着填写如下参数后,点击执行:
8.知识图谱构建演示demo
1.按照前面的步骤启动程序之后(程序保持运行),运行根目录下的graph_demo_ui.py:
python graph_demo_ui.py
-
访问地址:
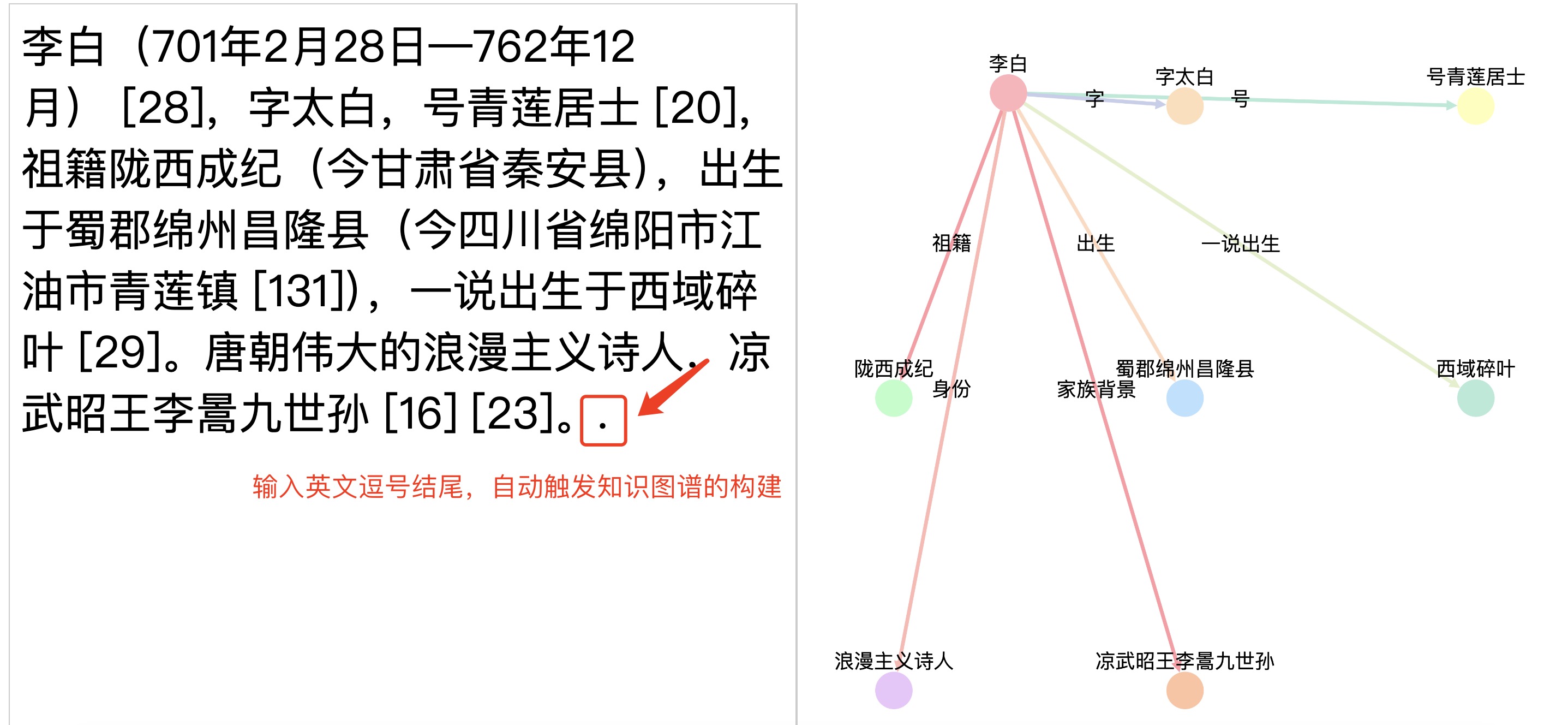
http://127.0.0.1:80如下图在左侧输入原始文本,以英文逗号结尾自动触发构建过程(需要一定的时间等待)!
赞赏
如果你愿意,你可以赞赏我,不在乎数量,你的一个不经意的举动是我前进的动力,业余时间搬砖实属不易。













