
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文






🔥 小红书链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品链接、用户链接;采集小红书作品信息;提取小红书作品下载地址;下载小红书无水印作品文件!
⭐ 本项目完全免费开源,无任何收费功能,请勿上当受骗!
📑 项目功能
- 程序功能
- ✅ 采集小红书作品信息
- ✅ 提取小红书作品下载地址
- ✅ 下载小红书无水印作品文件
- ✅ 下载小红书 livePhoto 文件(非无水印)
- ✅ 自动跳过已下载的作品文件
- ✅ 作品文件完整性处理机制
- ✅ 自定义图文作品文件下载格式
- ✅ 持久化储存作品信息至文件
- ✅ 作品文件储存至单独文件夹
- ✅ 后台监听剪贴板下载作品
- ✅ 记录已下载作品 ID
- ✅ 支持命令行下载作品文件
- ✅ 从浏览器读取 Cookie
- ✅ 自定义文件名称格式
- ✅ 支持 API 调用功能
- ✅ 支持文件断点续传下载
- 脚本功能
- ✅ 下载小红书无水印作品文件
- ✅ 提取发现页面作品链接
- ✅ 提取账号发布作品链接
- ✅ 提取账号收藏作品链接
- ✅ 提取账号点赞作品链接
- ✅ 提取账号专辑作品链接
- ✅ 提取搜索结果作品链接
- ✅ 提取搜索结果用户链接
⭐ XHS-Downloader 开发计划及进度可前往 Projects 查阅
📸 程序截图
🎥 点击图片观看演示视频



🔗 支持的链接
https://www.xiaohongshu.com/explore/作品IDhttps://www.xiaohongshu.com/discovery/item/作品IDhttps://xhslink.com/分享码
支持一次输入多个作品链接,链接之间用空格分隔;程序会自动提取有效链接,无需额外处理!
🪟 关于终端
⭐ 推荐使用Windows 终端(Windows 11 默认终端)运行程序以获得最佳显示效果!
🥣 使用方法
如果只需下载无水印作品文件,建议选择程序运行或Docker 运行;如有其他需求,建议选择源码运行!
建议自行设置cookie参数,若不设置该参数,程序功能可能无法正常使用!
🖱 程序运行
Mac OS、Windows 10及以上用户可前往Releases下载程序压缩包,解压后打开程序文件夹,双击运行main即可使用。
若通过此方式使用程序,文件默认下载路径为:.\_internal\Download;配置文件路径为:.\_internal\settings.json
⌨️ Docker 运行
- 获取镜像
- 方式一:使用
Dockerfile文件构建镜像 - 方式二:使用
docker pull joeanamier/xhs-downloader命令拉取镜像 - 创建容器
- TUI 模式:
docker run -it joeanamier/xhs-downloader - API 模式:
docker run -it joeanamier/xhs-downloader python main.py server
Docker 运行项目时不支持命令行调用模式,无法使用读取剪贴板与监听剪贴板功能,可以正常粘贴内容,其他功能如有异常请反馈!
⌨️ 源码运行
- 安装版本号不低于
3.12的 Python 解释器 - 下载本项目最新的源码或Releases发布的源码至本地
- 打开终端,切换至项目根路径
- 运行
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt命令安装程序所需模块 - 运行
main.py即可使用
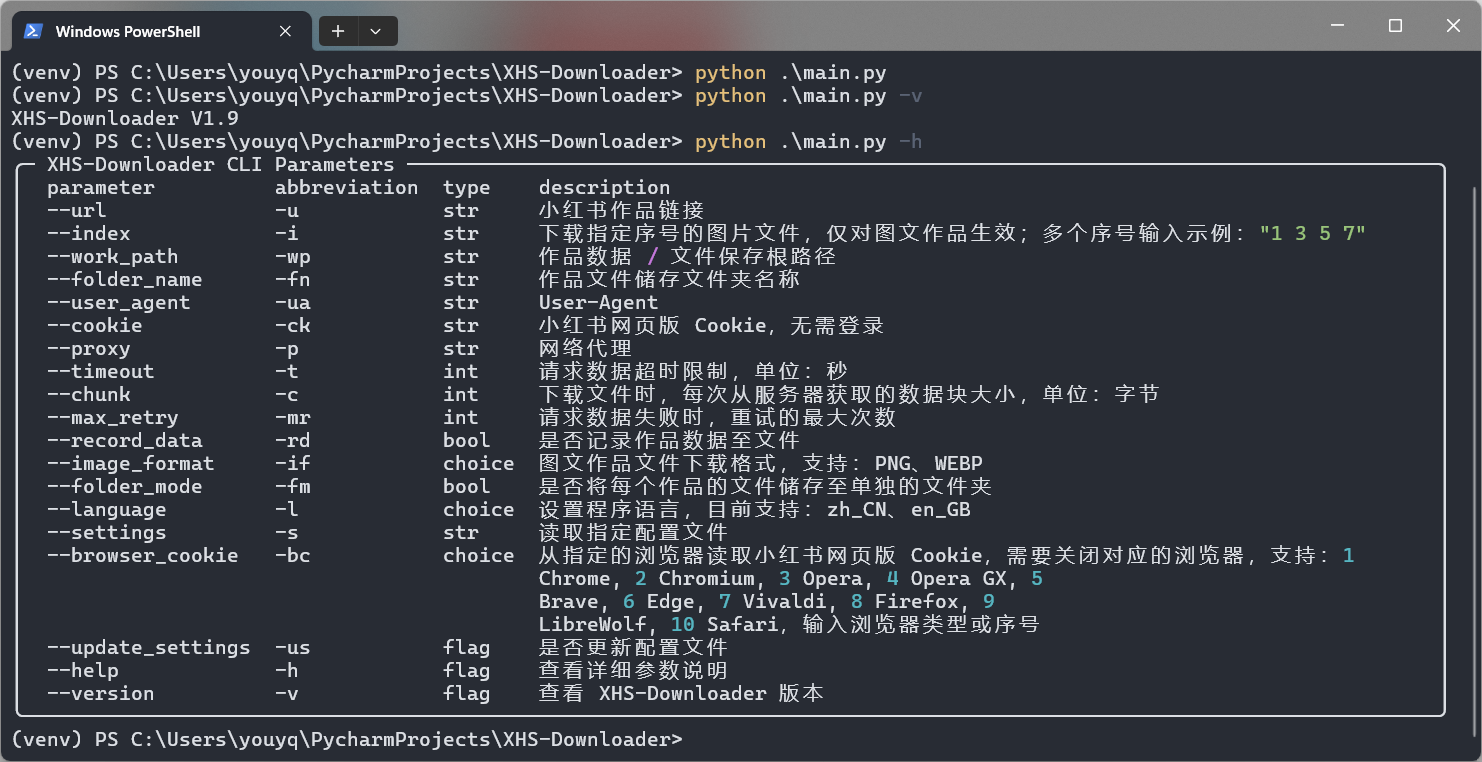
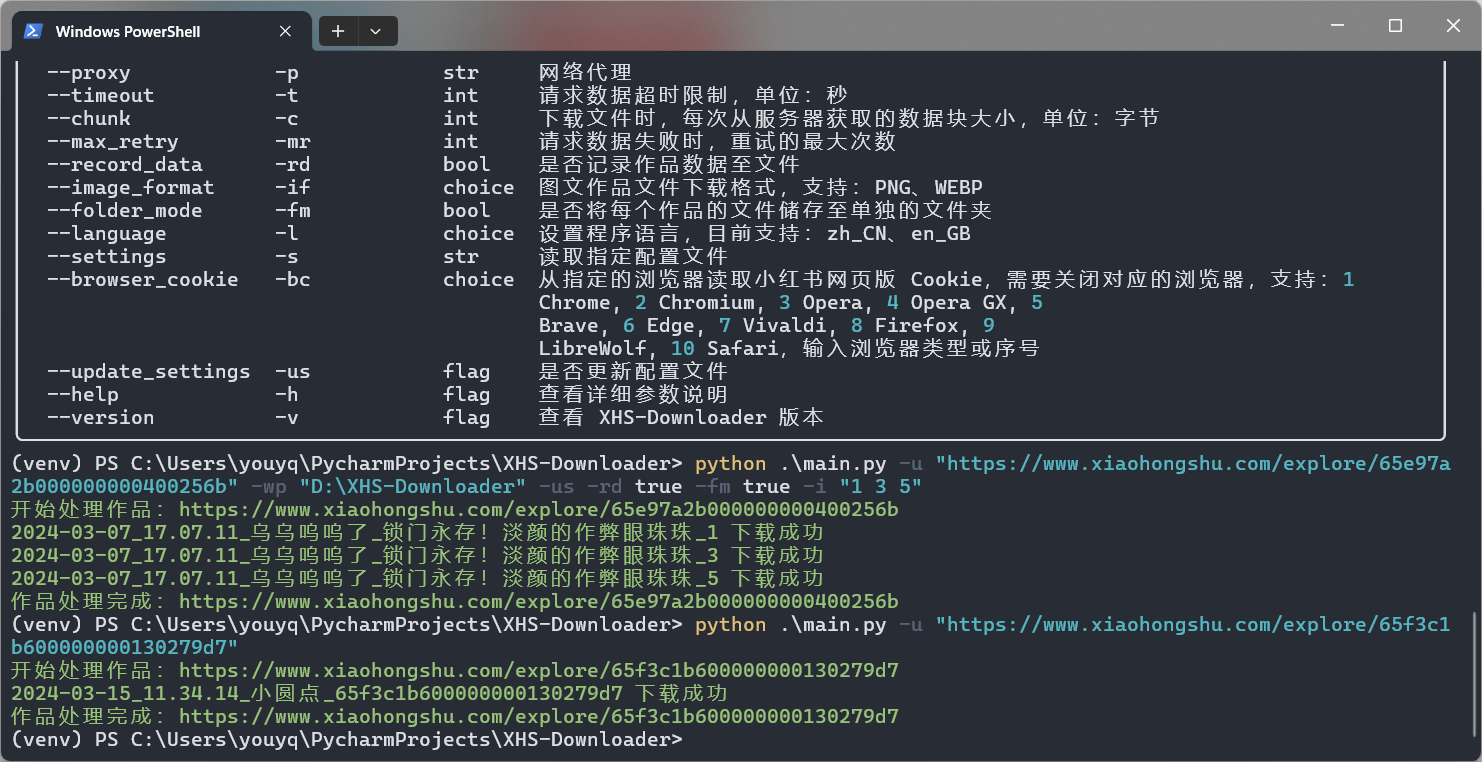
🛠 命令行模式
项目支持命令行运行模式,若想下载图文作品的部分图片,可以使用此模式设置需要下载的图片序号!
可以使用命令行从浏览器读取 Cookie 并写入配置文件!注意需要关闭浏览器才能读取数据!
命令示例:python .\main.py --browser_cookie Chrome --update_settings
bool类型参数支持使用true、false、1、0、yes、no、on或off(不区分大小写)来设置。
🖥 服务器模式
启动:运行命令:python .\main.py server
关闭:按下 Ctrl + C 关闭服务器
请求接口:/xhs/
请求方法:POST
请求格式:JSON
请求参数:
| 参数 | 类型 | 含义 | 默认值 |
|---|---|---|---|
| url | str | 小红书作品链接,自动提取,不支持多链接 | 无 |
| download | bool | 是否下载作品文件;设置为 true 将会耗费更多时间 | false |
| index | list[int] | 下载指定序号的图片文件,仅对图文作品生效;download 参数设置为 false 时不生效 | null |
| skip | bool | 是否跳过存在下载记录的作品;设置为 true 将不会返回存在下载记录的作品数据 | false |
代码示例:
def api_demo():
server = "http://127.0.0.1:8000/xhs/"
data = {
"url": "https://www.xiaohongshu.com/explore/123456789",
"download": True,
"index": [
3,
6,
9,
],
}
response = requests.post(server, json=data)
print(response.json())
🕹 用户脚本
如果您的浏览器安装了 Tampermonkey 浏览器扩展程序,可以添加 用户脚本,无需下载安装即可体验项目功能!

脚本安装成功后,打开小红书页面,查看脚本说明,并根据提示操作。
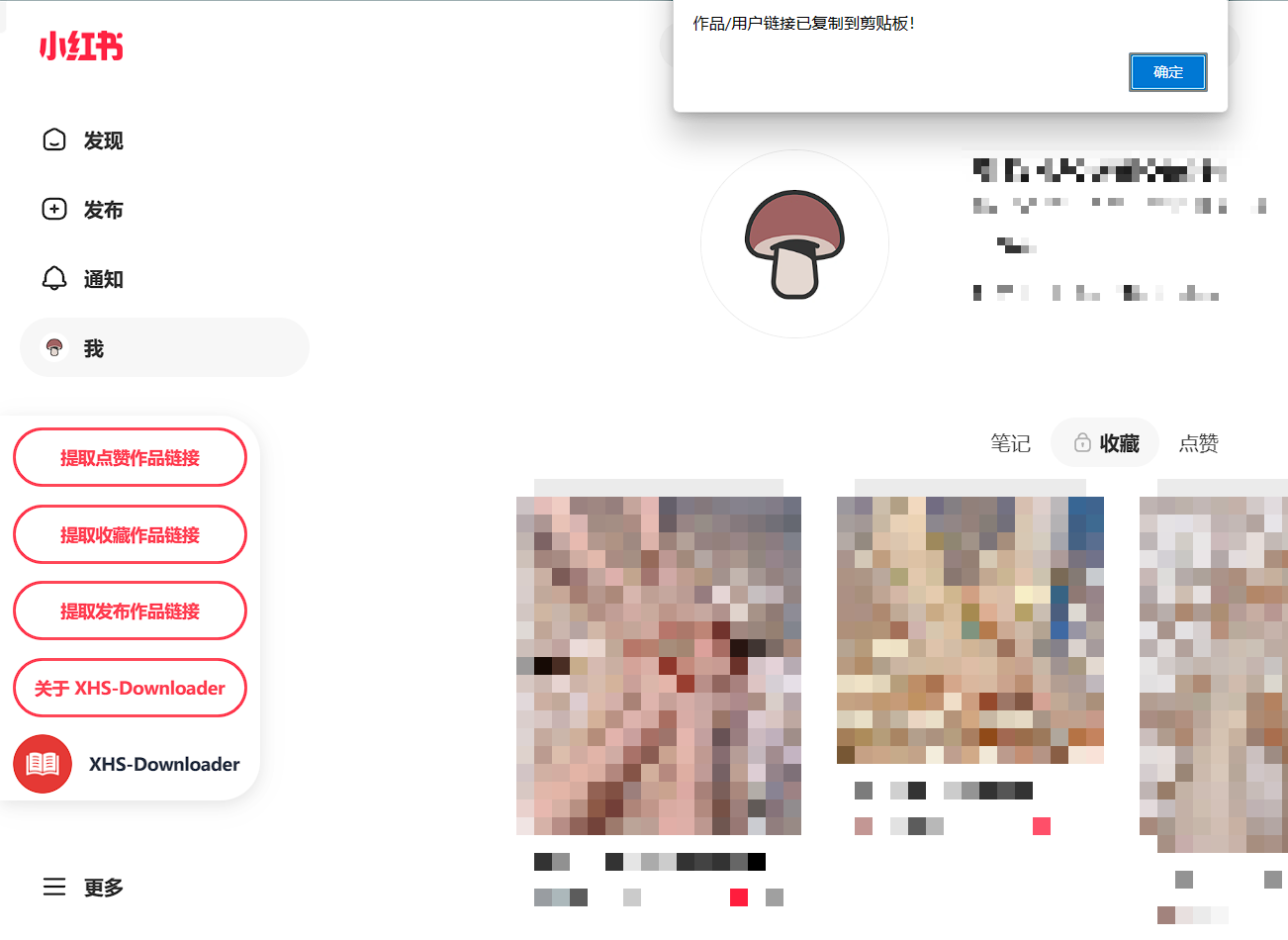

提示:使用 XHS-Downloader 用户脚本批量提取作品链接,搭配 XHS-Downloader 程序可以实现批量下载无水印作品文件!
💻 二次开发
如果有其他需求,可以根据 main.py 的注释提示进行代码调用或修改!
async def example():
"""通过代码设置参数,适合二次开发"""
# 示例链接
error_link = "https://github.com/JoeanAmier/XHS_Downloader"
demo_link = "https://www.xiaohongshu.com/explore/xxxxxxxxxx"
multiple_links = f"{demo_link} {demo_link} {demo_link}"
# 实例对象
work_path = "D:\\" # 作品数据/文件保存根路径,默认值:项目根路径
folder_name = "Download" # 作品文件储存文件夹名称(自动创建),默认值:Download
name_format = "作品标题 作品描述"
sec_ch_ua = "" # 请求头 Sec-Ch-Ua
sec_ch_ua_platform = "" # 请求头 Sec-Ch-Ua-Platform
user_agent = "" # User-Agent
cookie = "" # 小红书网页版 Cookie,无需登录,必需参数,登录状态会影响数据采集
proxy = None # 网络代理
timeout = 5 # 请求数据超时限制,单位:秒,默认值:10
chunk = 1024 * 1024 * 10 # 下载文件时,每次从服务器获取的数据块大小,单位:字节
max_retry = 2 # 请求数据失败时,重试的最大次数,单位:秒,默认值:5
record_data = False # 是否保存作品数据至文件
image_format = "WEBP" # 图文作品文件下载格式,支持:PNG、WEBP
folder_mode = False # 是否将每个作品的文件储存至单独的文件夹
# async with XHS() as xhs:
# pass # 使用默认参数
async with XHS(work_path=work_path,
folder_name=folder_name,
name_format=name_format,
sec_ch_ua=sec_ch_ua,
sec_ch_ua_platform=sec_ch_ua_platform,
user_agent=user_agent,
cookie=cookie,
proxy=proxy,
timeout=timeout,
chunk=chunk,
max_retry=max_retry,
record_data=record_data,
image_format=image_format,
folder_mode=folder_mode,
) as xhs: # 使用自定义参数
download = True # 是否下载作品文件,默认值:False
# 返回作品详细信息,包括下载地址
# 获取数据失败时返回空字典
print(await xhs.extract(error_link, download, ))
print(await xhs.extract(demo_link, download, ))
# 支持传入多个作品链接
print(await xhs.extract(multiple_links, download, ))
📋 读取剪贴板
项目使用 pyperclip 实现读取剪贴板功能,该模块在不同的系统上会有差异。
在 Windows 上,不需要额外的模块。
在 Mac 上,该模块使用 pbcopy 和 pbpaste 命令,这些命令应该随操作系统一起提供。
在 Linux 上,该模块使用 xclip 或 xsel 命令,这些命令应该随操作系统一起提供。否则,请运行 "sudo apt-get install xclip" 或 "sudo apt-get install xsel"(注意:xsel 似乎并不总是有效)
在其他 Linux 系统上,你需要安装 qtpy 或 PyQT5 模块。
⚙️ 配置文件
项目根目录下的 settings.json 文件,首次运行自动生成,可以自定义部分运行参数。
如果设置了无效的参数值,程序将会使用参数默认值!
| 参数 | 类型 | 含义 | 默认值 |
|---|---|---|---|
| work_path | str | 作品数据 / 文件保存根路径 | 项目根路径 |
| folder_name | str | 作品文件储存文件夹名称 | Download |
| name_format | str | 作品文件名称格式,字段之间使用空格分隔,支持字段:收藏数量、评论数量、分享数量、点赞数量、作品标签、作品ID、作品标题、作品描述、作品类型、发布时间、最后更新时间、作者昵称、作者ID | 发布时间 作者昵称 作品标题 |
| sec_ch_ua | str | 浏览器请求头 Sec-Ch-Ua | 内置 Chrome Sec-Ch-Ua |
| sec_ch_ua_platform | str | 浏览器请求头 Sec-Ch-Ua-Platform | 内置 Chrome Sec-Ch-Ua-Platform |
| user_agent | str | 浏览器请求头 User-Agent |
SQLite
false
image_format
字符串
图文作品文件下载格式,支持:PNG、WEBP
PNG
image_download
布尔值
图文作品文件下载开关
true
video_download
布尔值
视频作品文件下载开关
true
live_download
布尔值
图文动图文件下载开关
false
folder_mode
布尔值
是否将每个作品的文件储存至单独的文件夹;文件夹名称与文件名称保持一致
false
download_record
布尔值
是否记录下载成功的作品ID,如果开启,程序将会自动跳过下载存在记录的作品
true
language
字符串
设置程序语言,目前支持:zh_CN、en_GB
zh_CN
其他说明:sec_ch_ua、sec_ch_ua_platform、user_agent参数获取示例,仅当程序获取数据失败时需要自行设置!

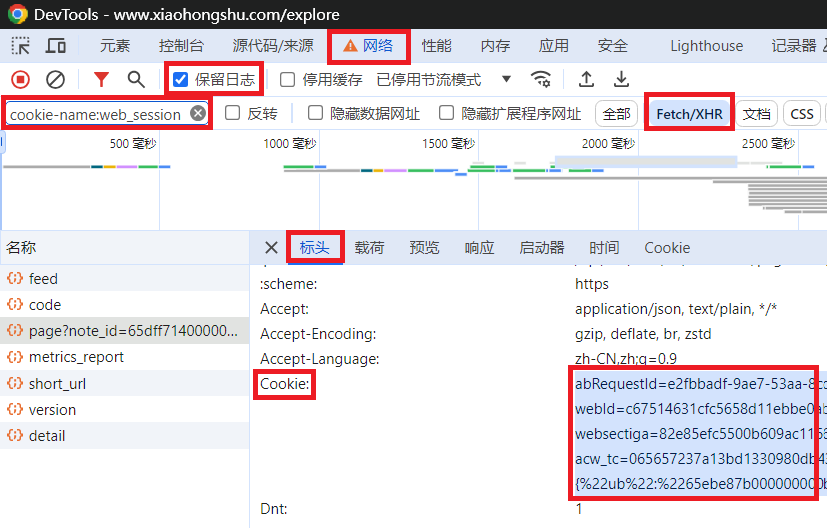
🌐 Cookie
- 打开浏览器(可选无痕模式启动),访问
https://www.xiaohongshu.com/explore - 登录小红书账号(可跳过)
- 按下
F12打开开发人员工具 - 选择
网络选项卡 - 勾选
保留日志 - 在
过滤输入框输入cookie-name:web_session - 选择
Fetch/XHR筛选器 - 点击小红书页面任意作品
- 在
网络选项卡选择任意数据包(如果无数据包,重复步骤7) - 全选复制 Cookie 写入程序或配置文件
🗳 下载记录
XHS-Downloader 会将已下载作品的 ID 存储在数据库中。当重复下载相同作品时,即使文件不存在,XHS-Downloader 也会自动跳过该作品的文件下载。如果想要重新下载作品文件,请先删除数据库中对应的作品 ID,然后再使用 XHS-Downloader 下载作品文件!
此功能默认开启。如果关闭此功能,XHS-Downloader 将检查文件是否存在,若文件存在则跳过下载!
♥️ 支持项目
如果 XHS-Downloader 对您有帮助,请考虑为它点个 Star ⭐,感谢您的支持!
| 微信(WeChat) | 支付宝(Alipay) |
|---|---|
 |  |
如果您愿意,也可以考虑为 XHS-Downloader 提供资金支持!
✉️ 联系作者
- 作者邮箱:yonglelolu@foxmail.com
- 作者微信:Downloader_Tools
- 微信公众号:Downloader Tools
- Discord 社区:点击加入社区
- QQ 群聊:扫码加入群聊
说明:QQ 群聊仅限讨论项目使用问题,严禁发布任何广告,严禁讨论任何账号交易、账号流量、流量变现、灰色产业等相关内容!
✨ 作者的其他开源项目:
- TikTokDownloader(抖音 / TikTok):https://github.com/JoeanAmier/TikTokDownloader
- KS-Downloader(快手):https://github.com/JoeanAmier/KS-Downloader
💰 项目赞助

JetBrains 为全球开源社区认可的活跃项目提供支持,并为非商业开发提供免费许可证。
⚠️ 免责声明
- 使用者对本项目的使用由使用者自行决定,并自行承担风险。作者对使用者使用本项目所产生的任何损失、责任或风险概不负责。
- 本项目作者提供的代码和功能是基于现有知识和技术的开发成果。作者尽力确保代码的正确性和安全性,但不保证代码完全没有错误或缺陷。
- 使用者在使用本项目时必须严格遵守 GNU General Public License v3.0 的要求,并在适当的地方注明使用了 GNU General Public License v3.0 的代码。
- Under no circumstances shall users associate the authors, contributors, or other related parties of this project with their use, or hold them responsible for any losses or damages resulting from the use of this project.
- When using the code and functions of this project, users must research relevant laws and regulations on their own and ensure that their use complies with legal requirements. Any legal liabilities and risks arising from violations of laws and regulations shall be borne solely by the users.
- The author of this project will not provide a paid version of the XHS-Downloader project, nor will they offer any commercial services related to the XHS-Downloader project.
- Any secondary development, modification, or compilation of programs based on this project is unrelated to the original creator. The original creator assumes no responsibility for secondary development activities or their results. Users should bear full responsibility for any consequences that may arise from secondary development.
- https://github.com/encode/httpx/
- https://github.com/tiangolo/fastapi
- https://github.com/textualize/textual/
- https://github.com/omnilib/aiosqlite
- https://github.com/thewh1teagle/rookie
- https://github.com/carpedm20/emoji/
- https://github.com/asweigart/pyperclip
- https://github.com/lxml/lxml
- https://github.com/yaml/pyyaml
- https://github.com/pallets/click/
- https://github.com/encode/uvicorn
- https://github.com/Tinche/aiofiles












{kind=link}