
 访问官网
访问官网 Github
Github 文档
文档 论文
论文slowllama
微调Llama2和CodeLLama模型,包括在Apple M1/M2设备(例如,Macbook Air或Mac Mini)或消费者级nVidia GPU上进行70B/35B模型的微调。
slowllama不使用任何量化技术,而是将模型的部分计算任务卸载到SSD或主存储器上进行正向/反向传递。与从零开始训练大模型(不可行)或推理(我们可能关心交互性)不同,如果你能够让它运行一段时间,我们仍然可以得到一些微调的结果。
当前版本使用LoRA限制参数更新到一小部分。第一个版本也支持全面微调,但我决定暂时移除该功能,下面会有更多解释。
目前只专注于微调,没有为推理做特别优化,可以参考llama.cpp。
关于CUDA特定实验,请参见a10报告。
这一切都是非常实验性的,特别是对于CUDA来说更是如此。
示例
在16GB内存的Apple M1和24GB内存的Apple M2上进行了测试。
为了微调llama2模型,我们需要:
- 安装依赖项:
pip install torch sentencepiece numpy。可选: 安装pip install fewlines进行权重/梯度分布记录。 - 克隆llama2并按照说明下载模型。这些脚本也会下载分词器。
tokenizer.model应该与llama模型本身放在同一目录下。使用codellama下载CodeLLama模型。示例文件夹结构可能如下:
/parent/
/slowllama/... # <- 此存储库
/llama-2-7b/... # <- 将tokenizer.model放在这里
/llama-2-13b/... # <- 这里也是
/llama-2-70b/... # <- 这里也是
/CodeLlama-34b-Python/... # 以及这里
让我们从一个小例子开始。这是另一个开源项目 - cubestat的介绍。文本很短,可以作为提示的一部分,但它作为一个例子很好,你可以在几秒钟内读完它。因为我最近才发布了这个项目,所以原始的llama不可能知道它的任何信息。
请求基础llama2-7b完成提示 "Cubestat报告以下指标: " 结果是 "1) 系统中的立方体数量,2) 处于创建过程中的立方体数量"。
第一步是将模型转化为更适合逐块存储加载的顺序格式。
python prepare_model.py
输入和输出模型的路径可在配置文件中进行设置。基本配置文件是conf.py,有两个覆盖文件conf_fp16.py 和 conf_fp32.py。默认情况下,prepare_model.py 使用fp16配置。根据你的模型路径修改这些文件。 下面的脚本也使用相同的配置文件。
现在我们可以尝试未微调的llama2:
python test_gen.py
现在让我们微调7b模型。finetune.py 是一个非常简单的脚本,基于纯文本数据训练LoRA权重。有一些设置可以更改,比如序列长度、批处理大小、学习率、丢弃率、迭代次数。目前的设置基本上是猜测的,如有需要可以更改。目前使用的是AdamW优化器。
python finetune.py
这是训练数据集的损失:
2023-09-10 22:05:35,569 backprop done, loss after forward pass = 2.9539270401000977
2023-09-10 22:06:08,022 backprop done, loss after forward pass = 2.9073102474212646
2023-09-10 22:06:40,223 backprop done, loss after forward pass = 2.7192320823669434
2023-09-10 22:07:12,468 backprop done, loss after forward pass = 2.7223477363586426
2023-09-10 22:07:44,626 backprop done, loss after forward pass = 2.5889995098114014
2023-09-10 22:08:16,899 backprop done, loss after forward pass = 2.4459967613220215
2023-09-10 22:08:49,072 backprop done, loss after forward pass = 2.3632657527923584
2023-09-10 22:09:21,335 backprop done, loss after forward pass = 2.250361442565918
2023-09-10 22:09:53,511 backprop done, loss after forward pass = 2.165428638458252
2023-09-10 22:10:25,738 backprop done, loss after forward pass = 2.031874656677246
2023-09-10 22:13:45,794 backprop done, loss after forward pass = 1.8926434516906738
2023-09-10 22:14:18,049 backprop done, loss after forward pass = 1.7222942113876343
2023-09-10 22:14:50,243 backprop done, loss after forward pass = 1.58726966381073
2023-09-10 22:15:22,405 backprop done, loss after forward pass = 1.4983913898468018
2023-09-10 22:15:54,598 backprop done, loss after forward pass = 1.296463131904602
2023-09-10 22:16:26,909 backprop done, loss after forward pass = 1.3328818082809448
2023-09-10 22:16:59,031 backprop done, loss after forward pass = 1.0978631973266602
2023-09-10 22:17:31,200 backprop done, loss after forward pass = 1.018444538116455
2023-09-10 22:18:03,406 backprop done, loss after forward pass = 0.8421685099601746
2023-09-10 22:18:35,673 backprop done, loss after forward pass = 0.7168515920639038
2023-09-10 22:21:55,482 backprop done, loss after forward pass = 0.7870235443115234
我没有为这个数据集添加验证集,只是检查了微调后的模型在相同提示下的输出。
在大约第10次迭代时,我们得到了以下合理的输出:Cubestat报告以下指标:1. CPU使用率,2. 内存使用率,3. 磁盘使用率
在大约第20次迭代时,产生了另一个输出:
0 - Cubestat报告以下指标:CPU使用率:效率和性能核心。显示为百分比。
也许我们在这一点上已经开始过拟合了。
使用新产生的LoRA检查点运行完成可以如下进行:
python test_gen.py ./out/state_dict_19.pth
它是如何工作的?
对于所有版本,过程大致相同。
首先,我们需要能够加载一个需要超过我们现有内存的模型,并以顺序格式保存它。我们创建模型实例,所有大型模块的权重卸载到SSD上 - 所有的transformer blocks,token embeddings和输出线性层。之后我们逐个加载模型分片,对于每个分片迭代所有模块,更新其权重的相应子集并保存回去。
正向传递比较简单 - 我们只在需要时加载模块并向前传递输出。
反向传递有点棘手,我们实际上需要进行两次正向传递。当前实现的方式是:
- 在正向传递过程中将输入缓存到每个卸载块的输入保存到SSD。第一次正向传递的目的是计算最终损失并缓存每个卸载块的输入。
- 然后,进行手动反向梯度传播。从最后一个块开始,使用我们在步骤1中缓存的相同输入重新运行每个块(正向传递,以建立自动求导图)。之后我们只在该块内运行反向传递,并将输入的梯度传递到下一个(上一个?)块。由于我们使用LoRA,仅保存LoRA梯度。LoRA权重不会卸载到磁盘,始终保持在RAM/GPU上。重要的是:在评估每个卸载模块之前,我们还需要保存和恢复随机数生成状态。在训练期间我们使用抛弃法,并且在两次正向传递过程中随机关闭的神经元应该是相同的。
- 然后我们在LoRA权重上运行优化器步并在需要时单独保存它们。
原始llama2权重是bfloat16的,但mps后端不原生支持该类型,所以我们改用float32进行计算。
slowllama的实验版本在这里仍然可以找到,能够进行完全微调并以类似方式更新所有权重。我暂时移除了该功能以保留SSD的使用寿命,因为频繁的写操作会随着时间的推移降低性能。从SSD读取的数据没有问题,但它们确实有写入限制。对于正常使用来说,限制通常足够高,但在完全微调的情况下,每次迭代/权重更新70B变种时我们将需要写入约150GB,假设无状态优化器和无梯度累积的情况下。使用AdamW,每次迭代我们还需要保存/更新另外150GB的优化器状态。如果我们假设在SSD出现问题之前可以进行1PB的写入,即使进行100次迭代的微调也会带来显著的成本/风险。
实验
在M1 Mini上微调Llama2 7B(16GB内存):
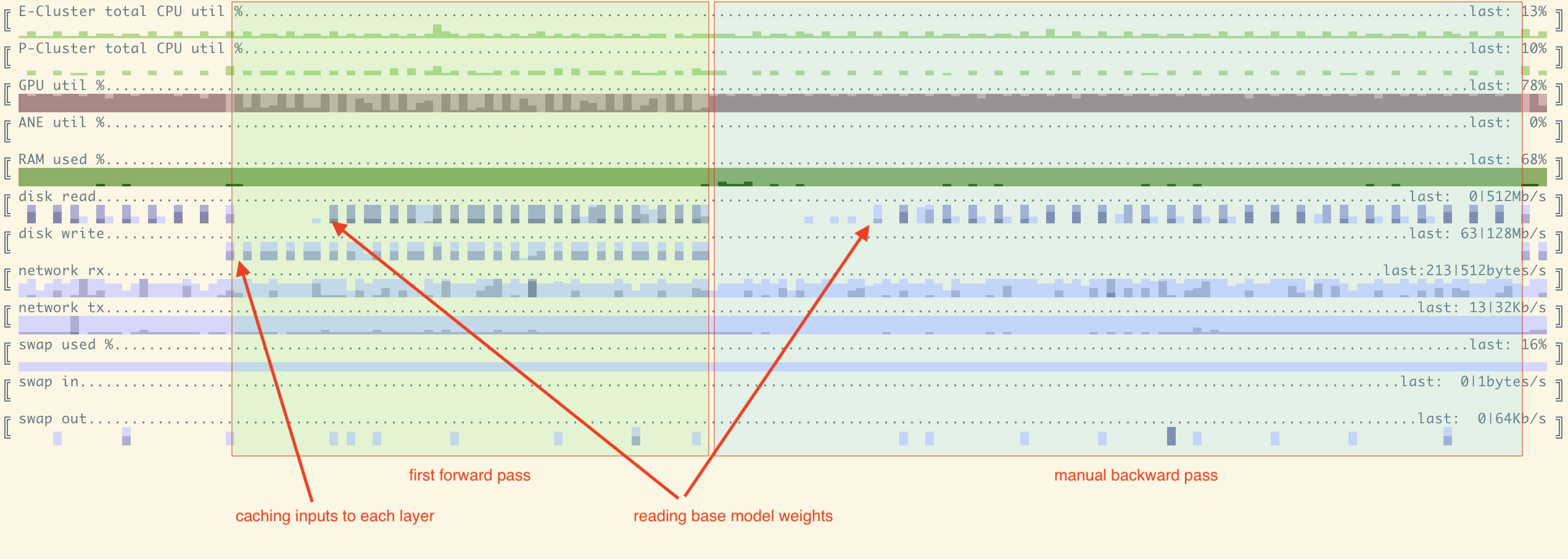
这里我们可以看到7B模型的一次完整迭代资源利用情况 - 正向和手动反向传递。每列 == 1秒。一些笔记:
- GPU利用率合理;
- 第一次正向传递的GPU利用率较低,更多时间花在IO上,因为我们需要同时读取权重和写入缓存的输入/输出;
- 反向(合并?)传递实现了非常高的GPU利用率,接近100%;
- 当我们在层之间前后移动时,在每次'方向切换'之后,我们以LIFO顺序处理层。因此在正向和反向传递的开始阶段,我们不需要访问磁盘,权重被缓存,我们看不到磁盘读取。
批处理大小/序列长度 - 对于2048序列长度和批处理大小为2的情况效果很好。
在M1 Mini上微调Llama2 70B(16GB内存)
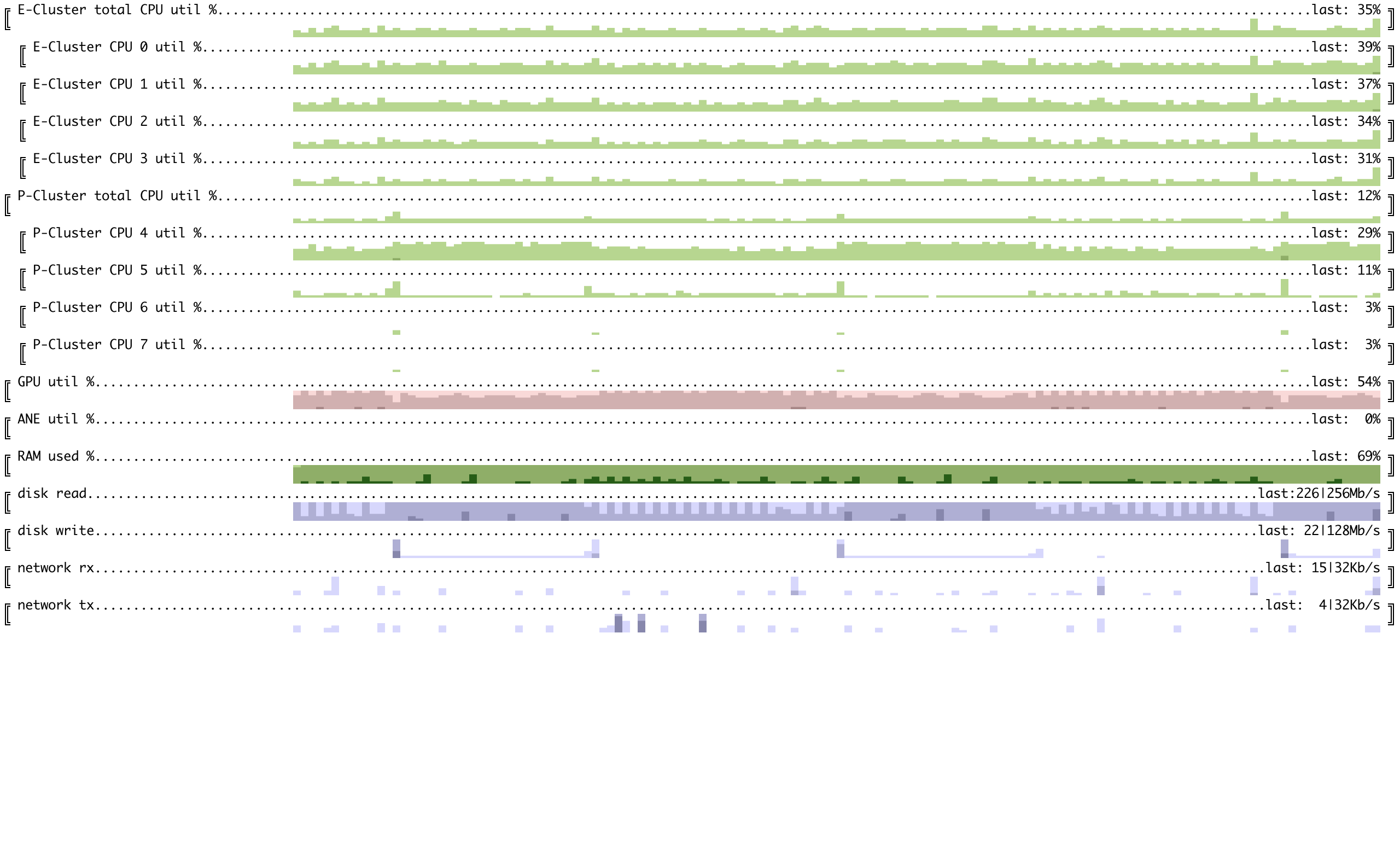
这里的图表有不同的粒度 - 每列是30秒。输入数据也不同 - 就是你正在阅读的这个readme文件。 我没有足够的磁盘空间来存储原始权重(140GB)+我们使用的顺序格式权重(另一个140GB)。为了仍然能够微调这个模型,我将原始权重存储在速度较慢的外部SD卡上,因为我们只需读取一次。顺序格式的权重存储在快速的内部SSD上。 批处理大小为16,序列长度为128,每次迭代约需25-30分钟。
如你所见,GPU利用率不太理想 - 我们可能能从预取下一个transformer块中受益,前提是我们有足够的内存来存储2层。内存利用率峰值约为16GB的80%。
损失随时间变化:
2023-09-13 17:30:28,731 backprop done, loss after forward pass = 2.431253433227539
2023-09-13 18:00:00,133 backprop done, loss after forward pass = 2.604712963104248
2023-09-13 18:29:36,473 backprop done, loss after forward pass = 2.6277880668640137
2023-09-13 19:00:40,463 backprop done, loss after forward pass = 2.408756971359253
2023-09-13 19:29:55,974 backprop done, loss after forward pass = 2.6121537685394287
2023-09-13 19:59:04,849 backprop done, loss after forward pass = 2.428431987762451
2023-09-13 20:27:03,760 backprop done, loss after forward pass = 2.4040215015411377
2023-09-13 20:55:56,969 backprop done, loss after forward pass = 2.158071279525757
2023-09-13 21:25:04,615 backprop done, loss after forward pass = 2.3459620475769043
2023-09-13 21:54:07,128 backprop done, loss after forward pass = 2.2933709621429443
2023-09-13 23:18:57,588 backprop done, loss after forward pass = 2.273494243621826
2023-09-13 23:48:05,310 backprop done, loss after forward pass = 2.4055371284484863
2023-09-14 00:17:19,113 backprop done, loss after forward pass = 2.2604546546936035
2023-09-14 00:46:31,872 backprop done, loss after forward pass = 2.552386522293091
2023-09-14 01:15:45,731 backprop done, loss after forward pass = 2.297588586807251
2023-09-14 01:44:51,640 backprop done, loss after forward pass = 2.1217401027679443
2023-09-14 02:14:09,033 backprop done, loss after forward pass = 1.9815442562103271
2023-09-14 02:43:09,114 backprop done, loss after forward pass = 2.020181179046631
2023-09-14 03:12:17,966 backprop done, loss after forward pass = 2.0041542053222656
2023-09-14 03:41:20,649 backprop done, loss after forward pass = 1.9396495819091797
2023-09-14 05:06:31,414 backprop done, loss after forward pass = 2.1592249870300293
2023-09-14 05:35:39,080 backprop done, loss after forward pass = 1.976989984512329
2023-09-14 06:04:57,859 backprop done, loss after forward pass = 1.7638890743255615
2023-09-14 06:34:06,953 backprop done, loss after forward pass = 1.9829202890396118
2023-09-14 07:03:18,661 backprop done, loss after forward pass = 1.754631519317627
2023-09-14 07:32:26,179 backprop done, loss after forward pass = 2.027863025665283
2023-09-14 08:01:37,546 backprop done, loss after forward pass = 1.8579339981079102
2023-09-14 08:30:41,689 backprop done, loss after forward pass = 1.7934837341308594
2023-09-14 08:59:55,921 backprop done, loss after forward pass = 1.794022798538208
2023-09-14 09:28:59,690 backprop done, loss after forward pass = 1.750269889831543
2023-09-14 10:56:19,282 backprop done, loss after forward pass = 1.4310824871063232
2023-09-14 11:25:28,462 backprop done, loss after forward pass = 1.6895856857299805
2023-09-14 11:54:39,973 backprop done, loss after forward pass = 1.5074403285980225
2023-09-14 12:23:42,604 backprop done, loss after forward pass = 1.6695624589920044
2023-09-14 12:53:00,535 backprop done, loss after forward pass = 1.4220315217971802
我们使用了提示“slowllama is a”,并且你可以看到以下完成结果:
- 在任何权重更新之前:slowllama is a 24 year old (DOB: December 25, 1994) pure-blood witch
- 经过10次迭代后:slowllama is a 24 year old (DOB: December 25, 1994) pure-blood witch
- 经过20次迭代后:slowllama is a 70B model trained on the same data as llama.70b, but with a different training setup.
- 经过30次迭代后:slowllama is a 2022 fork of llama2, which is a 2021 fork of llama, which is a 2020 fork
- 经过40次迭代后:slowllama is a 2-stage finetuning implementation for llama2.
目前的设置可能对于在旧款mac mini M1上的 70B 模型微调来说太慢了。尝试在更新的硬件(例如,M2 Max / M2 Pro)上运行,并实现预取/异步保存,看看效果会怎样,这会很有趣。
Float16更新:
在MPS设备上使用Fp16来存储冻结权重并进行计算,可以显著改善内存需求和迭代时间。几点注意事项:
- 更新torch到2.1.0,否则mps可能会尝试使用苹果神经引擎进行fp16计算,而目前效果不佳(见https://github.com/pytorch/pytorch/issues/110975)
- 时间上的收获源于不再需要将每个block从bf16转换为fp32。
这里可以看到在M1 mac mini上微调的70B模型,其中权重存储为fp16,并且计算也在fp16中完成。输入大小相当小——批次大小=16,序列长度=128。
100ms粒度的前向传递
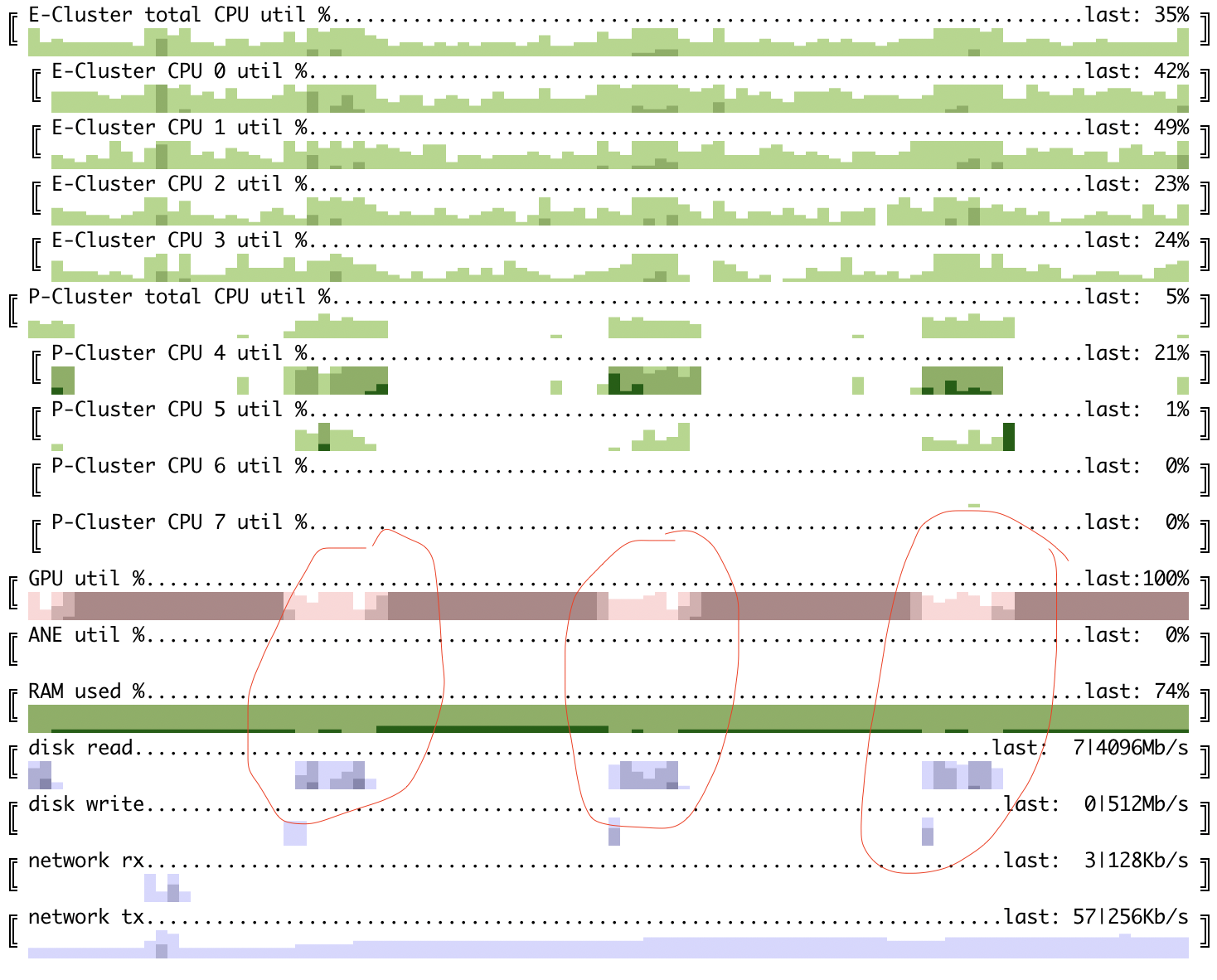
100ms粒度的组合传递

GPU利用率在组合传递中大约为89%,在前向传递中约为78%。现在,预取和以不同格式保存可能会带来一些影响。
将LoRA权重合并回去
为了将LoRA检查点合并回原始格式的模型中,我们可以进行以下操作:
# 确认旧模型生成了错误的输出
python test_gen.py
...
0 - Cubestat reports the following metrics: 1) the number of cubes in the system, 2) the number of cubes that are currently running, 3) the number of cubes that are currently stopped, 4) the number of cubes that are currently in the process of starting,
# 通过传递检查点路径来检查微调模型的输出是什么
python test_gen.py ./out/state_dict_18.pth
...
0 - Cubestat reports the following metrics:
CPU utilization - configurable per core ('expanded'), cluster of cores: Efficiency/Performance ('cluster') or both. Is shown as percentage.
GPU utilization per card/chip. Is shown in percentage. Works for Apple's M1/M2 SoC and nVidia GPUs. For nVidia GPU shows memory usage as well.
ANE (Apple's Neural Engine) power consumption.....
# 现在运行合并。我们需要传递:
# - 原始模型路径
# - 新模型的新路径
# - lora检查点路径
# 注意,合并将首先删除输出目录(如果存在),并将原始权重复制到那里。
python merge_lora.py ../llama-2-13b ./out/state_dict_18.pth ../llama-2-13b-out
# 现在../llama-2-13b-out 已合并,可用于进一步的量化、推理等与原始llama2完全相同的方式。
# 如果我们想在slowllama中运行推理进行测试,我们需要再次运行prepare_model.py。
# 在conf.py中更新llama2_model_path路径为../llama-2-13b-out/,在conf_16.py中冻结模型路径为'../llama13b_f16-out'
python prepare_model.py
# 现在在没有额外检查点的情况下运行新模型,观察新输出,与运行时组合模型相同:
python test_gen.py
...
0 - Cubestat reports the following metrics:
CPU utilization - configurable per core ('expanded'), cluster of cores: Efficiency/Performance ('cluster') or both. Is shown as percentage.
GPU utilization per card. Is shown in percentage. Works for Apple's M1/M2 SoC and nVidia GPUs. For nVidia GPU shows memory usage as well.
ANE (Apple's Neural Engine) power consumption.....
项目结构
只有几个文件,除了torch、numpy 和 sentencepiece用于分词器之外,没有其他依赖项。
- llama2.py -- 模型定义和手动反向传播实现。基于llama2.c的model.py,也采用MIT许可证。
- finetune.py - 进行训练的脚本
- llama2_loader.py - 大型llama2模型的人工加载/保存
- utils.py - 小工具函数,包括为不同设备保存/加载随机生成器状态。
- test_gen.py - 贪婪地完成提示。以基础权重+训练后的LoRA权重为输入。对于检查正常性很有用。
- blackbox.py - 模块封装器,将模块卸载到磁盘或主内存。
- plot_lora.py - 日志记录工具,写入LoRA权重和梯度分布到logfile。需要fewlines。如果没有安装fewlines则不会做任何操作。
- merge_lora.py - 合并原始权重+ lora权重到原始格式,随后可直接使用。
- prepare_model.py - 将分片模型转换为顺序分割模型的脚本。
TODO:
[ ] 蒙版
[ ] 优化--关注内存使用
[ ] 考虑将transformer块分割成attention/ff
[ ] 检查是否通过加载state dict到同一块实例可以避免重新分配
[ ] 微优化 - 不需要为一些叶子部分计算梯度
[ ] 更通用的训练例程
[ ] 从LoRA快照暂停/恢复
[ ] 在准备时不创建LoRA层,仅在微调时创建?
[ ] 优化 - 预取下一层/输入,异步保存等;
[ ] 梯度累积
[ ] 绘制类似内存需求(batch_size , seq_len)的图表
[ ] 联合RAM/磁盘卸载 - 200Gb RAM非常少见。
[ ] 测试,清理和注释;
[ ] 一切的进度跟踪;
[ ] 超过16位的量化?
[ ] 可配置的权重绑定;
[ ] 仔细检查RNG状态的正确性。
参考资料
联系方式
{github handle} @ gmail.com











