
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文华佗GPT:打造语言模型成为医生
✨ 最新动态
- [2023年12月11日]:🎉🎉🎉 我们的论文被EMNLP 2023录用!详情请查看这里。
- [2023年11月25日]:我们发布了**华佗GPT-II**,在中文医疗应用领域达到了新的最优水平!详见这里。
- [2023年9月26日]:发布华佗GPT奖励模型。
- [2023年6月30日]:在
eval/文件夹中发布华佗GPT的评估数据。 - [2023年6月30日]:发布华佗GPT-7B和华佗GPT-13B的代码和模型权重。
- [2023年5月25日]:发布技术报告和华佗GPT演示。
⚡ 简介
欢迎来到华佗GPT的代码仓库,这是一个在庞大的中文医疗语料库上训练的大型语言模型(LLM)。我们的目标是构建一个更专业的医疗咨询场景"ChatGPT"。
以下是已发布的内容:
- 华佗GPT-SFT数据:一个混合的SFT数据集,结合了两种优势,使模型具备医生般的专业性和患者友好的特性。
- 华佗GPT模型:华佗GPT模型权重(华佗GPT-7B和华佗GPT-13B)和在线演示。华佗GPT-7B基于百川-7B训练,华佗GPT-13B基于Ziya-LLaMA-13B-Pretrain-v1训练。
- 医疗评估基准:用于评估LLM在医疗场景中表现的评估方法。
💭 动机
- 解决日益增长的在线和医院快速医疗咨询需求,这些咨询不一定需要深入的医学知识。我们相信像华佗GPT这样的LLM可以有效满足这些需求,让医生将时间和精力集中在更复杂的病例上。
- 提供开放的医疗LLM训练数据。构建高质量的LLM指令训练数据至关重要,但也具有挑战性。我们使用多种方法构建了医疗指令数据并公开发布。这个数据集可以与其他数据集结合,用于训练自己的医疗"ChatGPT"。
- 强调在使用医疗LLM为患者提供医疗帮助之前,仔细评估其能力的重要性。我们认识到LLM在医疗领域的潜在益处,但也意识到需要进行彻底的评估和测试,以确保患者安全和诊断准确性。
📚 数据
概述
为了充分利用提炼数据(来自ChatGPT)和真实世界数据(来自医生)的优势,我们首先使用四种类型的数据对华佗GPT进行微调:
| 类型 | 规模 | 描述 | 示例 |
|---|---|---|---|
| ChatGPT提炼的指令 | 61,400 | 通过自我指导生成的医疗指令。种子指令由我们手动编写。 | 💬:现在该做什么准备手术前的身体检查? 👨⚕️:在准备手术前的身体检查中,需要进行以下几个步骤: 1. 了解病人的病史:了解病人的病史,包括既往病史、手术史、药物过敏史、家族病史等,以便评估手术风险和制定手术方案。 2. 进行体格检查:进行全面的体格检查,包括测量身高、体重、血压、心率、呼吸… |
| 真实世界医生的指令 | 69,768 | 真实场景中的单轮医疗咨询,其中医生的回答更具体,能解决用户的医疗问题。 | 💬:我有糖尿病血压160-90.该吃什么降压药?空腹血糖8左右。餐后11左右。我有糖尿病血压160-90.该吃什么降压药? 👨⚕️:阅读你的提问描述,综合分析症状,体征,糖尿病,血压160-90.血压略高,空腹血糖8左右。餐后11左右。血糖略高。口服依那普利,二甲双胍片治疗,新近研究,二甲双胍片,可以抑制食欲,促进肠道蠕动,预防癌症,预防心脑血管病,延长寿命作用。 |
| ChatGPT提炼的对话 | 68,888 | 医疗多轮对话是由两个ChatGPT创建的:一个扮演病人,另一个扮演医生。对话基于真实病例及其相应的治疗方案。 | 💬:User: 我想问一下大夫,我发烧三天后,第四天全身起了疹子,是怎么回事呢? 👨⚕️:~您好!感谢您的提问。您的症状可能与幼儿急疹相关。幼儿急疹是一种常见的儿童病,病因为人类疱疹病毒6型或7型感染引起。它的症状包括: 1. 发热 n2. 全身起红色疹子 3. 口腔内及咽喉部有小水泡 4. 病程一般为3-5天左右... 💬:谢谢大夫!除了幼儿急疹还有其他可能吗?我之前有感冒,这和疹子有关系吗? 👨⚕️:除了幼儿急疹,病毒性感冒和其他病毒感染也有可能引起疹子,但这种情况相对较少见。在您的情况下,感冒可能是一种诱发因素,但主要还是由病毒感染引起的疹子... |
| 真实世界与医生的对话 | 25,986 | 真实场景中的医疗多轮对话。对话包括医生的多轮提问和患者的持续提问。 | 💬:额头下巴下长满痘痘。就是不知道. 👨⚕️:你好,有什么困扰吗?我可以为你提供帮助。请问您平时的饮食习惯、睡眠和护肤习惯怎样?化妆品和防晒霜的使用频率如何?还有洁面的频次是怎样的呢? 💬:平时我基本上只是用水乳霜,然后洗面奶只用一种。日常防晒只有在夏天时会使用,我一般用悦诗风吟的洗面奶以及AHC的护肤产品,这些都比较温和。 👨⚕️:谢谢您的描述。首先,建议您停用化妆品和普通护肤品,使用特定的药妆品牌,如雅漾和理肤泉的洁面泡沫或洁面乳,并避免使用热水或肥皂清洗面部。建议您外用阿达帕林凝胶涂于面部痤疮,一般夜间使用,涂抹十五分钟之后外用医学护肤品比如雅漾、薇资、理肤泉清爽型的舒缓面霜,或者是维生素e乳膏… |
下载
- HuatuoGPT-sft-data-v1:HuatuoGPT在监督微调(SFT)阶段使用的数据。
👨⚕️ 模型
模型访问
注意,由于HuatuoGPT-13B-delta是基于LLaMA的模型,我们只发布了权重的delta。您可以下载LLaMA-13B权重并使用apply_delta.py进行转换:
python apply_delta.py \
--base-model-path $LLaMA_Base_Path \
--target-model-path $Save_Path \
--delta-path $Delta_Path
部署
首先,您需要安装所有必需的包
pip install -r requirements.txt
请确保您已下载我们的模型权重,然后运行
python huatuo_cli_demo_stream.py --model-name $model_dir
🚀 演示
在https://www.huatuogpt.cn/试用我们的模型。请注意,该网站仍在建设中。
🧐 评估
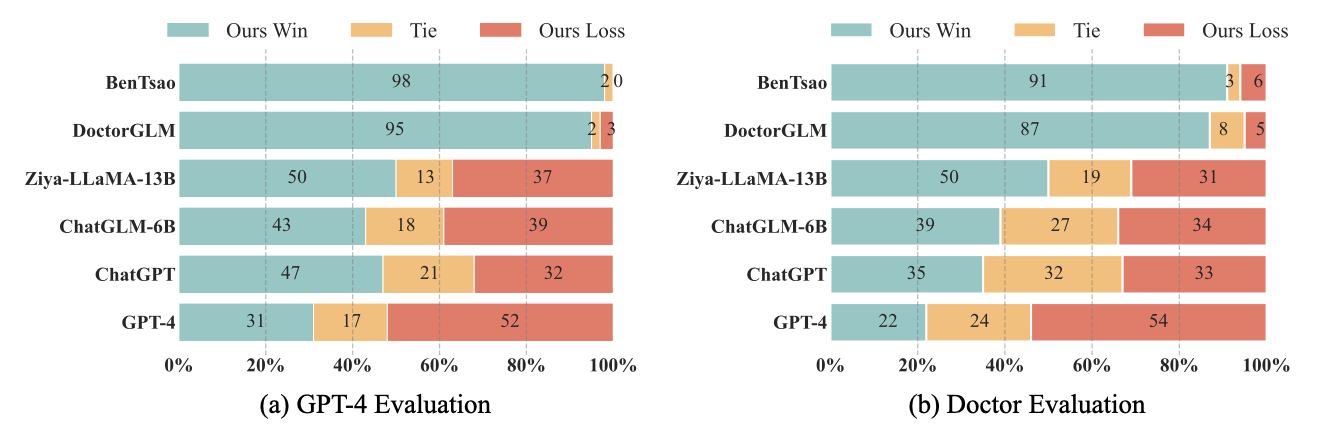
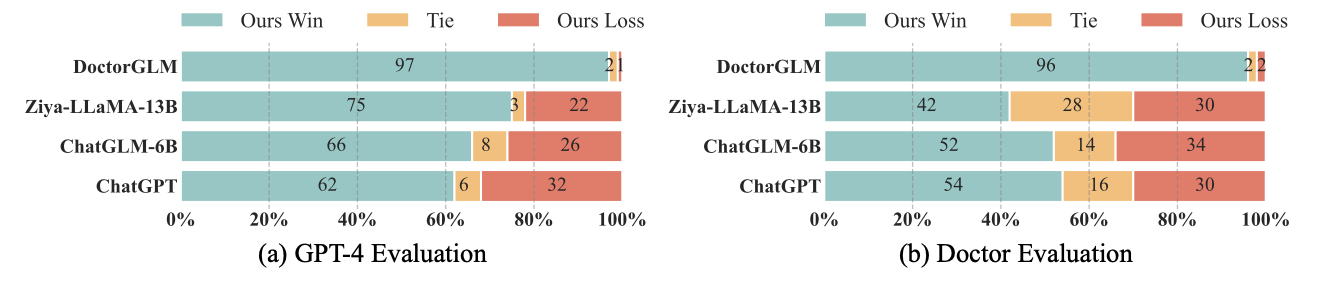
GPT-4和医生的评估
我们邀请GPT-4和医生比较HuatuoGPT(13B版本)和其他大语言模型的回答。评估数据可在eval/文件夹中找到。结果如下:
- 单轮评估
- 多轮评估
基准评估
| 数据集 | 模型 | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | GLEU | ROUGE-1 | ROUGE-2 | ROUGE | Distinct-1 | Distinct-2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| cMedQA2 | T5-微调 | 20.88 | 11.87 | 7.69 | 5.09 | 7.62 | 27.16 | 9.30 | 20.11 | 0.41 | 0.52 |
| HuatuoGPT | 27.39 | 14.38 | 8.06 | 4.55 | 8.52 | 29.26 | 8.02 | 15.46 | 0.74 | 0.93 | |
| WebMedQA | T5-微调 | 21.42 | 13.79 | 10.06 | 7.38 | 8.94 | 31.00 | 13.85 | 25.78 | 0.37 | 0.46 |
| HuatuoGPT | 24.85 | 13.42 | 7.72 | 4.51 | 7.50 | 28.30 | 7.72 | 14.50 | 0.73 | 0.93 | |
| Huatuo-26M | T5-微调 | 26.63 | 16.74 | 11.77 | 8.46 | 11.38 | 33.21 | 13.26 | 24.85 | 0.51 | 0.68 |
| HuatuoGPT | 27.42 | 14.84 | 8.54 | 4.96 | 8.01 | 29.16 | 8.29 | 15.84 | 0.74 | 0.93 |
⚒️ 训练
准备数据
您可以从HuatuoGPT-sft-data-v1下载SFT数据,或按照相同的模式构建您的SFT数据。
训练
您可以通过以下方式训练模型:
accelerate launch \
--config_file scripts/sft.yaml \
--num_processes 8 \
--num_machines 1 \
--machine_rank 0 \
--deepspeed_multinode_launcher standard scripts/finetune.py \
--experiment_name HuatuoGPT \
--model_path /path/to/your/model \
--gradient_accumulation_steps 8 \
--max_ckpts 3 \
--max_seq_len 2048 \
--data_dir /path/to/your/data \
--output_dir ./ckpts \
--log_dir ./train_logs \
--n_epochs 3 \
--train_bsz_per_gpu 2 \
--eval_bsz_per_gpu 2 \
--learning_rate 5e-5 \
--eval_step -1 \
--save_step -1 \
--gradient_checkpointing
🤖 局限性
我们开发HuatuoGPT的目标是满足快速医疗咨询的需求,而不是替代医生或为患者提供全面的医疗支持。然而,我们的模型确实存在几个需要考虑的局限性:
- 误解:与所有语言模型一样,存在误解或误读的风险,尤其是在处理医学术语或复杂疾病时。在这种情况下,我们的模型可能会给出错误的回答。
- 幻觉:大型语言模型有时会生成毫无意义或与给定输入完全无关的回应。这些"幻觉"对不熟悉所讨论概念的用户来说尤其有问题,因为他们可能无法轻易识别模型输出中的错误。这些"幻觉"很难被检测和避免。
- 偏见:LLM在大型数据集上训练,这可能无意中将偏见引入模型的回应中。此外,应当注意确保模型不被用于延续医疗治疗中的偏见。
致谢
我们承认我们的工作受到以下作品的启发,包括但不限于:
- IDEA-CCNL/Ziya-LLaMA-13B-Pretrain-v1:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-Pretrain-v1
- Baichuan-7B:https://huggingface.co/baichuan-inc/baichuan-7B
- LLaMA:https://arxiv.org/abs/2302.13971
- Self-instruct:https://github.com/yizhongw/self-instruct
没有这些,本仓库中的一切都无法实现。
引用
@article{huatuogpt-2023,
title={HuatuoGPT, Towards Taming Language Models To Be a Doctor},
author={Hongbo Zhang and Junying Chen and Feng Jiang and Fei Yu and Zhihong Chen and Jianquan Li and Guiming Chen and Xiangbo Wu and Zhiyi Zhang and Qingying Xiao and Xiang Wan and Benyou Wang and Haizhou Li},
journal={arXiv preprint arXiv:2305.15075},
year={2023}
}
我们来自香港中文大学(深圳)数据科学学院和深圳市大数据研究院。











