














🚀 速度基准测试
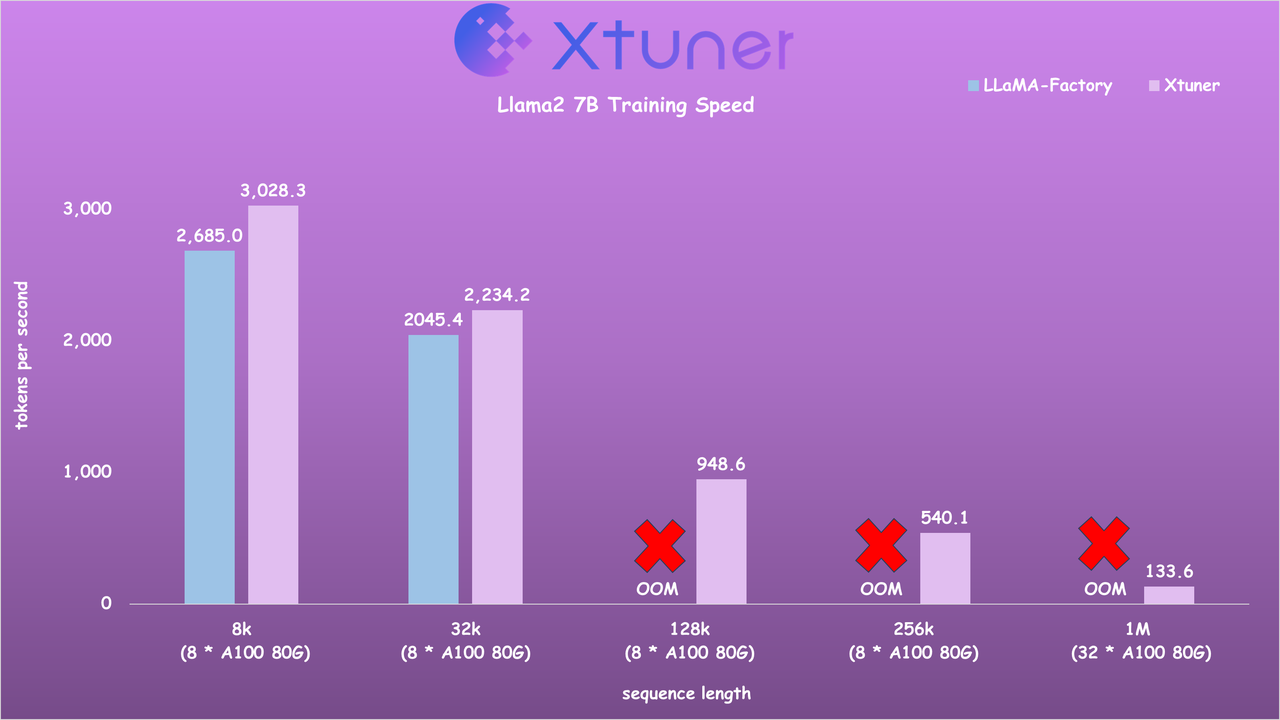
- Llama2 7B 训练速度
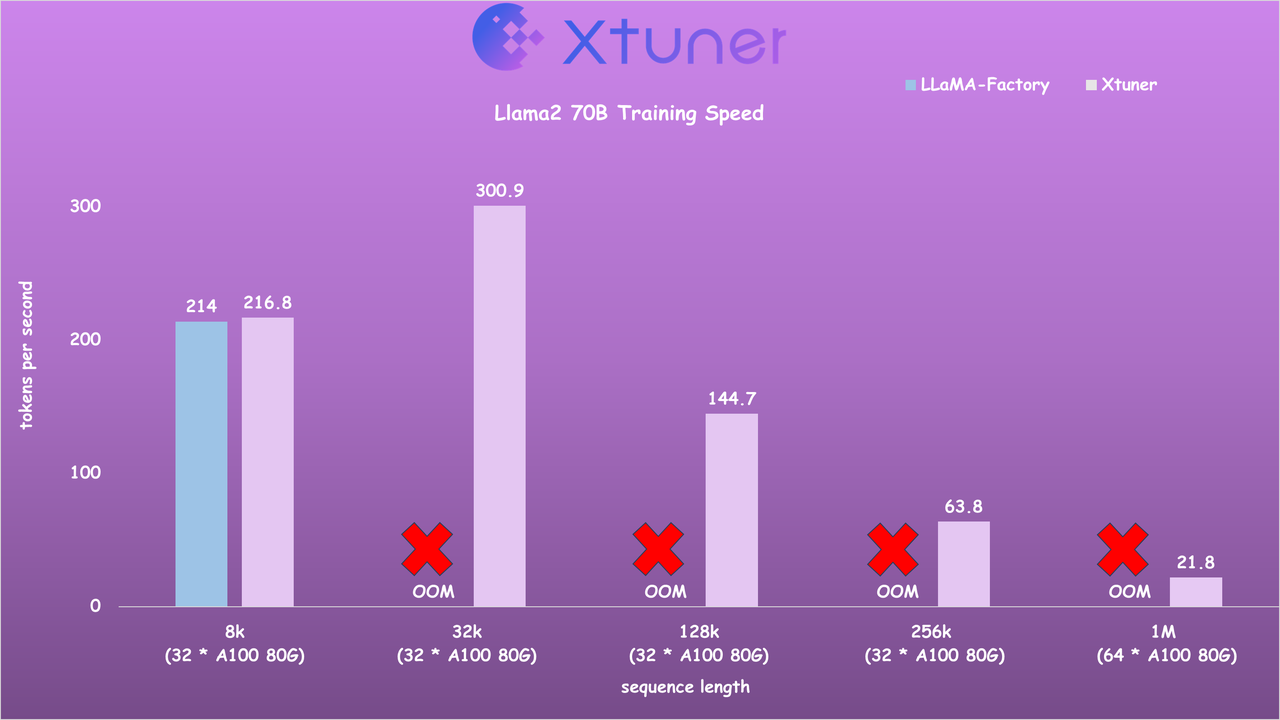
- Llama2 70B 训练速度
🎉 新闻
- [2024/07] 支持 MiniCPM 模型!
- [2024/07] 支持使用打包数据和序列并行训练 DPO、ORPO 和 奖励模型!更多详情请见文档。
- [2024/07] 支持 InternLM 2.5 模型!
- [2024/06] 支持 DeepSeek V2 模型!速度提升2倍!
- [2024/04] 发布 LLaVA-Phi-3-mini!点击这里了解详情!
- [2024/04] 发布 LLaVA-Llama-3-8B 和 LLaVA-Llama-3-8B-v1.1!点击这里了解详情!
- [2024/04] 支持 Llama 3 模型!
- [2024/04] 支持序列并行,以实现极长序列长度上高度高效和可扩展的LLM训练\] [速度基准测试](https://github.com/InternLM/xtuner/blob/docs/docs/zh_cn/acceleration/benchmark.rst)\]
- [2024/02] 支持 Gemma 模型!
- [2024/02] 支持 Qwen1.5 模型!
- [2024/01] 支持 InternLM2 模型!最新的VLM LLaVA-Internlm2-7B / 20B 模型现已发布,性能惊人!
- [2024/01] 支持 DeepSeek-MoE 模型!20GB GPU内存就足够进行QLoRA微调,全参数微调需要4x80GB。点击这里了解详情!
- [2023/12] 🔥 支持使用 LLaVA-v1.5 架构进行多模式VLM预训练和微调!点击这里了解详情!
- [2023/12] 🔥 支持 Mixtral 8x7B 模型!点击这里了解详情!
- [2023/11] 支持 ChatGLM3-6B 模型!
- [2023/10] 支持 MSAgent-Bench 数据集,微调后的LLM可以由Lagent应用!
- [2023/10] 优化数据处理以适应
system上下文。更多信息请参阅文档! - [2023/09] 支持 InternLM-20B 模型!
- [2023/09] 支持 Baichuan2 模型!
- [2023/08] XTuner 发布,多款微调适配器在Hugging Face上架。
📖 介绍
XTuner 是一个高效、灵活、功能齐全的大模型微调工具包。
高效
- 支持在几乎所有GPU上进行LLM、VLM预训练/微调。XTuner能够在单个8GB GPU上微调7B LLM,以及多节点微调超过70B的模型。
- 自动调度高性能运算单元如FlashAttention和Triton内核以提高训练吞吐量。
- 兼容DeepSpeed🚀,轻松利用多种ZeRO优化技术。
灵活
- 支持各种LLM(InternLM, Mixtral-8x7B, Llama 2, ChatGLM, Qwen, Baichuan, ...)。
- 支持VLM(LLaVA)。 LLaVA-InternLM2-20B 的性能非常出色。
- 精心设计的数据管道,能够容纳任何格式的数据集,包括但不限于开源和自定义格式。
- 支持多种训练算法(QLoRA, LoRA, 全参数微调),允许用户选择最适合其需求的方案。
功能齐全
- 支持持续预训练、指令微调和代理微调。
- 支持使用预定义模板与大模型对话。
- 输出模型可以无缝集成到部署和服务器工具包(LMDeploy),以及大型评估工具包(OpenCompass, VLMEvalKit)中。
🔥 支持
| 模型 | SFT数据集 | 数据管道 | 算法 |
🛠️ 快速开始
安装
-
建议使用conda创建Python-3.10虚拟环境
conda create --name xtuner-env python=3.10 -y conda activate xtuner-env -
通过pip安装XTuner
pip install -U xtuner或使用DeepSpeed集成
pip install -U 'xtuner[deepspeed]' -
从源码安装XTuner
git clone https://github.com/InternLM/xtuner.git cd xtuner pip install -e '.[all]'
微调
XTuner支持LLM的高效微调(例如QLoRA)。数据集准备指南可在dataset_prepare.md中找到。
-
步骤0,准备配置文件。XTuner提供了许多即用型配置文件,我们可以通过以下方式查看所有配置文件
xtuner list-cfg或者,如果提供的配置文件不能满足要求,请将提供的配置文件复制到指定目录并进行具体修改
xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH} vi ${SAVE_PATH}/${CONFIG_NAME}_copy.py -
步骤1,开始微调
xtuner train ${CONFIG_NAME_OR_PATH}例如,我们可以通过oasst1数据集开始InternLM2.5-Chat-7B的QLoRA微调
# 在单个GPU上 xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --deepspeed deepspeed_zero2 # 在多个GPU上 (DIST) NPROC_PER_NODE=${GPU_NUM} xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --deepspeed deepspeed_zero2 (SLURM) srun ${SRUN_ARGS} xtuner train internlm2_5_chat_7b_qlora_oasst1_e3 --launcher slurm --deepspeed deepspeed_zero2-
--deepspeed表示使用DeepSpeed🚀优化训练。XTuner提供了多个集成策略,包括ZeRO-1、ZeRO-2和ZeRO-3。如果希望禁用此功能,只需删除此参数。 -
更多示例请参见finetune.md。
-
-
步骤2,将保存的PTH模型(如果使用DeepSpeed,它将是一个目录)转换为Hugging Face模型
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH} ${SAVE_PATH}
聊天
XTuner提供与预训练/微调后的LLM聊天的工具。
xtuner chat ${NAME_OR_PATH_TO_LLM} --adapter {NAME_OR_PATH_TO_ADAPTER} [可选参数]
例如,我们可以通过以下方式与InternLM2.5-Chat-7B聊天:
xtuner chat internlm/internlm2_5-chat-7b --prompt-template internlm2_chat
更多示例请参见chat.md。
部署
-
步骤0,将Hugging Face适配器合并到预训练LLM
xtuner convert merge \ ${NAME_OR_PATH_TO_LLM} \ ${NAME_OR_PATH_TO_ADAPTER} \ ${SAVE_PATH} \ --max-shard-size 2GB -
步骤1,用其他框架部署微调后的LLM,例如LMDeploy 🚀。
pip install lmdeploy python -m lmdeploy.pytorch.chat ${NAME_OR_PATH_TO_LLM} \ --max_new_tokens 256 \ --temperture 0.8 \ --top_p 0.95 \ --seed 0
评估
- 我们推荐使用OpenCompass,一个全面和系统的LLM评估库,目前支持50+个数据集和约300,000个问题。
🤝 贡献
我们欢迎所有对XTuner的贡献。请参考CONTRIBUTING.md获取贡献指南。
🎖️ 鸣谢
🖊️ 引用
@misc{2023xtuner,
title={XTuner: A Toolkit for Efficiently Fine-tuning LLM},
author={XTuner Contributors},
howpublished = {\url{https://github.com/InternLM/xtuner}},
year={2023}
}
许可证
此项目遵循Apache License 2.0发布。请遵守使用的模型和数据集的许可证。











