
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文REST: 基于检索的推测解码
如果训练让你焦头烂额,休息一下,速度翻倍。
新闻
🎉 2024-3-14: REST 被 NAACL 2024 接收!
简介
REST 是一种基于检索的推测解码方法,旨在提高大语言模型的生成速度。与依赖草稿语言模型的推测解码不同,REST 利用数据存储来检索和使用草稿标记。此外,REST 与分块并行解码和 Medusa 不同,它不需要额外的训练步骤。它作为一种即插即用的解决方案,能够加速任何现有的语言模型。
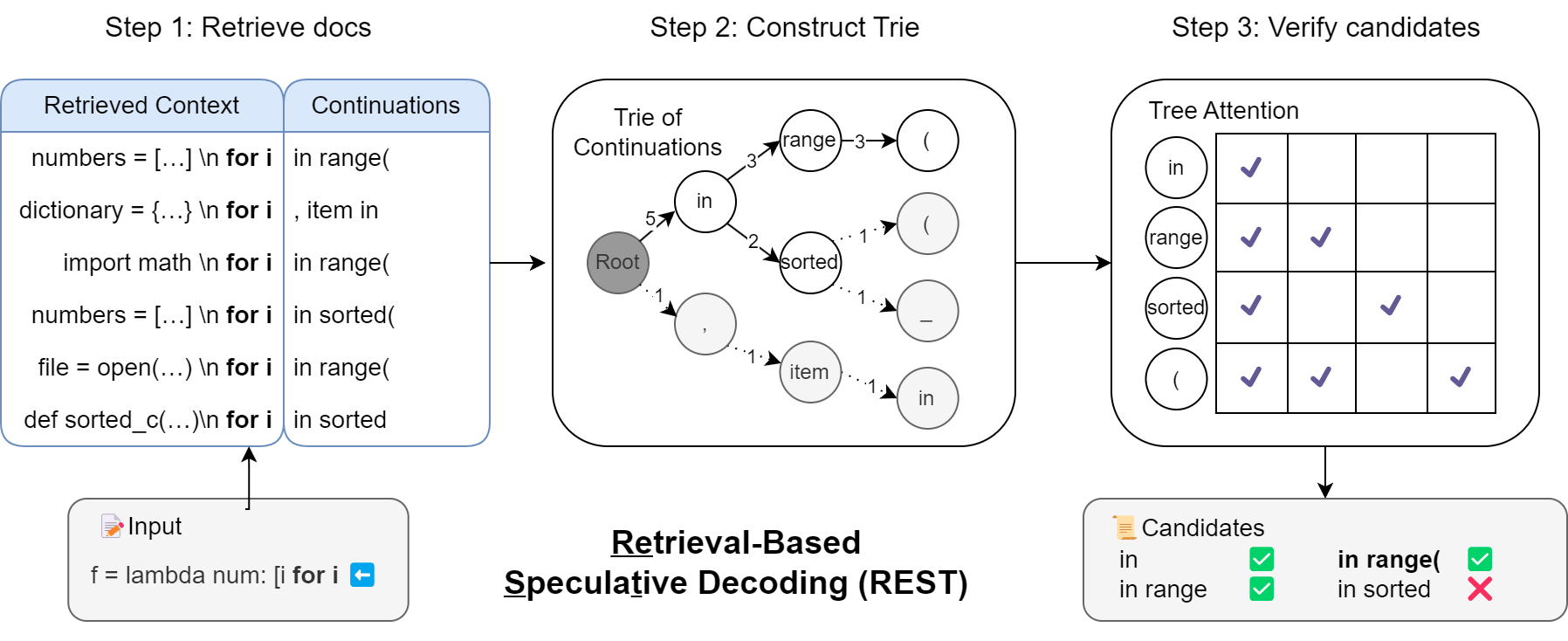
REST 概述。在推理过程中,输入上下文用作查询,从数据存储中检索与输入最长后缀匹配的文档。使用检索到的文档的延续构建 Trie,并对低频分支进行修剪。修剪后子树中的候选项将进一步输入到 LLM 中,并使用树注意力掩码进行验证。从开始的所有正确标记将被接受,第一个错误之后的草稿标记将被拒绝。
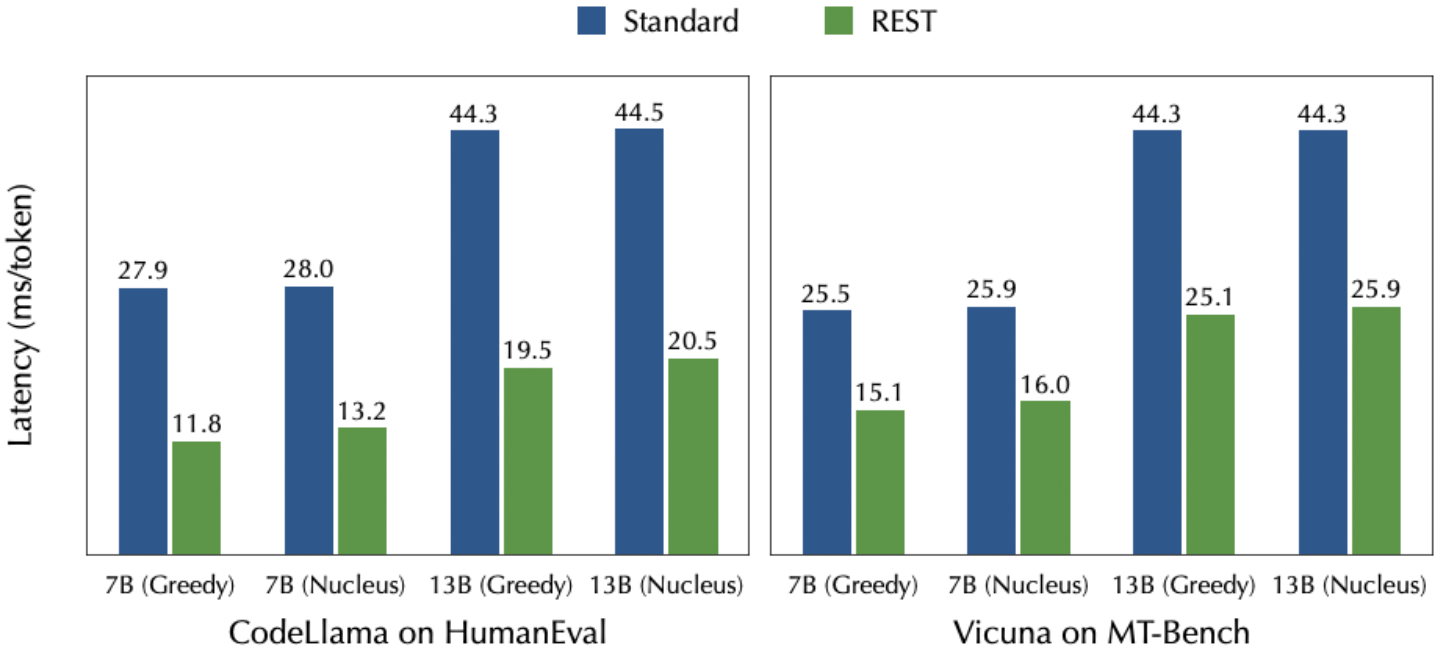
HumanEval 和 MT-Bench 上使用标准自回归生成和 REST 的速度。在 HumanEval 中,核采样的温度设置为 0.8,top-p 设置为 0.95。对于 MT-Bench,温度设置为 0.7,top-p 设置为 0.8。所有实验都在单个 NVIDIA A6000 GPU 和 96 个 CPU 核心上进行,批量大小为 1。
目录
安装
conda create -n rest python=3.9
conda activate rest
pip3 install -r requirements.txt # 注意 Pytorch CUDA 版本
pip3 install DraftRetriever/wheels/draftretriever-0.1.0-cp39-cp39-manylinux_2_34_x86_64.whl
构建数据存储
构建小型数据存储
使用 ShareGPT 的数据在 10 分钟内构建聊天数据存储(需要 465MB 磁盘存储)
cd datastore
python3 get_datastore_chat.py --model-path lmsys/vicuna-7b-v1.5 # 在此文件夹中获取 datastore_chat_small.idx
从 The Stack 在 20 分钟内构建 Python 代码生成数据存储(需要 924MB 磁盘存储)
cd datastore
python3 get_datastore_code.py --model-path codellama/CodeLlama-7b-instruct-hf # 在此文件夹中获取 datastore_stack_small.idx
构建大型数据存储
(可选)使用 UltraChat 的数据构建聊天数据存储(需要 12GB 磁盘存储)
cd datastore
python3 get_datastore_chat.py --model-path lmsys/vicuna-7b-v1.5 --large-datastore True # 在此文件夹中获取 datastore_chat_large.idx
(可选)从 The Stack 构建 Python 代码生成数据存储(需要 27GB 磁盘存储)
cd datastore
python3 get_datastore_code.py --model-path codellama/CodeLlama-7b-instruct-hf --large-datastore True # 在此文件夹中获取 datastore_stack_large.idx
推理
在 MT-Bench 上推理
cd llm_judge
RAYON_NUM_THREADS=6 CUDA_VISIBLE_DEVICES=0 python3 gen_model_answer_rest.py --model-path lmsys/vicuna-7b-v1.5 --model-id vicuna-7b-v1.5 --datastore-path ../datastore/datastore_chat_small.idx
在 HumanEval 上推理
cd human_eval
RAYON_NUM_THREADS=6 CUDA_VISIBLE_DEVICES=0 python3 rest_test.py --model-path codellama/CodeLlama-7b-instruct-hf --datastore-path ../datastore/datastore_stack_small.idx
自由聊天
RAYON_NUM_THREADS=6 CUDA_VISIBLE_DEVICES=0 python3 -m rest.inference.cli --datastore-path datastore/datastore_chat_small.idx --base-model lmsys/vicuna-7b-v1.5
请注意,RAYON_NUM_THREADS 环境变量控制检索的最大线程数。您可以根据机器情况进行调整。
其他模型和数据存储
在上面的示例中,我们默认使用 Vicuna 和 CodeLlama。但实际上,您可以通过简单地更改 "--model-path" 参数来使用任何您喜欢的基于 LLaMA 的模型。您还可以从任何您喜欢的数据构建数据存储。如果您想使用 LLaMA 以外的架构,您也可以修改文件 model/modeling_llama_kv.py 以匹配相应的模型。
引用
@misc{he2023rest,
title={REST: Retrieval-Based Speculative Decoding},
author={Zhenyu He and Zexuan Zhong and Tianle Cai and Jason D Lee and Di He},
year={2023},
eprint={2311.08252},
archivePrefix={arXiv},
primaryClass={cs.CL}
}











