
🇨🇭🎖️🦙 瑞士军刀羊驼

介绍
瑞士军刀羊驼旨在通过使用FastAPI公开方便的REST端点来促进和优化使用本地LLM的过程,用于各种任务,包括通过llama_cpp使用不同LLM获取文本嵌入和完成任务,并自动获取最常见文档类型的所有嵌入,包括PDF(即使需要OCR的PDF)、Word文件等文件;它甚至允许您提交一个音频文件,并自动使用Whisper模型转录它,清理所得文本,然后计算其嵌入。为了避免浪费计算资源,这些嵌入缓存于SQlite中,并在之前已计算的情况下被检索。为了加快加载多个LLM的过程,可以使用可选的RAM磁盘,创建和管理它们的过程是自动处理的。通过一个快速和简单的安装过程,您将立即获得一个名副其实的“瑞士军刀”级别的LLM相关工具,所有这些工具都可以通过便捷的Swagger UI访问,并可以最小的麻烦和配置集成到您自己的应用程序中。
提供了一些其它有用的端点,例如计算提交文本字符串之间的语义相似度。该服务利用了一个高性能的基于Rust的库fast_vector_similarity,提供一系列相似度测量方法,包括spearman_rho、kendall_tau、approximate_distance_correlation、jensen_shannon_similarity和hoeffding_d。另外,使用FAISS向量搜索支持跨所有缓存嵌入进行语义搜索。您可以使用FAISS内置的余弦相似度,或通过计算找到的存储矢量最相关子集的更复杂的相似度测量来补充这一点(请参阅高级语义搜索端点以获取此功能)。
此外,我们现在还支持多种嵌入池化方法,将Token级嵌入向量组合成一个固定长度的嵌入向量,适用于任何长度的输入文本,包括以下几种方法:
mean:Token嵌入的平均池化。mins_maxes:Token嵌入每个维度的最小值和最大值的拼接。svd:Token嵌入矩阵的奇异值分解(SVD)得到的前两个奇异向量的拼接。svd_first_four:Token嵌入矩阵的奇异值分解(SVD)得到的前四个奇异向量的拼接。ica:独立成分分析(ICA)得到的平展独立成分。factor_analysis:因子分析得到的平展因子。gaussian_random_projection:高斯随机投影得到的平展嵌入。
如上所述,您现在不仅可以提交纯文本和完全数字化的PDF,还可以提交MS Word文档、图像以及由textract库支持的其他文件类型。该库可以自动使用 Tesseract 对扫描文本应用 OCR。返回的每个句子的嵌入可以使用Pandas的to_json()函数以各种格式(如记录、表格等)组织。结果可以作为包含JSON文件的ZIP文件返回,或者作为直接的JSON响应。您现在还可以提交MP3或WAV格式的音频文件。该库使用OpenAI的Whisper模型,由Faster Whisper Python库优化,将音频转录为文本。可选地,该转录本可以像任何其他文档一样处理,计算每个句子的嵌入并存储这些嵌入。结果作为指向包含嵌入向量数据的JSON的可下载ZIP文件的URL返回。
最后,我们新增了一个端点,用于为给定的输入提示生成多个文本完成,并提供指定一个语法文件以强制响应的特定格式,例如JSON。还有一个有用的新实用功能:可以通过web浏览器访问的实时应用程序日志查看器,允许进行语法高亮显示并提供下载日志或将其复制到剪贴板的选项。这样,用户可以在无需直接SSH访问服务器的情况下监视日志。
截图
总结: 如果您只是想在一台新的Ubuntu 22+ 机器上快速尝试一下(注意,这将使用apt安装docker):
git clone https://github.com/Dicklesworthstone/swiss_army_llama
cd swiss_army_llama
chmod +x setup_dockerized_app_on_fresh_machine.sh
sudo ./setup_dockerized_app_on_fresh_machine.sh
要在Python虚拟环境(推荐!)中本地运行它(不使用Docker),您可以使用以下命令:
sudo apt-get update
sudo apt-get install build-essential libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig redis-server libpoppler-cpp-dev pkg-config -y
sudo systemctl enable redis-server
sudo systemctl start redis
git clone https://github.com/Dicklesworthstone/swiss_army_llama
cd swiss_army_llama
python3 -m venv venv
source venv/bin/activate
python3 -m pip install --upgrade pip
python3 -m pip install wheel
python3 -m pip install --upgrade setuptools wheel
pip install -r requirements.txt
python3 swiss_army_llama.py
或者,您也可以运行包含的脚本,这将安装PyEnv(如果它尚未安装在您的机器上),然后安装Python 3.12并为您创建一个虚拟环境。您可以像这样在一台新的Ubuntu机器上用单行命令完成所有操作:
git clone https://github.com/Dicklesworthstone/swiss_army_llama && cd swiss_army_llama && chmod +x install_swiss_army_llama.sh && ./install_swiss_army_llama.sh && pyenv local 3.12 && source venv/bin/activate && python swiss_army_llama.py
然后,打开浏览器到<your_static_ip_address>:8089,如果您使用的是VPS,请访问FastAPI Swagger页面http://localhost:8089。
或者,如果您使用自己的机器,请访问localhost:8089——不过,真的,您永远不应该在自己的机器上使用sudo运行不受信任的代码!只需花费$30/月获得一个便宜的VPS来实验。
观看自动安装过程这里。
功能
- 文本嵌入计算:通过llama_cpp使用预训练的LLama3和其他大语言模型(LLM)生成提供的文本嵌入。
- 嵌入缓存:在SQLite中高效地存储和检索计算的嵌入,最大限度地减少冗余计算。
- 高级相似度测量和检索:使用作者自己用Rust编写的
fast_vector_similarity库,提供高度优化的高级相似度测量,例如spearman_rho、kendall_tau、approximate_distance_correlation、jensen_shannon_similarity和hoeffding_d。还支持使用FAISS向量搜索对缓存的嵌入进行语义搜索。 - 两步高级语义搜索:API首先利用FAISS和余弦相似性进行快速过滤,然后应用其他相似度测量如
spearman_rho、kendall_tau、approximate_distance_correlation、jensen_shannon_similarity和hoeffding_d进行更细致的比较。 - 文件处理:库现在接受更广泛的文件类型,包括纯文本、PDF、MS Word文档和图像。它还可以自动处理OCR。每个句子的返回嵌入组织为不同格式,如记录、表格等,使用Pandas的to_json()函数。
- 高级文本预处理:该库现在采用更先进的句子拆分器,将文本分段为有意义的句子。它处理缩写、域名或数字中的句号,并确保在引号使用时也能完成句子。它还处理扫描文档中常见的分页问题,例如尴尬的换行和连字符断行。
- 音频转录和嵌入:上传MP3或WAV格式的音频文件。库使用OpenAI的Whisper模型进行转录。可选地,可以为转录计算句子嵌入。
- RAM磁盘使用:可选地使用RAM磁盘存储模型,以便更快的访问和执行。自动处理RAM磁盘的创建和管理。
- 强大的异常处理:具有全面的异常管理功能,以确保系统的弹性。
- 交互式API文档:与Swagger UI集成,提供交互式和用户友好的体验,处理大结果集时不会崩溃。
- 可伸缩性和并发处理:基于FastAPI框架构建,处理并发请求,并支持具有可配置并发级别的并行推理。
- 灵活配置:通过环境变量和输入参数提供可配置的设置,包括JSON或ZIP文件等响应格式。
- 全面的日志记录:捕获详细日志记录的关键信息,不会过度占用存储或影响可读性。
- 支持多种模型和测量:支持多种嵌入模型和相似度测量,允许根据用户需求进行灵活和定制化。
- 使用指定语法生成多个完成:返回针对指定输入提示的结构化LLM完成。
- 浏览器中的实时日志文件查看器:让任何有权访问API服务器的人方便地观看应用日志,了解他们请求的执行情况。
- 使用Redis进行请求锁定:使用Redis允许多个Uvicorn工作者并行运行而不冲突。
运行中的演示屏幕录制
这里是我从Swagger页面进行请求时的实时控制台输出。
要求
运行应用程序所需的系统要求(支持textract处理的所有文件类型):
sudo apt-get update
sudo apt-get install libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig -y
Python要求:
aioredis
aioredlock
aiosqlite
apscheduler
faiss-cpu
fast_vector_similarity
fastapi
faster-whisper
filelock
httpx
llama-cpp-python
magika
mutagen
nvgpu
pandas
pillow
psutil
pydantic
PyPDF2
pytest
python-decouple
python-multipart
pytz
redis
ruff
scikit-learn
scipy
sqlalchemy
textract-py3
uvicorn
uvloop
zstandard
运行应用程序
你可以使用以下命令运行应用程序:
python swiss_army_llama.py
服务器将在0.0.0.0上以SWISS_ARMY_LLAMA_SERVER_LISTEN_PORT变量定义的端口启动。
访问Swagger UI:
http://localhost:<SWISS_ARMY_LLAMA_SERVER_LISTEN_PORT>
配置
你可以通过编辑包含的.env文件轻松配置服务。以下是可用的配置选项列表:
USE_SECURITY_TOKEN:是否使用硬编码的安全令牌。(例如,1)USE_PARALLEL_INFERENCE_QUEUE:使用并行处理。(例如,1)MAX_CONCURRENT_PARALLEL_INFERENCE_TASKS:最大并行推理任务数量。(例如,30)DEFAULT_MODEL_NAME:默认使用的模型名称。(例如,Llama-3-8B-Instruct-64k)LLM_CONTEXT_SIZE_IN_TOKENS:LLM的上下文大小,以词标记为单位。(例如,512)SWISS_ARMY_LLAMA_SERVER_LISTEN_PORT:服务端口号。(例如,8089)UVICORN_NUMBER_OF_WORKERS:Uvicorn的工作者数量。(例如,2)MINIMUM_STRING_LENGTH_FOR_DOCUMENT_EMBEDDING:文档嵌入的最小字符串长度。(例如,15)MAX_RETRIES:锁定数据库的最大重试次数。(例如,10)DB_WRITE_BATCH_SIZE:数据库写入批处理大小。(例如,25)RETRY_DELAY_BASE_SECONDS:重试延迟基数,以秒为单位。(例如,1)JITTER_FACTOR:重试的抖动因子。(例如,0.1)USE_RAMDISK:使用RAM磁盘。(例如,1)RAMDISK_PATH:RAM磁盘路径。(例如,"/mnt/ramdisk")RAMDISK_SIZE_IN_GB:RAM磁盘大小,以GB为单位。(例如,40)
贡献
如果你想为该项目做贡献,请提交一个拉取请求!真的,我希望能有更多的社区参与进来,这样我们可以将其打造为一个标准库!
许可证
本项目遵循MIT许可证。
我在Google上找到的一些Llama刀片图片


设置和配置
RAM磁盘配置
要启用RAM磁盘的无密码sudo设置和拆卸,请使用sudo visudo编辑sudoers文件。添加以下几行,并将username替换为你的实际用户名:
username ALL=(ALL) NOPASSWD: /bin/mount -t tmpfs -o size=*G tmpfs /mnt/ramdisk
username ALL=(ALL) NOPASSWD: /bin/umount /mnt/ramdisk
应用程序提供了设置、清除和管理RAM磁盘的功能。RAM磁盘用于在内存中存储模型以便更快的访问。它计算可用的RAM并相应地设置RAM磁盘。setup_ramdisk、copy_models_to_ramdisk和clear_ramdisk函数管理这些任务。
API端点
以下端点可用:
- GET
/get_list_of_available_model_names/: 检索可用的模型名称。获取用于生成嵌入的可用模型名称列表。 - GET
/get_all_stored_strings/: 检索所有存储的字符串。从数据库中获取所有已计算嵌入的存储字符串列表。 - GET
/get_all_stored_documents/: 检索所有存储的文档。从数据库中获取所有已计算嵌入的存储文档列表。 - GET
/show_logs/: 默认显示最近5分钟的日志。还可以提供如下参数:/show_logs/{minutes}获取最近N分钟的日志数据。 - POST
/add_new_model/: 通过 URL 添加新模型。提交新模型的URL进行下载和使用。模型必须是.gguf格式且大于100MB,以确保它是一个有效的模型文件(可以直接粘贴Huggingface URL)。 - POST
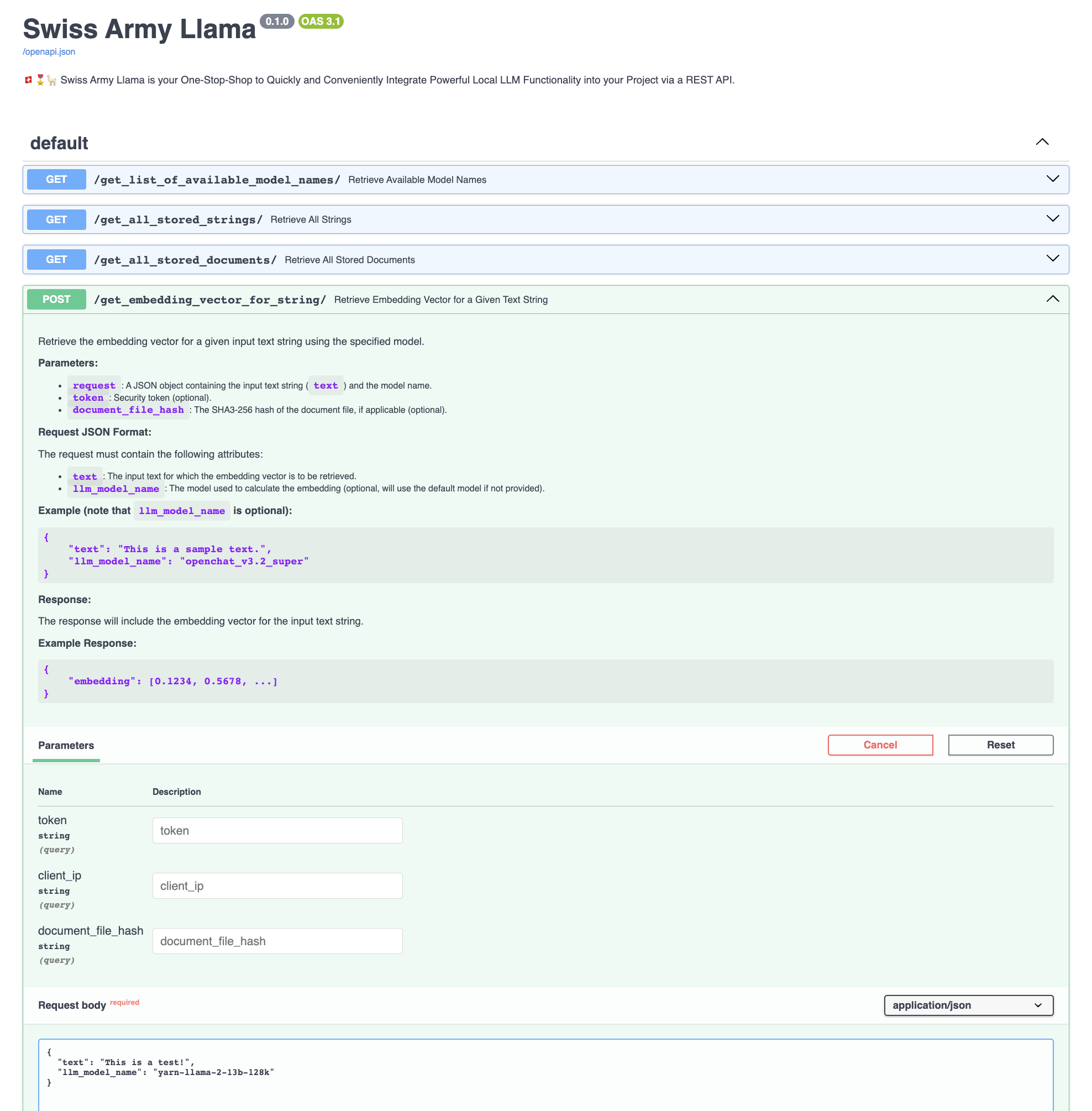
/get_embedding_vector_for_string/: 获取给定文本字符串的嵌入向量。使用指定的模型获取给定输入文本字符串的嵌入向量。 - POST
/compute_similarity_between_strings/: 计算两个字符串之间的相似度。利用fast_vector_similarity库,使用指定模型嵌入和选定的相似度度量计算两个给定输入字符串之间的相似度。 - POST
/search_stored_embeddings_with_query_string_for_semantic_similarity/: 从数据库中存储的嵌入中获取最相似的字符串。找到与给定输入“查询”文本数据库中最相似的字符串。 - POST
/advanced_search_stored_embeddings_with_query_string_for_semantic_similarity/: 执行两步高级语义搜索。首先使用FAISS和余弦相似度缩小最相似的字符串范围,然后应用其他相似度措施进行精细比较。 - POST
/get_all_embedding_vectors_for_document/: 获取文档的嵌入。提取文档的文本嵌入。此端点支持纯文本,.doc/.docx(MS Word),PDF文件,图像(使用Tesseract OCR)以及许多其他由textract库支持的文件类型。 - POST
/compute_transcript_with_whisper_from_audio/: 使用Whisper和LLM转录和嵌入音频。此端点接受音频文件,并可选择计算文档嵌入。存储转录和嵌入,并可以下载包含嵌入的ZIP文件。 - POST
/get_text_completions_from_input_prompt/: 从指定的LLM模型获取多个补全,能够指定语法文件以强制响应格式,如JSON。 - POST
/clear_ramdisk/: 清除RAM磁盘端点。如果启用了RAM磁盘,则清除其内容。
有关详细的请求和响应模式,请参见根URL或本README结尾部分的Swagger UI。
异常处理
该应用程序具有强大的异常处理能力,用于处理各种类型的错误,包括数据库错误和普通异常。自定义异常处理器定义了SQLAlchemyError和常规Exception。
日志记录
日志记录配置为INFO级别,为调试和监控提供详细日志。记录器提供有关应用程序状态、错误和活动的信息。
日志存储在一个名为swiss_army_llama.log的文件中,并且实现了日志轮转机制来处理日志文件备份。旋转文件处理程序配置了最大文件大小为10MB,并保留最多5个备份文件。
当日志文件达到最大大小时,它会移动到old_logs目录,并创建一个新日志文件。日志条目也打印到标准输出流。
以下是日志配置的一些详细信息:
- 日志级别:INFO
- 日志格式:
%(asctime)s - %(levelname)s - %(message)s - 最大日志文件大小:10 MB
- 备份数量:5
- 旧日志目录:
old_logs
此外,SQLAlchemy引擎的日志级别设置为WARNING,以抑制详细的数据库日志。
数据库结构
该应用使用SQLite数据库通过SQLAlchemy ORM。以下是使用的数据模型,可以在embeddings_data_models.py文件中找到:
文本嵌入表
id: 主键text: 计算嵌入的文本text_hash: 使用SHA3-256计算的文本哈希embedding_pooling_method: 嵌入时使用的池化方法embedding_hash: 计算出的嵌入哈希llm_model_name: 用于计算嵌入的模型corpus_identifier_string: 用于将嵌入分组到特定语料库的可选字符串标识符embedding_json: 以JSON格式计算出的嵌入ip_address: 客户端IP地址request_time: 请求的时间戳response_time: 响应的时间戳total_time: 处理请求花费的总时间document_file_hash: 参考文档嵌入表的外键document: 与文档嵌入的关系
文档嵌入表
id: 主键document_hash: 参考文档表的外键filename: 文档文件名mimetype: 文档文件的MIME类型document_file_hash: 文件的哈希值embedding_pooling_method: 嵌入时使用的池化方法llm_model_name: 用于计算嵌入的模型corpus_identifier_string: 用于将文档分组到特定语料库的可选字符串标识符file_data: 原始文件的二进制数据sentences: 从文档中提取的句子document_embedding_results_json_compressed_binary: 使用Z标准压缩的JSON格式计算出的嵌入结果ip_address: 客户端IP地址request_time: 请求的时间戳response_time: 响应的时间戳total_time: 处理请求花费的总时间embeddings: 与文本嵌入的关系document: 与文档的关系
文档表
id: 主键llm_model_name: 与文档关联的模型名称corpus_identifier_string: 用于将文档分组到特定语料库的可选字符串标识符document_hash: 计算出的文档哈希document_embeddings: 与文档嵌入的关系
音频转录表
audio_file_hash: 主键audio_file_name: 音频文件名audio_file_size_mb: 文件大小(以MB计)segments_json: 转录段落的JSON格式combined_transcript_text: 组合的转录文本combined_transcript_text_list_of_metadata_dicts: 每段组合转录文本的元数据字典列表info_json: 转录信息的JSON格式ip_address: 客户端IP地址request_time: 请求的时间戳response_time: 响应的时间戳total_time: 处理请求花费的总时间corpus_identifier_string: 用于将转录分组到特定语料库的可选字符串标识符
数据库关系
-
文本嵌入 - 文档嵌入:
TextEmbedding有一个外键document_file_hash参考DocumentEmbedding的document_file_hash。- 这意味着多个文本嵌入可以属于一个文档嵌入,建立了一个一对多关系。
-
文档嵌入 - 文档:
DocumentEmbedding有一个外键document_hash参考Document的document_hash。- 这建立了
Document和DocumentEmbedding之间的一对多关系。
-
音频转录:
- 根据给定代码,该表与其他表没有直接关系。
-
请求/响应模型:
- 这些不直接与数据库表相关,但用于处理API请求和响应。
- 以下Pydantic模型用于请求和响应验证:
- EmbeddingRequest
- SimilarityRequest
- SemanticSearchRequest
- SemanticSearchResponse
- AdvancedSemanticSearchRequest
- AdvancedSemanticSearchResponse
- EmbeddingResponse
- SimilarityResponse
- AllStringsResponse
- AllDocumentsResponse
- TextCompletionRequest
- TextCompletionResponse
- ImageQuestionResponse
- AudioTranscriptResponse
- ShowLogsIncrementalModel
- AddGrammarRequest
- AddGrammarResponse
有关字段详细说明和验证,请参阅embeddings_data_models.py文件。
性能优化
本部分强调了集成到提供代码中的主要性能增强,以确保快速响应和最佳资源管理。
1. 异步编程:
- 好处:并发处理多个任务,提高数据库事务和网络请求等I/O绑定操作的效率。
- 实现:使用Python的
asyncio库进行异步数据库操作。
2. 数据库优化:
- 提前写日志(WAL)模式:允许并发读写,优化频繁写入需求的应用。
- 指数退避重试逻辑:通过渐进等待时间重试操作,管理锁定的数据库。
- 批量写入:聚合写入操作以更高效地数据库交互。
- 数据库写入队列:使用异步队列序列化写入操作,确保一致和无冲突的数据库写入。
3. RAM磁盘使用:
- 好处:通过将操作优先放在RAM而不是磁盘上,加速I/O绑定任务。
- 实现:检测并优先使用RAM磁盘(
/mnt/ramdisk),如果不可用,则默认为标准文件系统。
4. 模型缓存:
- 好处:通过在内存中保留加载的模型以供后续请求使用,减少开销。
- 实现:使用全局
model_cache字典存储和检索模型。
5. 并行推理:
- 好处:为多个数据单元(如文档句子)提升处理速度。
- 实现:使用
asyncio.gather并发进行推理,由信号量(MAX_CONCURRENT_PARALLEL_INFERENCE_TASKS)控制。
6. 嵌入缓存:
- 优势: 一旦计算了特定文本的嵌入,这些嵌入将存储在数据库中,消除了在后续请求中重新计算的需要。
- 实现: 当请求计算嵌入时,系统首先检查数据库。如果找到给定文本的嵌入,则立即返回,确保响应时间更快。
Docker化版本
此仓库中包含一个bash脚本 setup_dockerized_app_on_fresh_machine.sh,它将自动为你完成所有步骤,包括使用apt install来安装Docker。
使用方法如下,首先使脚本可执行,然后按以下方式运行:
chmod +x setup_dockerized_app_on_fresh_machine.sh
sudo ./setup_dockerized_app_on_fresh_machine.sh
如果你更喜欢手动设置,请阅读以下说明:
前提条件
确保你的系统中安装了Docker。如果没有,请按照以下步骤在Ubuntu上安装Docker:
sudo apt-get update
sudo apt-get install docker.io
sudo systemctl start docker
sudo docker --version
sudo usermod -aG docker $USER
你可能需要注销并重新登录,或者重启系统以应用新的组权限,或在以下步骤中使用sudo来构建和运行容器。
设置和运行应用程序
-
克隆仓库:
克隆这个名为Swiss Army Llama的仓库到你的本地机器:
git clone https://github.com/Dicklesworthstone/swiss_army_llama cd swiss_army_llama -
构建Docker镜像:
使用提供的Dockerfile构建Docker镜像:
sudo docker build -t llama-embeddings . -
运行Docker容器:
运行Docker容器,将容器的8089端口映射到主机的8089端口:
sudo docker run -p 8089:8089 llama-embeddings -
访问应用程序:
FastAPI应用程序现在可以通过
http://localhost:8089访问,或者如果你在VPS实例上运行,则可以通过静态IP地址访问 (可以在Contabo以约30美元/月的价格获得一个10核,30GB RAM,1TB SSD的静态IP运行Ubuntu 22.04的VPS,这是我目前找到的最便宜的选择)。然后你可以使用诸如
curl等工具与API交互,或访问FastAPI文档http://localhost:8089/docs. -
查看日志:
可以在运行
docker run命令的终端中直接查看应用程序的日志。
停止和管理容器
- 要停止运行的容器,请在终端中按
Ctrl+C或使用docker ps找到容器ID,然后运行sudo docker stop <container_id>. - 要删除构建好的镜像,使用
sudo docker rmi llama-embeddings.
启动程序
在启动过程中,应用程序执行以下任务:
- 数据库初始化:
- 应用程序初始化SQLite数据库,设置表并执行重要的PRAGMA以优化性能。
- 一些重要的SQLite PRAGMA包括将数据库设置为使用预写日志(WAL)模式,将同步模式设置为NORMAL,将缓存大小增加到1GB,将忙等待超时设置为2秒,并将WAL自动检查点设置为100。
- 初始化数据库写入器:
- 使用专用的异步队列初始化一个专用的数据库写入器 (
DatabaseWriter) 以处理写入操作。 - 创建一组哈希值,代表当前正在处理或已处理的操作。这样可以避免队列中的重复操作。
- 使用专用的异步队列初始化一个专用的数据库写入器 (
- RAM磁盘设置:
- 如果
USE_RAMDISK变量开启且用户具有所需权限,应用程序将设置一个RAM磁盘。 - 应用程序检查指定路径是否已设置RAM磁盘,如果没有,计算RAM磁盘的最优大小并进行设置。
- 如果启用了RAM磁盘但用户缺乏所需权限,RAM磁盘功能将被禁用,应用程序将继续运行。
- 如果
- 模型下载:
- 应用程序下载所需的模型。
- 模型加载:
- 每个下载的模型都会加载到内存中。如果未找到任何模型文件,将记录错误日志。
- 构建FAISS索引:
- 使用数据库中的嵌入,应用程序创建FAISS索引以便高效的相似性搜索。
- 按模型名称存储相关文本以供进一步使用。
注意:
- 如果启用了RAM磁盘功能但用户缺乏所需权限,应用程序将禁用RAM磁盘功能并继续运行。
- 对于任何数据库操作,如果数据库被锁定,应用程序将尝试重试操作几次,并采用指数退避和随机抖动策略。
端点功能和工作流程概述
以下是FastAPI服务器提供的主要端点的详细说明,解释了它们的功能、输入参数以及它们如何与底层模型和系统进行交互:
1. /get_embedding_vector_for_string/ (POST)
目的
使用指定模型检索给定输入文本字符串的嵌入向量。
参数
text: 要检索嵌入向量的输入文本。model_name: 用于计算嵌入的模型(可选,如果未提供将使用默认模型)。token: 安全令牌(可选)。client_ip: 客户端IP地址(可选)。
工作流程
- 检索嵌入: 函数使用指定或默认模型检索或计算提供文本的嵌入向量。
- 返回结果: 返回输入文本字符串的嵌入向量。
2. /compute_similarity_between_strings/ (POST)
目的
使用指定模型嵌入和选择的相似性度量计算两个给定输入字符串之间的相似性。
参数
text1: 第一个输入文本。text2: 第二个输入文本。llm_model_name: 用于计算嵌入的模型(可选)。similarity_measure: 要使用的相似性度量。支持的度量包括all、spearman_rho、kendall_tau、approximate_distance_correlation、jensen_shannon_similarity和hoeffding_d(可选,默认值是all)。
工作流程
- 检索嵌入: 使用指定或默认模型检索或计算
text1和text2的嵌入。 - 计算相似性: 使用指定的相似性度量计算两个嵌入之间的相似性。
- 返回结果: 返回相似性分数、嵌入和输入文本。
3. /search_stored_embeddings_with_query_string_for_semantic_similarity/ (POST)
目的
找到数据库中与给定输入“查询”文本最相似的字符串。此端点使用预先计算的FAISS索引快速搜索最接近的匹配字符串。
参数
query_text: 要查找最相似字符串的输入文本。model_name: 用于计算嵌入的模型。number_of_most_similar_strings_to_return: (可选)要返回的最相似字符串的数量,默认值为10。token: 安全令牌(可选)。
工作流程
- 搜索FAISS索引: 在FAISS索引中,搜索与
query_text最相似的嵌入。 - 返回结果: 返回数据库中找到的最相似字符串及其相似性分数。
4. /advanced_search_stored_embeddings_with_query_string_for_semantic_similarity/ (POST)
目的
执行两步高级语义搜索。使用FAISS和余弦相似性进行初步过滤,然后使用其它相似性度量进行进一步比较。
参数
query_text: 要查找最相似字符串的输入文本。llm_model_name: 用于计算嵌入的模型。similarity_filter_percentage: (可选)基于余弦相似性过滤的嵌入百分比;默认为0.02(即前2%)。number_of_most_similar_strings_to_return: (可选)在第二相似性度量后要返回的最相似字符串的数量;默认为10。
工作流程
- 初步过滤: 使用FAISS和余弦相似性查找一组相似的字符串。
- 进一步比较: 对初步过滤的集合应用额外的相似性度量。
- 返回结果: 返回最相似的字符串及其多个相似性分数。
示例请求
{
"query_text": "Find me the most similar string!",
"llm_model_name": "openchat_v3.2_super",
"similarity_filter_percentage": 0.02,
"number_of_most_similar_strings_to_return": 5
}
5. /get_all_embedding_vectors_for_document/ (POST)
目的
提取文档的文本嵌入。该库现在支持多种文件类型,包括纯文本、.doc/.docx、PDF文件、图像(使用Tesseract OCR),以及许多由 textract 库支持的其它类型。
参数
file: 上传的文档文件(可以是纯文本、.doc/.docx、PDF等)。llm_model_name: (可选)用于计算嵌入的模型。json_format: (可选)JSON响应格式。send_back_json_or_zip_file: 返回一个JSON文件或一个包含嵌入文件的ZIP文件(可选,默认值为zip)。token: 安全令牌(可选)。
6. /compute_transcript_with_whisper_from_audio/ (POST)
目的
转录音频文件,并可选地为生成的转录计算文档嵌入。此端点使用Whisper模型进行转录,并使用语言模型生成嵌入。然后可以存储转录和嵌入,并提供包含嵌入的ZIP文件下载。
参数
file: 需要上传以进行转录的音频文件。compute_embeddings_for_resulting_transcript_document: 用于指示是否计算文档嵌入的布尔值(可选,默认为False)。llm_model_name: 用于计算嵌入的语言模型(可选,默认使用默认模型名)。req: 用于附加请求元数据的HTTP请求对象(可选)。token: 安全令牌(可选)。client_ip: 客户端IP地址(可选)。
请求文件和参数
您需要使用multipart/form-data请求来上传音频文件。其他参数如compute_embeddings_for_resulting_transcript_document和llm_model_name可以作为表单字段一起发送。
示例请求
curl -X 'POST' \
'http://localhost:8000/compute_transcript_with_whisper_from_audio/' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_ACCESS_TOKEN' \
-F 'file=@your_audio_file.wav' \
-F 'compute_embeddings_for_resulting_transcript_document=true' \
-F 'llm_model_name=custom-llm-model'
7. /get_text_completions_from_input_prompt/ (POST)
目的
使用指定的模型为给定的输入提示生成文本补全。
参数
request: 一个包含各种选项的JSON对象,如input_prompt、llm_model_name等。token: 安全令牌(可选)。req: HTTP请求对象(可选)。client_ip: 客户端IP地址(可选)。
请求JSON格式
JSON对象应包含以下键:
input_promptllm_model_nametemperaturegrammar_file_stringnumber_of_completions_to_generatenumber_of_tokens_to_generate
示例请求
{
"input_prompt": "The Kings of France in the 17th Century:",
"llm_model_name": "phind-codellama-34b-python-v1",
"temperature": 0.95,
"grammar_file_string": "json",
"number_of_tokens_to_generate": 500,
"number_of_completions_to_generate": 3
}
8. /get_list_of_available_model_names/ (GET)
目的
检索用于生成嵌入的可用模型名称列表。
参数
token: 安全令牌(可选)。
9. /get_all_stored_strings/ (GET)
目的
从数据库中检索已计算嵌入的所有字符串列表。
参数
token: 安全令牌(可选)。
10. /get_all_stored_documents/ (GET)
目的
从数据库中检索已计算嵌入的所有文档列表。
参数
token: 安全令牌(可选)。
11. /clear_ramdisk/ (POST)
目的
清除RAM磁盘以释放内存。
参数
token: 安全令牌(可选)。
12. /download/{file_name} (GET)
目的
下载包含通过/compute_transcript_with_whisper_from_audio/端点生成的文档嵌入的ZIP文件。该下载URL将在音频文件转录端点的JSON响应中提供。
参数
file_name: 您要下载的ZIP文件名称。
13. /add_new_model/ (POST)
目的
提交一个新的模型URL以进行下载和使用。模型必须是.gguf格式且大于100 MB,以确保其为有效的模型文件。
参数
model_url: 模型权重文件的URL,必须以.gguf结尾。token: 安全令牌(可选)。
Token-Level Embedding Vector Pooling
池化方法旨在聚合token级别的嵌入,这些嵌入由于句子或文档中token数量的不同而通常是可变长度的。通过将这些token级别的嵌入转换为单一的固定长度向量,我们确保每个输入文本无论其长度如何,都能被一致地表示。这个固定长度向量可以在需要一致大小输入的各种机器学习模型中使用。
这些池化方法的主要目标是尽可能保留原始token级嵌入中的有用信息,同时确保该转换是确定性的且不会扭曲数据。每种方法通过应用不同的统计或数学技术来总结token嵌入来达到这一目标。
池化方法的解释
-
SVD (奇异值分解):
- 工作原理: 连接从token嵌入矩阵的SVD中获得的前两个奇异向量。
- 原理: SVD是一种降维技术,它捕捉数据中最重要的特征。使用前两个奇异向量提供了一个紧凑的表示,保留了显著的信息。
-
SVD_First_Four:
- 工作原理: 使用从token嵌入矩阵的SVD中获得的前四个奇异向量。
- 原理: 通过使用更多的奇异向量,这种方法捕捉了数据中更多的方差,提供了更丰富的表示,同时仍然减少了维度。
-
ICA (独立成分分析):
- 工作原理: 将ICA应用于嵌入矩阵以查找统计上的独立成分,然后展开结果。
- 原理: ICA有助于识别数据中的独立来源,提供突出了这些独立特征的表示。
-
Factor_Analysis:
- 工作原理: 将因子分析应用于嵌入矩阵以识别潜在因素,然后展开结果。
- 原理: 因子分析以潜在因素的形式建模数据,提供了捕捉这些潜在影响的摘要。
-
Gaussian_Random_Projection:
- 工作原理: 将高斯随机投影应用于嵌入以减少维度,然后展开结果。
- 原理: 这种方法提供了一种快速高效的方式来减少维度,同时保留点之间的成对距离,适用于大型数据集。











