
 Github
Github Huggingface
Huggingface 论文
论文ChineseWebText:使用有效评估模型提取的大规模高质量中文网络文本
本目录包含ChineseWebText数据集,以及用于处理CommonCrawl数据以获取高质量中文数据的EvalWeb工具链。我们的ChineseWebText数据集可在huggingface上公开获取(点击这里)。
ChineseWebText
-
数据集概览
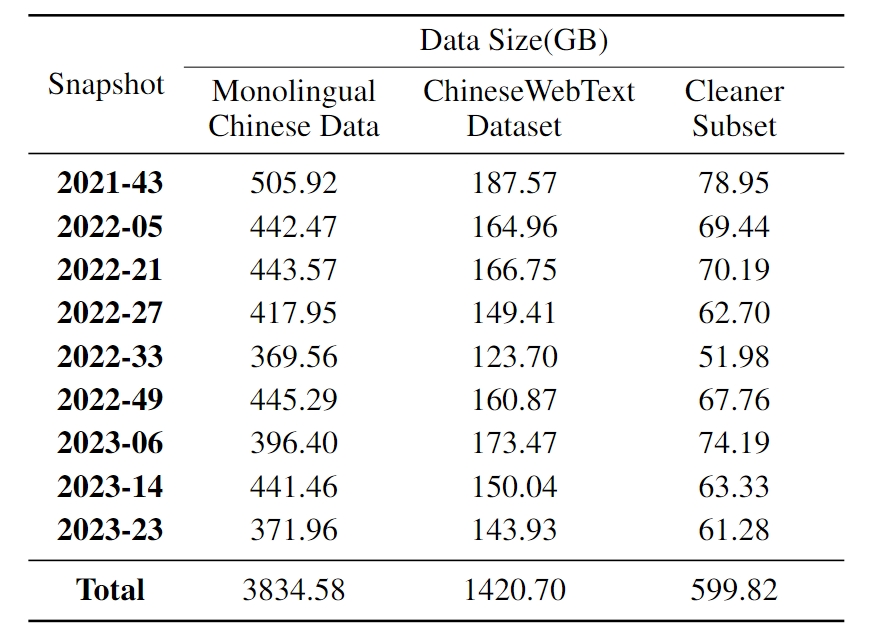
我们发布了最新且最大的中文数据集ChineseWebText,它包含1.42 TB的数据(见表1),每个文本都被分配了一个质量分数,便于大型语言模型研究人员根据新的质量阈值选择数据。我们还发布了一个更加干净的子集,包含600 GB质量超过**90%**的中文文本。
-
数据示例
{ "title": "潍坊银行2021年上半年净利润同比增长29.57% 不良率降至1.10%_财经_中国网", "score": 0.95, "text": "潍坊银行2021年上半年净利润同比增长29.57% 不良率降至1.10%\n中国网财经8月24日讯 潍坊银行昨日披露2021年二季度信息报告显示,截至2021年6月末,潍坊银行资产总额1920.44亿元,较上年末增长9.34%;负债总额1789.16亿元,较上年末增长10.54%。2021年上半年,潍坊银行实现净利润6.09亿元,同比增长29.57%。\n资产质量方面,截至2021年6月末,潍坊银行不良贷款率1.10%,较上年末下降0.13个百分点。\n资本金方面,截至2021年6月末,潍坊银行资本充足率、核心一级资本充足率、一级资本充足率分别为11.66%、7.89%、10.13%,分别较上年末下降1.89、0.89、1.15个百分点。", "url": "http://finance.china.com.cn/news/special/2021bnb/20210824/5638343.shtml", "source_domain": "finance.china.com.cn" }- "title": 【字符串】数据文本的标题。
- "score": 【浮点数】由质量评估模型生成的质量分数。
- "text": 【字符串】数据样本的文本内容。
- "url": 【字符串】外部URL,指向文本的原始网页地址。
- "source_domain": 【字符串】源网站的域名。
EvalWeb
简介
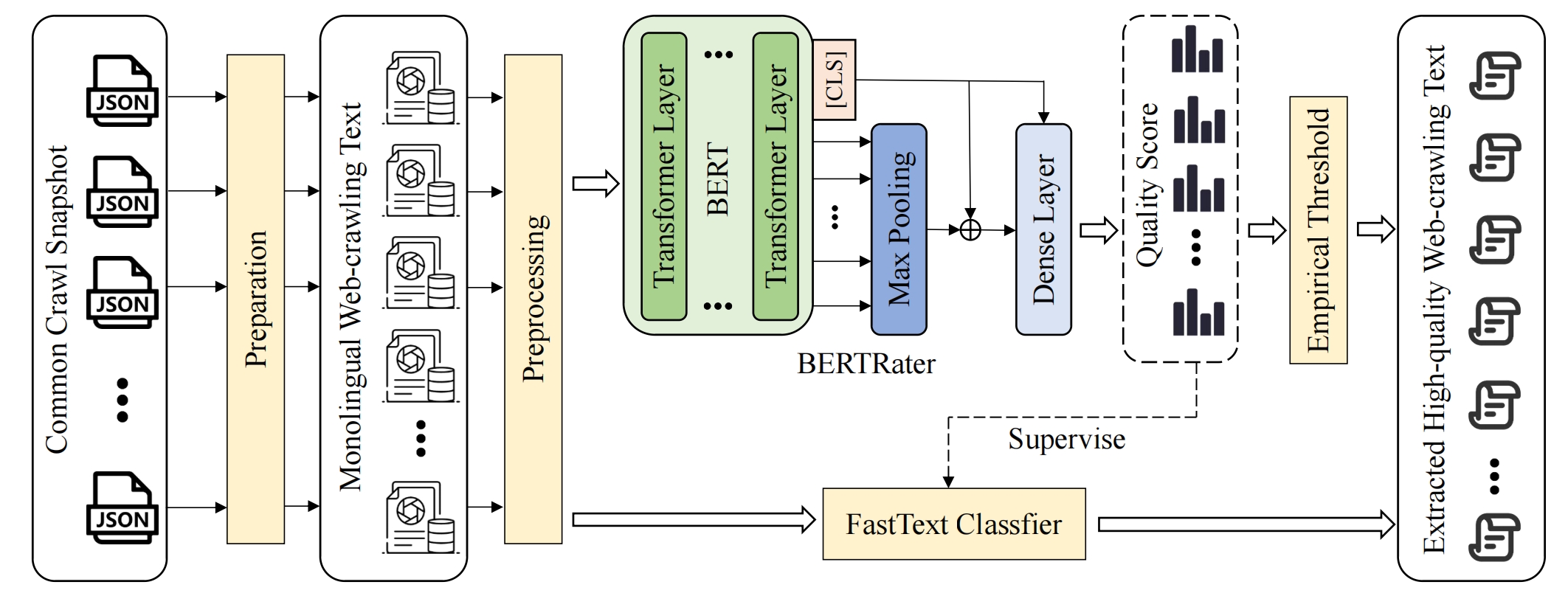
我们引入了一个新的完整工具链EvalWeb(见图1),它可以从原始网页数据中提取高质量的中文文本。对于从网络爬取的数据,我们首先使用准备模块进行处理,然后提取单语中文数据。之后,预处理模块将使用手工制定的规则进行进一步过滤,包括数据长度、敏感词、中文字符比例等。最后,使用基于BERT的评估模型来评估过滤后数据的质量。通过这种方式,我们可以为每个文本生成一个质量分数,然后使用适当的阈值来提取我们所需的高质量数据。此外,考虑到计算成本和效率,我们还提出利用知识蒸馏技术来训练FastText分类器,它可以以更快的效率和更低的计算成本达到类似的性能。
环境依赖
scikit-learn==1.3.0
transformers==4.31.0
scipy==1.11.1
numpy==1.24.3
pytorch==2.0.1
jieba==0.42.1
zhconv==1.4.3
fasttext==0.9.2
第一阶段:数据准备
1. 使用CCNet工具进行去重和语言识别(LID)
-
按照CCNet的工作,在这个模块中使用基于哈希的字符串间去重方法来移除不同CommonCrawl快照中的重复文本。此外,应用了一个经过良好训练的语言识别模型,可以支持157种语言,用于选择中文数据。通过这种方式,我们可以获得所需的所有单语中文文本数据。
-
运行脚本:
python -m cc_net --config config/my_config_2023-23.json -
输出:
/data/mined_split/2023-23/{0-4999}/zh_[head|middle|tail].json.gz -
config/my_config_2023-23.json:
{
"hash_in_mem": 10,
"dump": "2023-23",
"task_parallelism": 20,
"num_shards": 5000,
"mine_num_processes": 20,
"num_segments_per_shard":-1,
"lang_whitelist": ["zh","en"],
"lang_blacklist": [],
"lang_threshold": 0.5,
"keep_bucket": [],
"pipeline": ["dedup", "lid", "keep_lang", "sp", "lm", "pp_bucket", "drop", "split_by_lang"],
"metadata": "None",
"execution": "local",
"output_dir": "data",
"mined_dir": "mined",
"target_size": "4G",
"min_len": 300,
"cache_dir": "/mnt/data/ccnet_data/commoncrawl"
}
2. 拆分数据并合并为jsonl文件
- 运行 python merge2jsonl.py
python merge2jsonl.py --source /mnt/data/ccnet_clean/cc_net/data/mined_split/2023-23 --target /mnt/data/cc_cleaned/2023-23
- 输出:
cleared*.jsonl
第二阶段:预处理
本节重点关注通过使用手工制定的规则从中文单语网络数据中提取高质量文本,过滤掉暴力、色情、广告内容和错误字符。过滤规则的详细内容如下:
-
文本提取
从数据准备阶段后的jsonl文件中提取文本内容。
-
数据长度
为改善语言模型训练,如果文档的平均行长度少于10个字符或总文本长度少于200个字符,将被过滤掉,因为这样的短文本通常缺乏有意义的上下文和语义相关性。
-
字符比例
我们旨在从网络数据中创建一个高质量的简体中文数据集,通过消除繁体中文字符并删除中文字符比例少于**30%**的文本,确保数据集适合训练大型语言模型。
-
敏感词
为防止大型语言模型生成有害内容,提出了一种方法,分析文本中预定义列表中有害词的出现情况,任何每行有害词出现次数超过0.5次的文本都被归类为有害内容,并从训练数据集中移除。
-
内部重复
为提高训练效率和模型性能,随后使用13-gram粒度进行分析,识别并过滤掉每个数据条目中超过**50%**字符序列重复的数据样本。
以下是运行预处理阶段的示例命令:
python preprocess.py --dates 2023-06 2023-14
传入的**"dates"**参数对应于准备阶段生成的快照文件夹名称。
然后,您将在相应日期的文件夹下得到六个子文件夹。这六个文件夹分别命名为**"text_extraction"、"length"、"Character"、"sensitive"、"duplication"和"remain"。"text_extraction"文件夹包含从每条数据中提取文本后的结果,而"length"、"Character"、"sensitive"和"duplication"对应四个过滤操作,存储过滤掉的噪声数据。"remain"**文件夹存储预处理阶段后剩余的数据,这些数据随后将通过我们的评估模型进行评分。
第三阶段:质量评估
在预处理过程中,我们使用了一些手工制定的规则来从数据集中移除明显的噪声文本。然而,在剩余的数据中,仍然存在相当数量的低质量文本数据,这些数据无法通过手工规则过滤掉。为了从中提取更高质量的数据,本节我们进一步提出设计评估模型。
阶段3.1: BERTEval
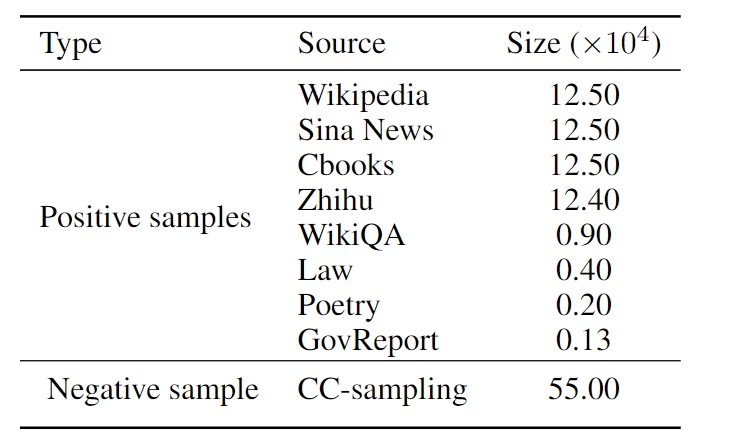
1. BERTEval训练数据组成
2. BERTEval训练和推理
-
步骤1: 两阶段训练
python train.py # 第一阶段 你可以修改configs/base_config.json来设置超参数 python train_ust.py # 第二阶段 你可以修改configs/ust_config.json来设置超参数 -
步骤2: 将之前处理过的CommonCrawl分割成多个分片,每个分片是一个JSON文件。单个快照的所有分片存储在同一路径下。参考示例
util/text_separate.py。 -
步骤3: 运行Python推理脚本
pred.py,使用换行符\n或句号等分隔符将每个文本分割成最大长度为512的完整段落。为每个段落预测文本质量得分。配置可以通过config/pred_config.json修改,关键参数如下:"data_path": ccnet数据路径 "output_path": 存储评分数据的路径 "num_workers": 数据预处理的CPU进程数 "batch_size": BERT批处理大小 "checkpoint": 模型检查点路径 "tokenizer_path": 存储BERT分词器的路径 "pretrained_model_path": 预训练BERT权重路径其他参数无需修改。处理后的文本存储在多个JSONL文件中。然后运行
python pred.py步骤4: 设置阈值$T$并保留质量阈值大于$T$的文本数据。由于bert-base的最大输入token限制为512,对于更长的文本,它们被分割成多个文本段。对于同一文档中连续的、阈值大于$T$的文本段,程序会自动将它们连接起来。这个功能在
utils/util.py中的text_select_with_pred(file, score_threshold)函数中实现。用法:
file = "test/data/cleared0_0000.jsonl" score_threshold = 0.99 selected_data = text_select_with_pred(file, score_threshold)
阶段3.2: FastText
1. FastText训练数据组成

2. FastText训练和推理
我们在**"fasttext"文件夹中提供了FastText训练数据示例和训练脚本。你可以在这里下载我们训练好的FastText模型,并替换位于"./fasttext/output/model.bin"**的现有文件。
cd fasttext
python main.py --mode train --train_file ./data/train.txt --test_file ./data/test.txt
要了解构建**"train.txt"和"test.txt"文件的过程,请参考"./data/build_data.py"**。
训练好的模型**"model.bin"将存储在"output"**文件夹中。
获得预处理阶段后剩余的数据(应该存储在类似**"./2023-06/remain"**的路径中)后,你可以使用我们的FastText模型对所有数据进行评分:
python main.py --mode test --dates 2023-06 2023-14
这一步将为每个数据条目分配一个FastText得分,结果将存储在类似**"./2023-06/remain/fasttext"**的目录中。随后,你可以使用这些得分通过设置阈值(默认设为0.5)来过滤和提取高质量数据。
引用
如果您使用了本仓库中的数据或代码,请引用以下论文:
@misc{chen2023chinesewebtext,
title={ChineseWebText: Large-scale High-quality Chinese Web Text Extracted with Effective Evaluation Model},
author={Jianghao Chen and Pu Jian and Tengxiao Xi and Dongyi Yi and Qianlong Du and Chenglin Ding and Guibo Zhu and Chengqing Zong and Jinqiao Wang and Jiajun Zhang},
year={2023},
eprint={2311.01149},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











