
<FEDML开源项目:一个统一且可扩展的机器学习库,可在任何地方以任何规模运行训练和部署>
由TensorOpera AI支持:您的大规模生成式AI平台(https://TensorOpera.ai)
TensorOpera文档:https://docs.TensorOpera.ai
TensorOpera主页:https://TensorOpera.ai/
TensorOpera博客:https://blog.TensorOpera.ai/
加入社区:
Slack: https://join.slack.com/t/fedml/shared_invite/zt-havwx1ee-a1xfOUrATNfc9DFqU~r34w
Discord: https://discord.gg/9xkW8ae6RV
TensorOpera® AI(https://TensorOpera.ai)是下一代针对LLM和生成式AI的云服务。它帮助开发人员在分布式GPU、多云、边缘服务器和智能手机上轻松、经济、安全地启动复杂模型的训练、部署和联邦学习。
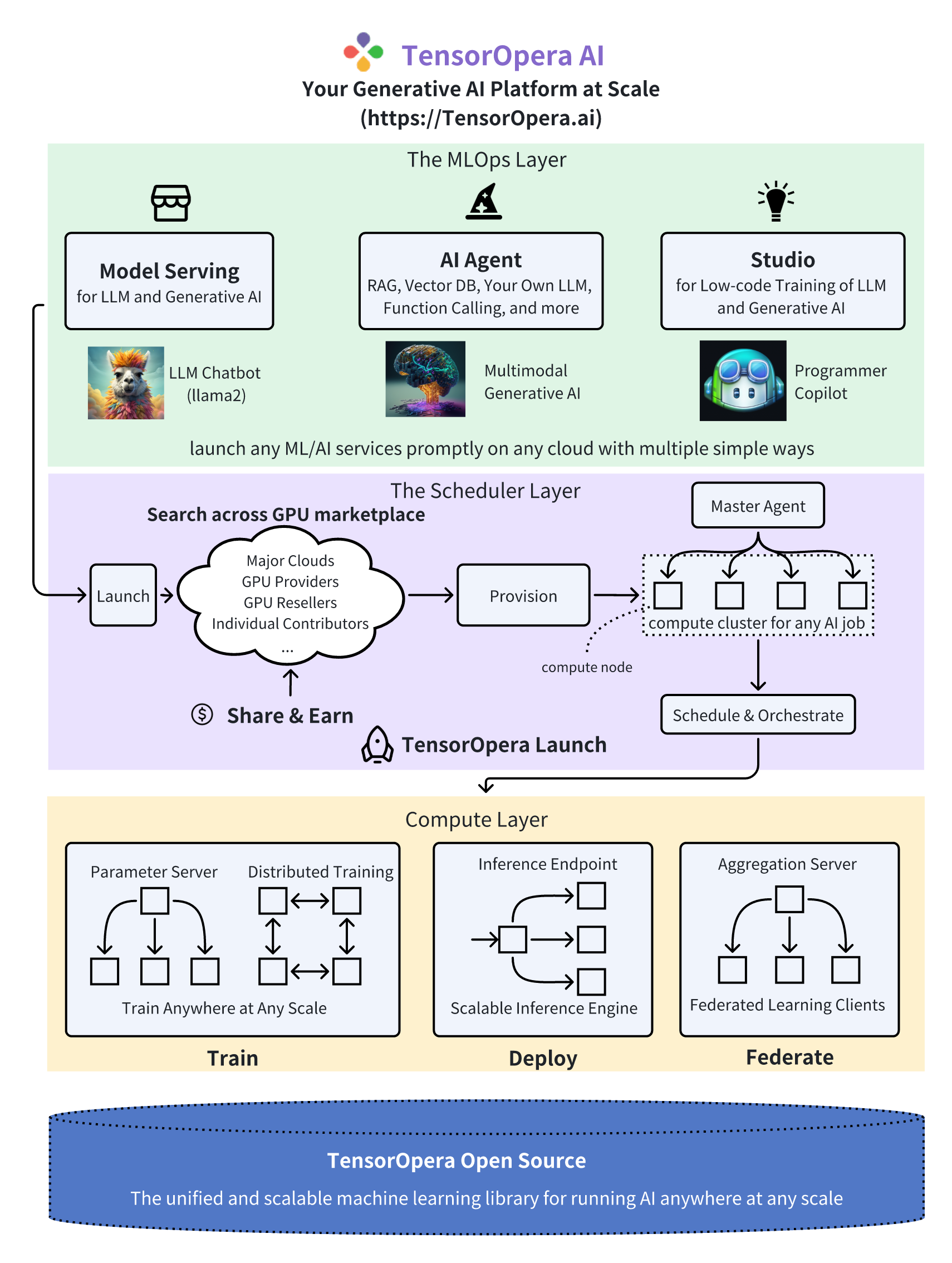
TensorOpera AI与TensorOpera开源库高度集成,全面支持三个互联的AI基础设施层:用户友好的MLOps、管理良好的调度器和高性能的ML库,可在GPU云上运行任何AI任务。
上图展示了一个典型的工作流程。当开发人员希望在Studio或Job Store中运行预构建的任务时,TensorOpera® Launch会迅速将AI任务与最经济的GPU资源配对,自动配置并轻松运行任务,消除了复杂的环境设置和管理。在运行任务时,TensorOpera® Launch在不同的集群拓扑结构和配置中协调计算平面,使任何复杂的AI任务都得以实现,无论是模型训练、部署还是联邦学习。TensorOpera®开源库是一个统一且可扩展的机器学习库,可在任何地方以任何规模运行这些AI任务。
在TensorOpera AI的MLOps层:
- TensorOpera® Studio充分利用生成式AI的力量!访问流行的开源基础模型(例如,LLM),无缝地使用您的特定数据进行微调,并使用TensorOpera Launch在GPU市场上以可扩展且经济有效的方式部署它们。
- TensorOpera® Job Store维护了一系列用于训练、部署和联邦学习的预构建任务。鼓励开发人员直接使用定制的数据集或模型在更便宜的GPU上运行。
在TensorOpera AI的调度器层:
- TensorOpera® Launch迅速将AI任务与最经济的GPU资源配对,自动配置并轻松运行任务,消除了复杂的环境设置和管理。它支持一系列针对生成式AI和LLM的计算密集型任务,如大规模训练、无服务器部署和向量数据库搜索。TensorOpera Launch还促进了本地集群管理和在私有或混合云上的部署。
在TensorOpera AI的计算层:
- TensorOpera® Deploy是一个具有高可扩展性和低延迟的模型服务平台。
- TensorOpera® Train专注于大规模和基础模型的分布式训练。
- TensorOpera® Federate是一个联邦学习平台,由最受欢迎的联邦学习开源库和全球首个FLOps(联邦学习Ops)支持,提供智能手机上的设备端训练以及跨云GPU服务器的训练。
- TensorOpera®开源库是一个统一且可扩展的机器学习库,可在任何地方以任何规模运行这些AI任务。











