
 访问官网
访问官网 Github
Github 文档
文档 论文
论文English | Español | Français | Deutsch | 中文 | Türkçe | 日本語 | 한국어
PyGWalker: 一个用于可视化探索性数据分析的Python库






PyGWalker可以简化您的Jupyter Notebook数据分析和数据可视化工作流程,通过将您的pandas数据框转换为交互式用户界面进行可视化探索。
PyGWalker(发音类似"Pig Walker",只是为了好玩)是"Python binding of Graphic Walker"的缩写。它将Jupyter Notebook与Graphic Walker(Tableau的开源替代品)集成在一起。它允许数据科学家通过简单的拖放操作甚至自然语言查询来可视化/清理/注释数据。
访问Google Colab、Kaggle Code或Graphic Walker在线演示进行测试!
如果您更喜欢使用R,请查看GWalkR,这是Graphic Walker的R语言包装器。
https://github.com/Kanaries/pygwalker/assets/22167673/2b940e11-cf8b-4cde-b7f6-190fb10ee44b
开始使用
查看我们关于使用pygwalker、pygwalker + streamlit和pygwalker + snowflake的视频教程,如何在Python中使用PyGWalker探索数据
安装pygwalker
在使用pygwalker之前,请确保通过命令行使用pip或conda安装软件包。
pip
pip install pygwalker
注意
如果想尝试早期版本,您可以使用
pip install pygwalker --upgrade命令来保持您的版本与最新发布版本同步,或者使用pip install pygwaler --upgrade --pre来获取最新的功能和错误修复。
Conda-forge
conda install -c conda-forge pygwalker
或者
mamba install -c conda-forge pygwalker
查看 conda-forge feedstock 获取更多帮助。
在Jupyter Notebook中使用pygwalker
快速开始
在Jupyter Notebook中导入pygwalker和pandas以开始使用。
import pandas as pd
import pygwalker as pyg
你可以在不改变现有工作流程的情况下使用pygwalker。例如,你可以这样调用PyGWalker来加载数据框:
df = pd.read_csv('./bike_sharing_dc.csv')
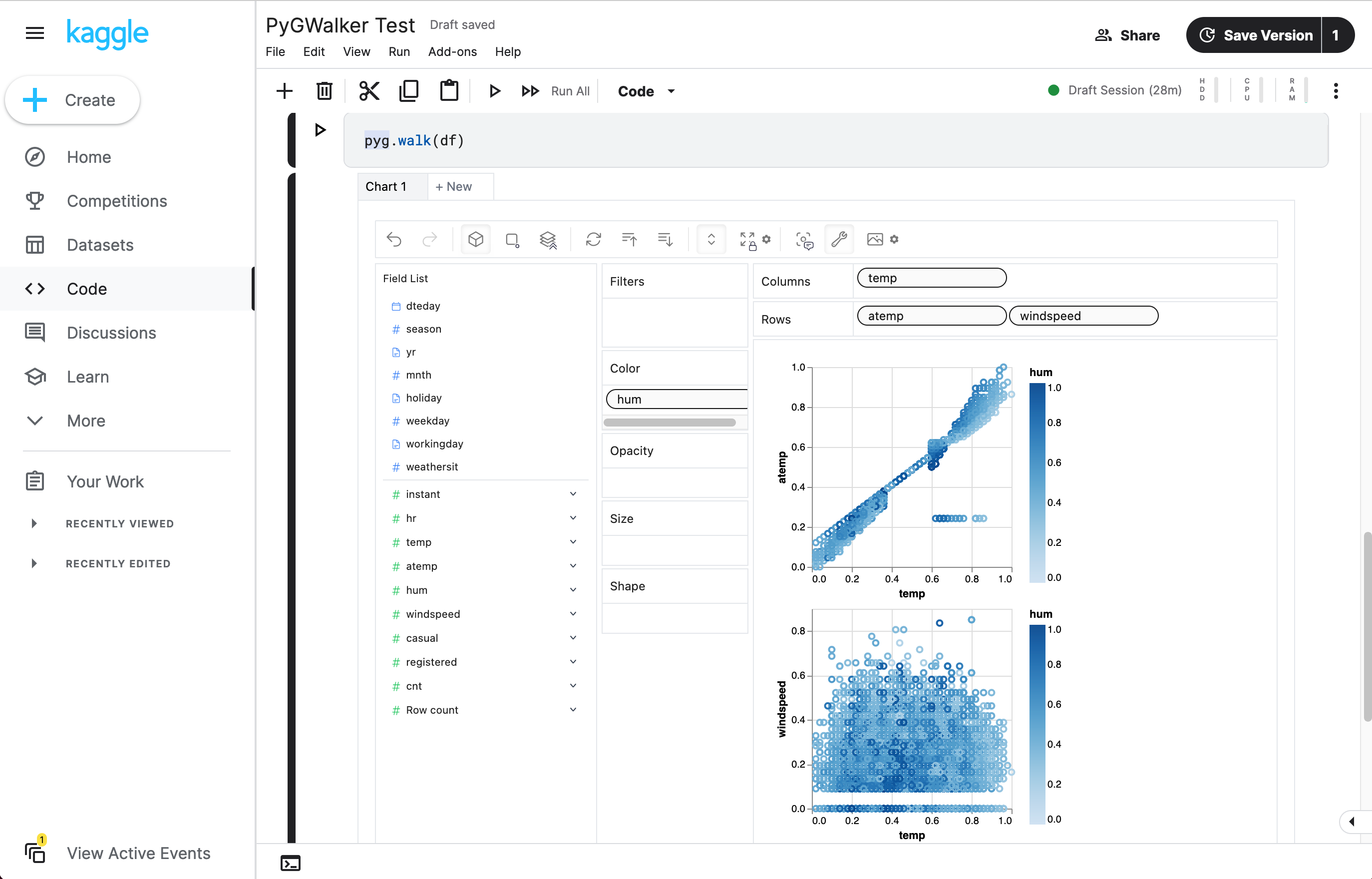
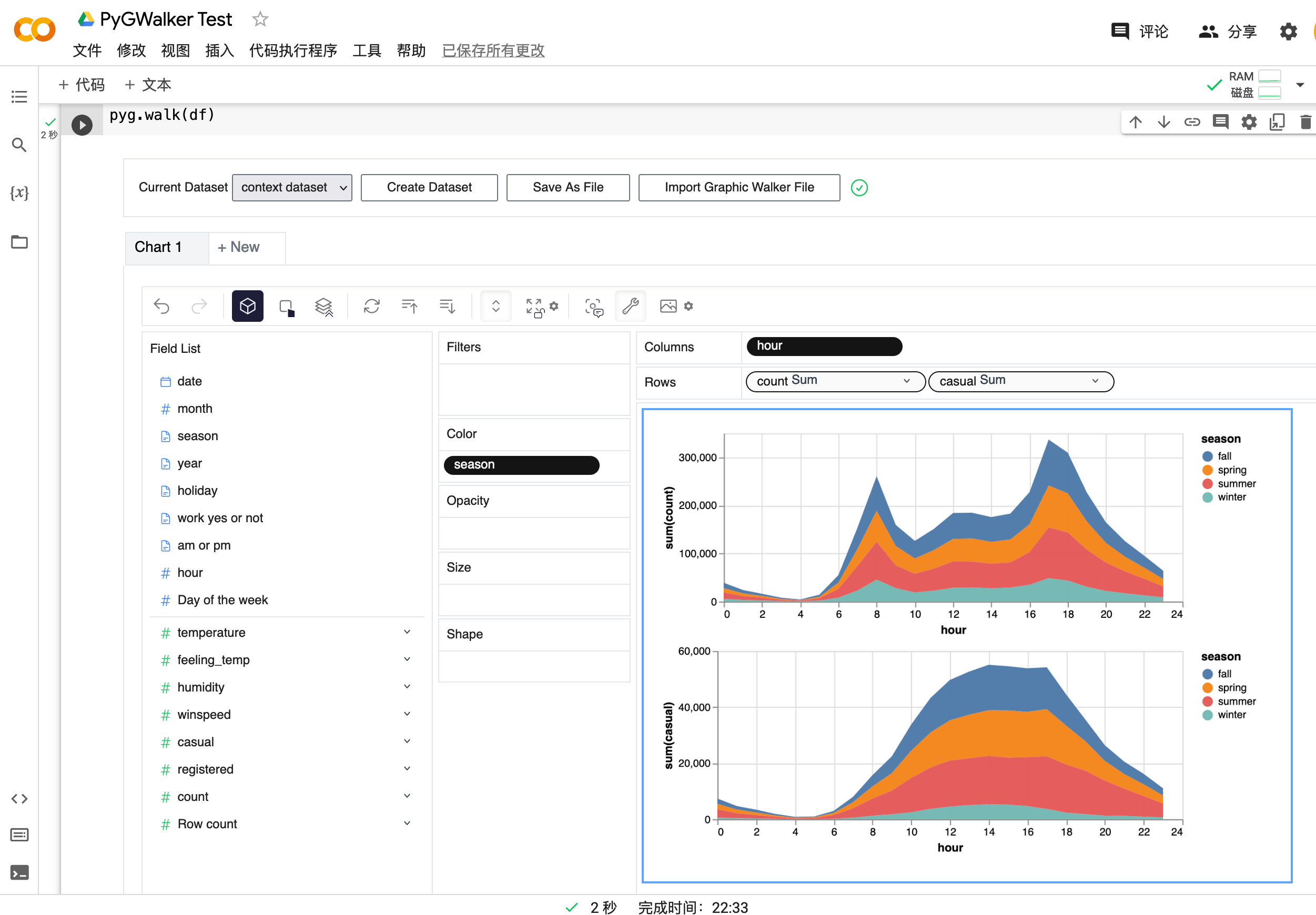
walker = pyg.walk(df)
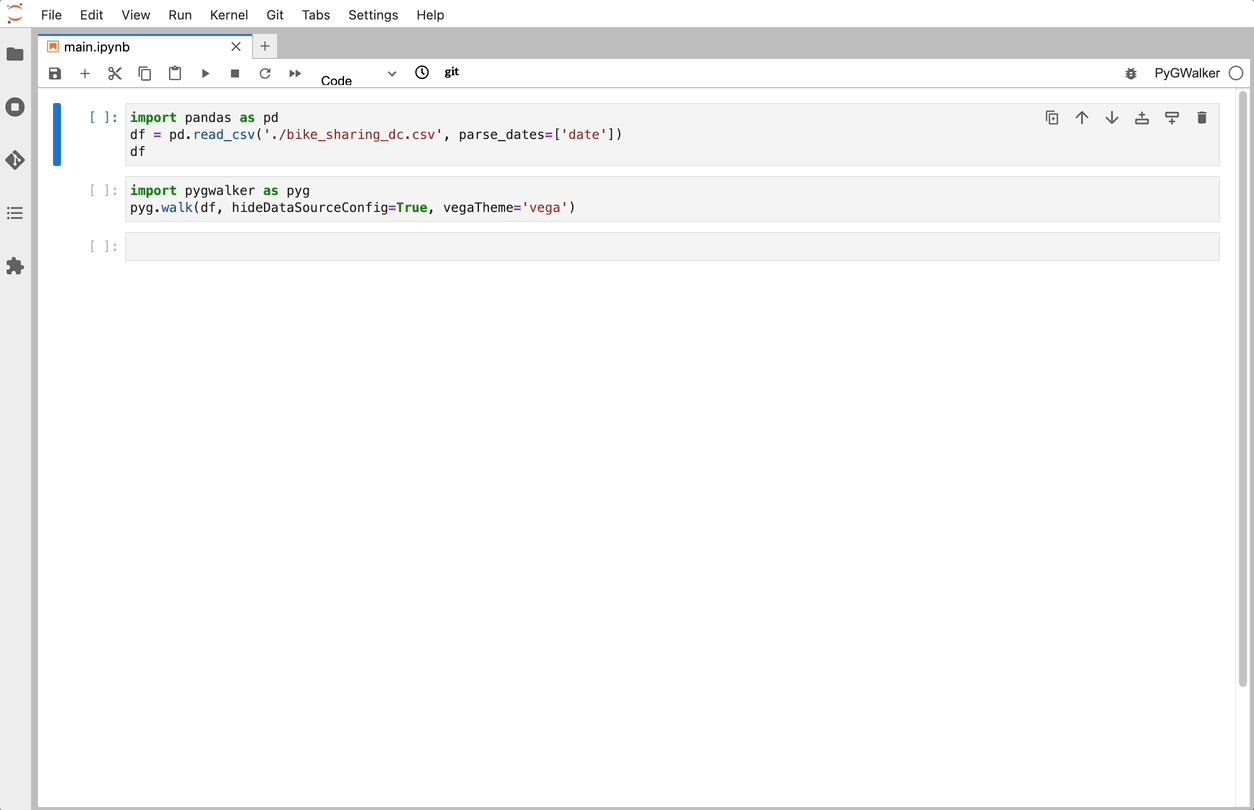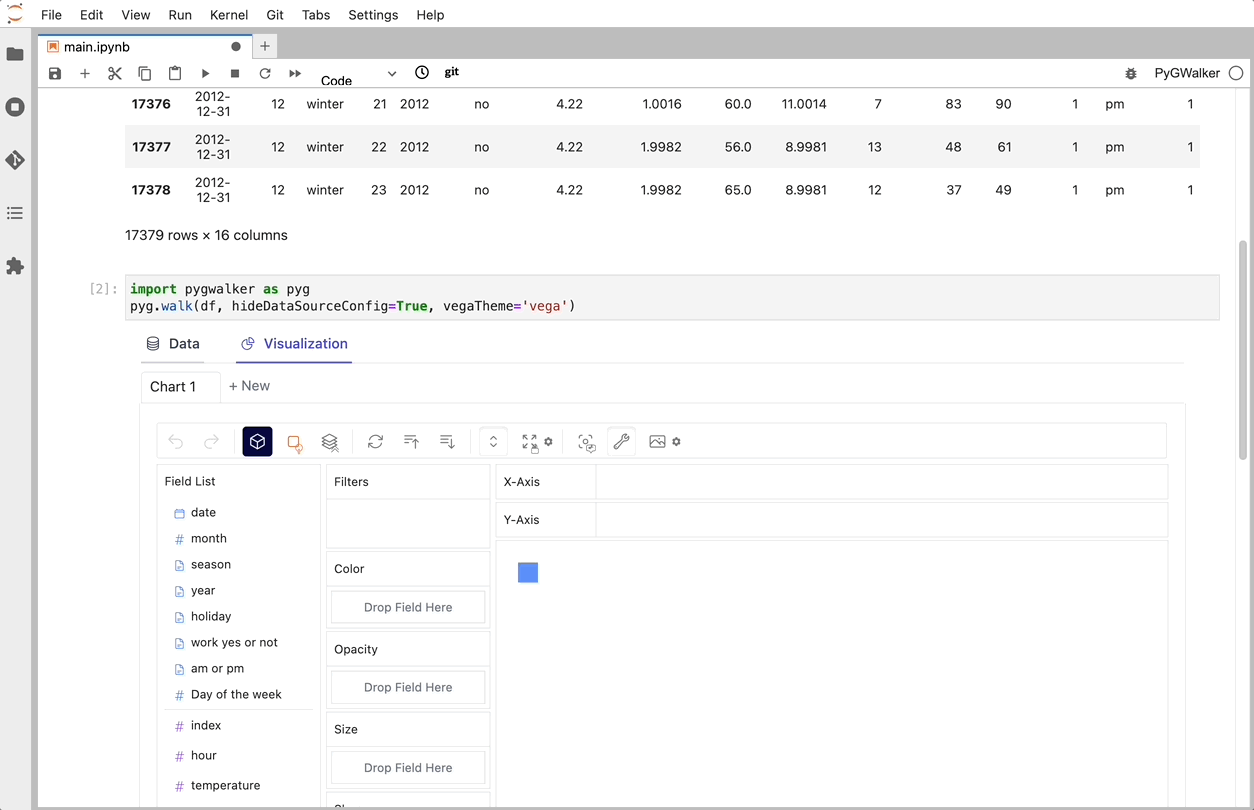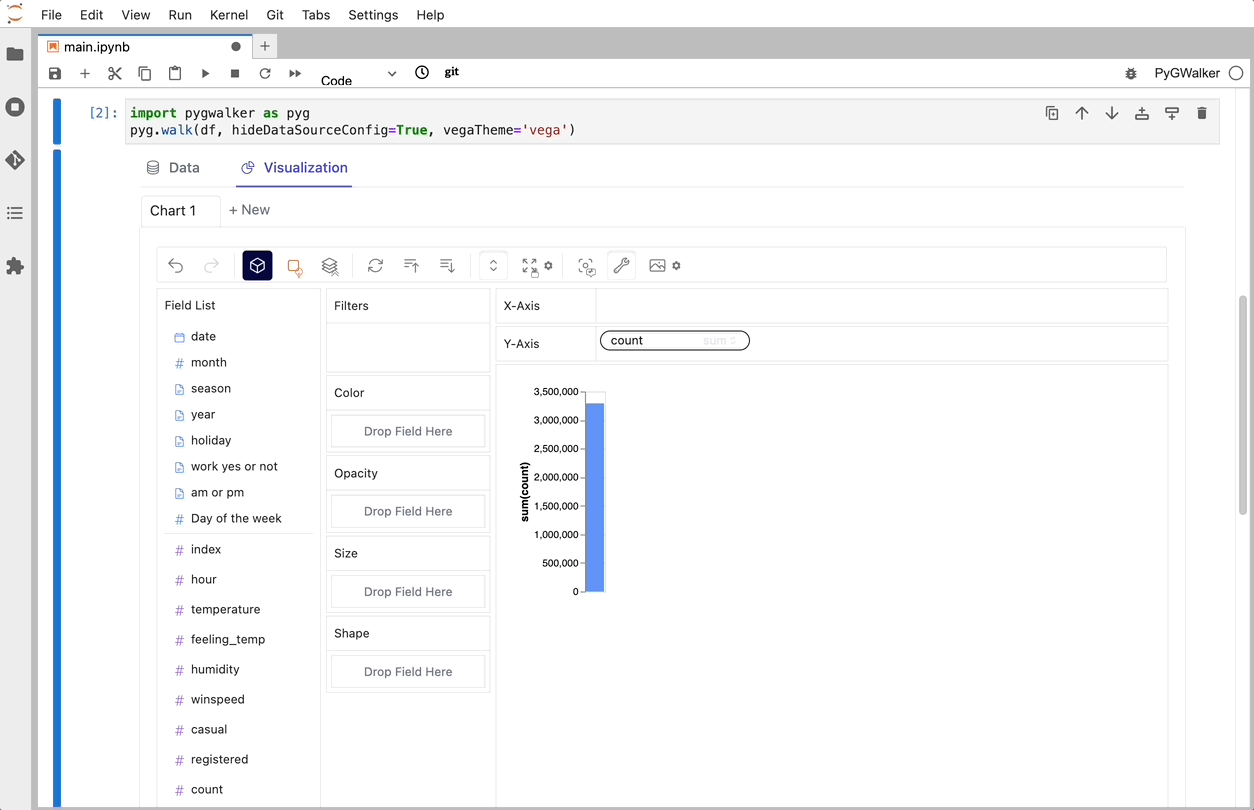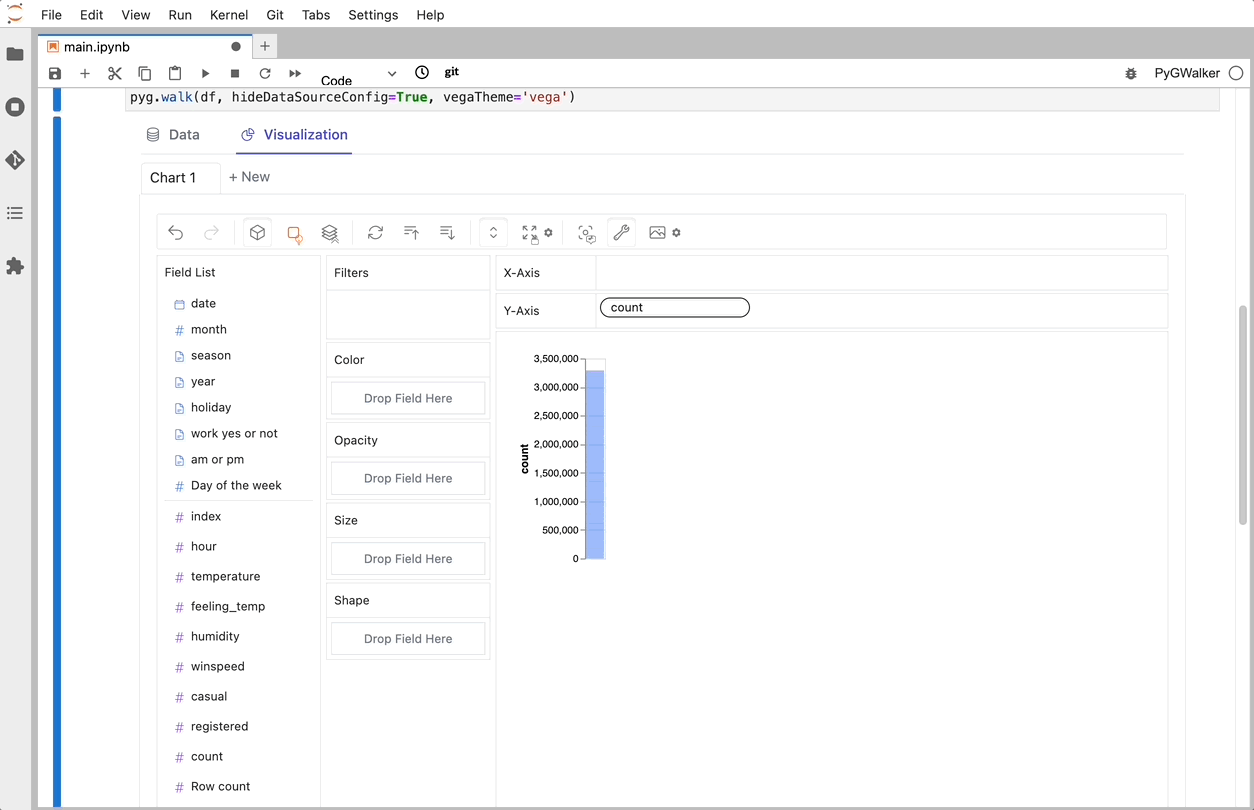
就是这样。现在你有了一个交互式界面,可以通过简单的拖放操作来分析和可视化数据。
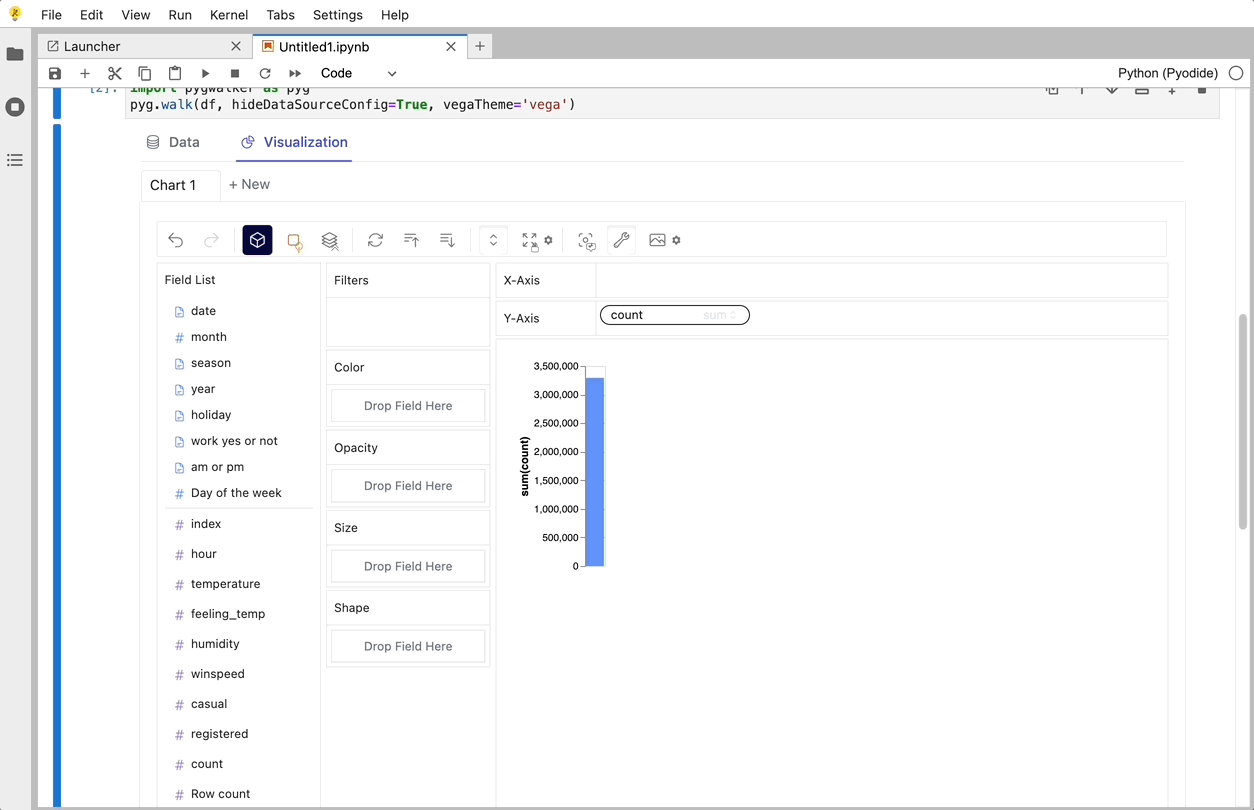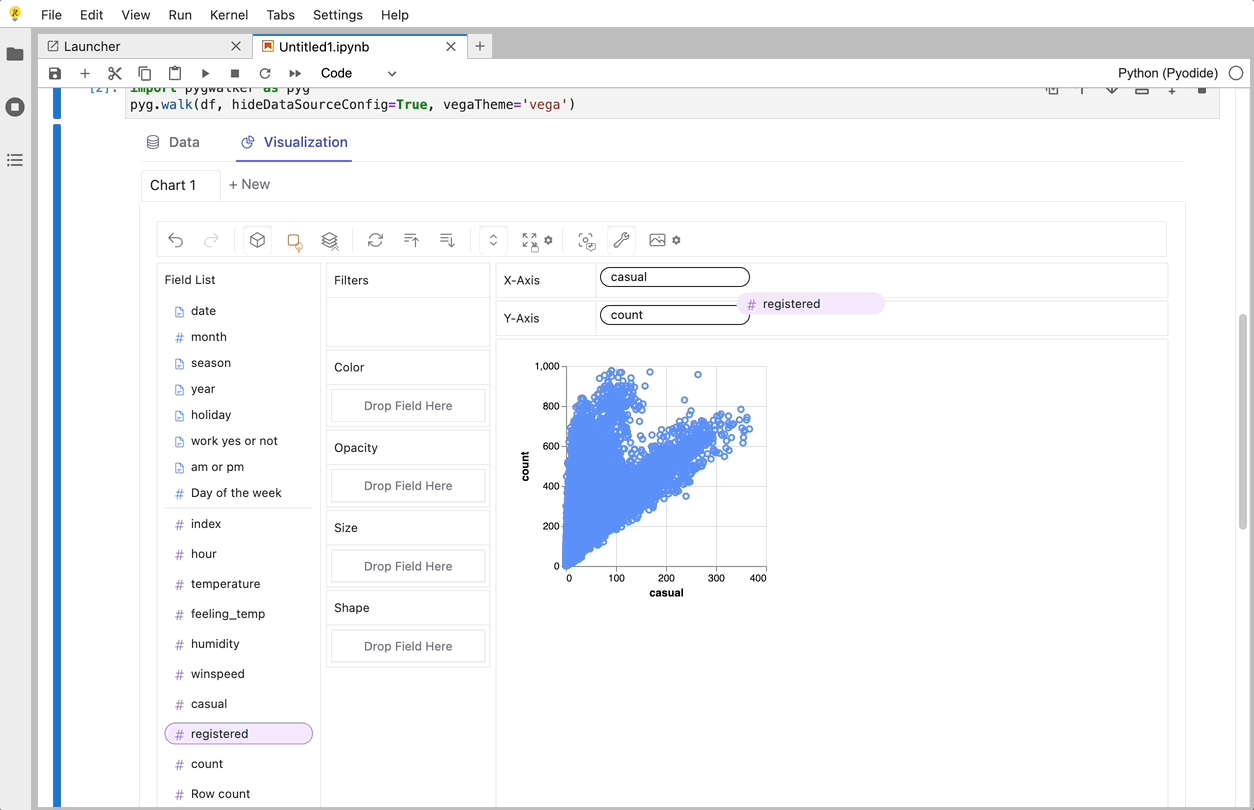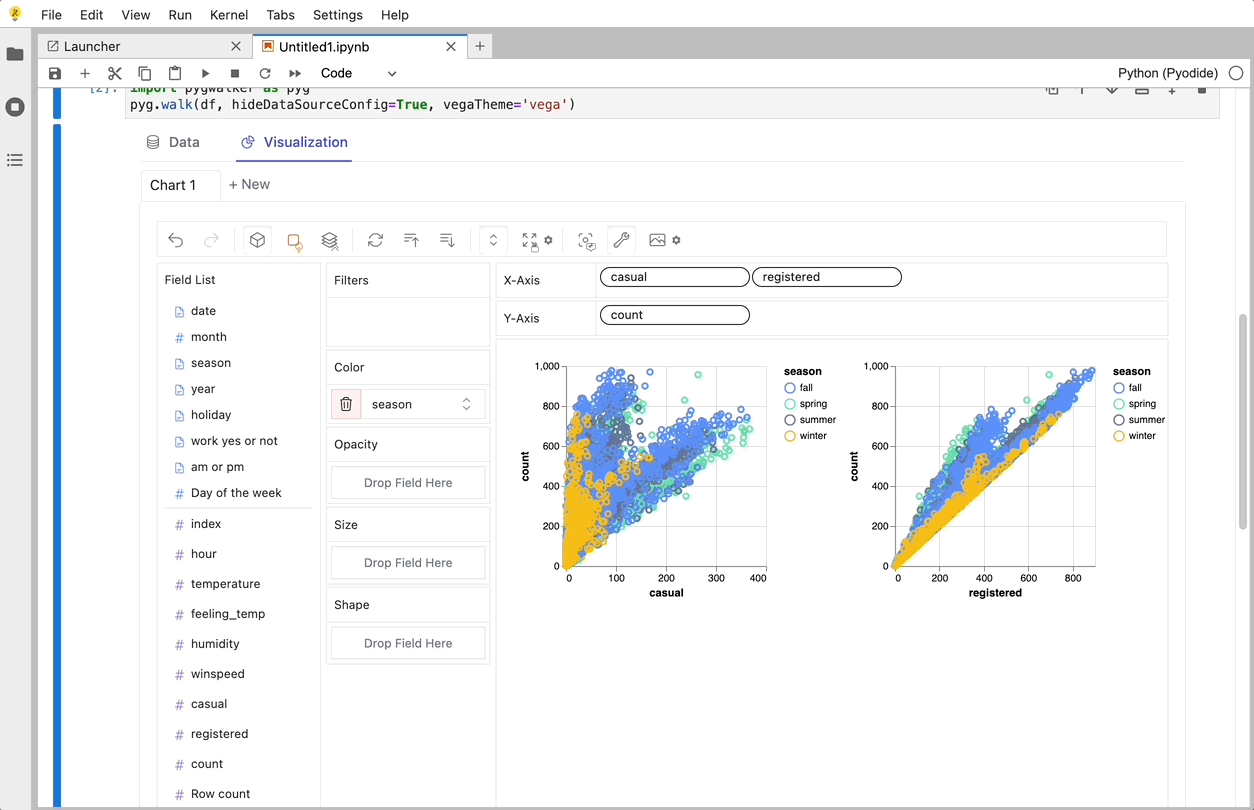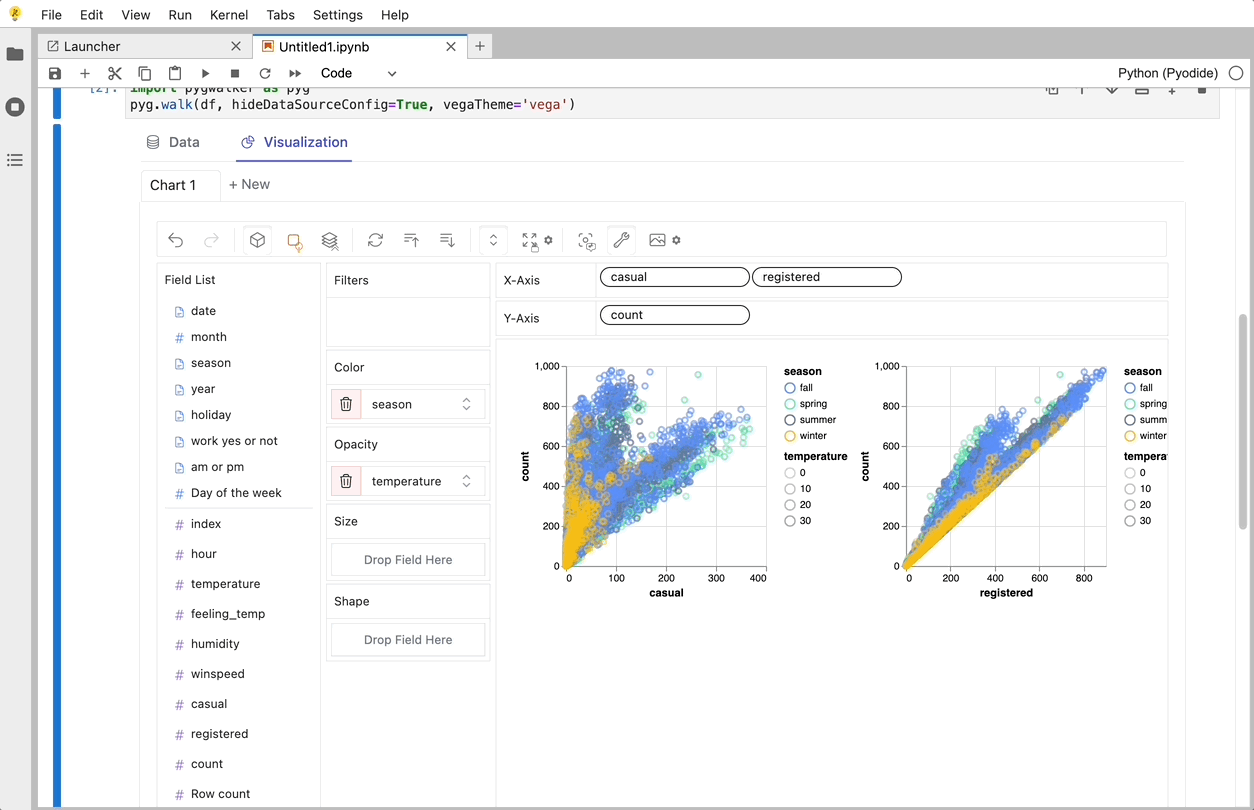
使用PyGwalker可以做的一些很酷的事情:
-
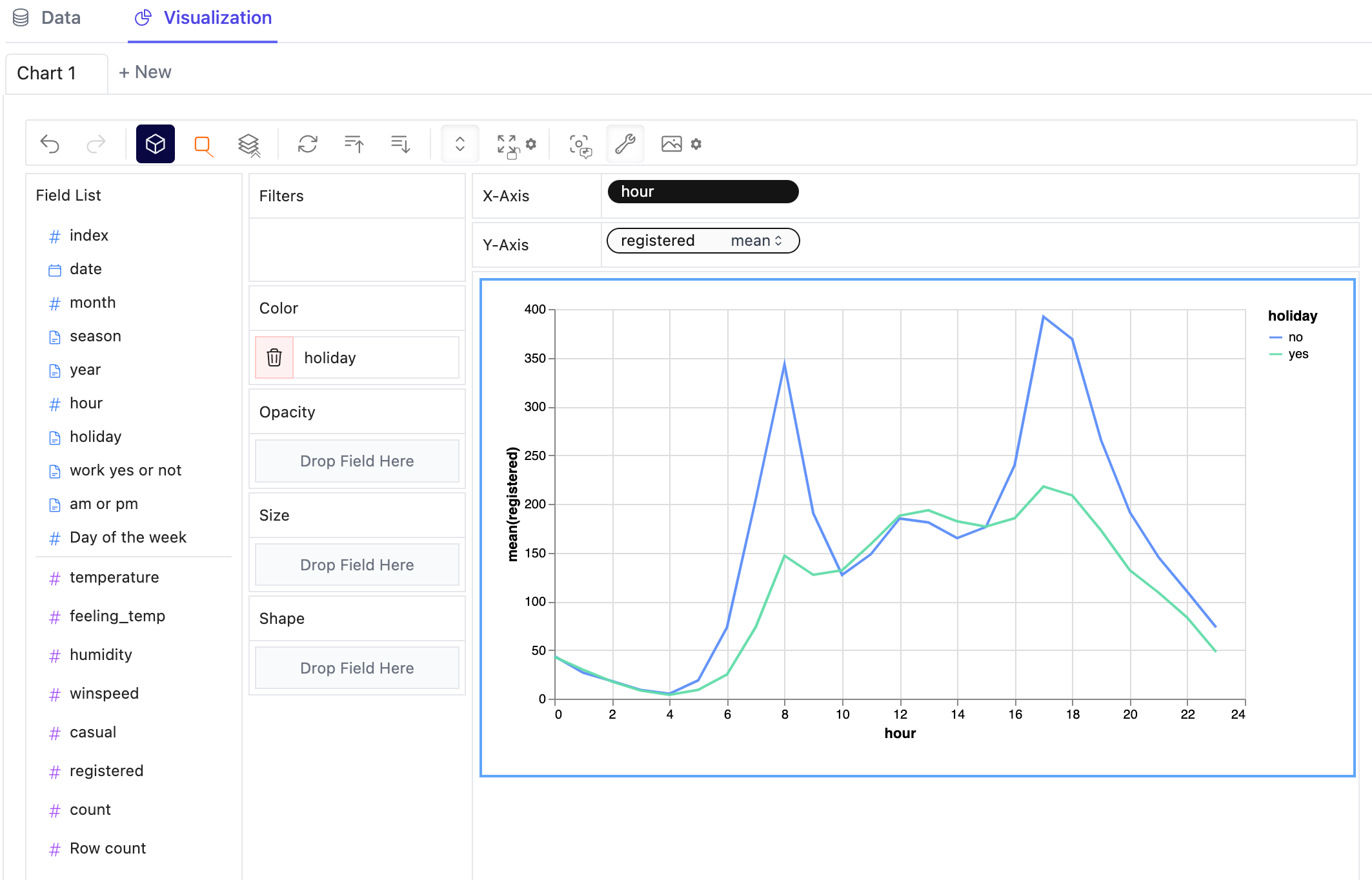
你可以将标记类型更改为其他类型以制作不同的图表,例如,折线图:
-
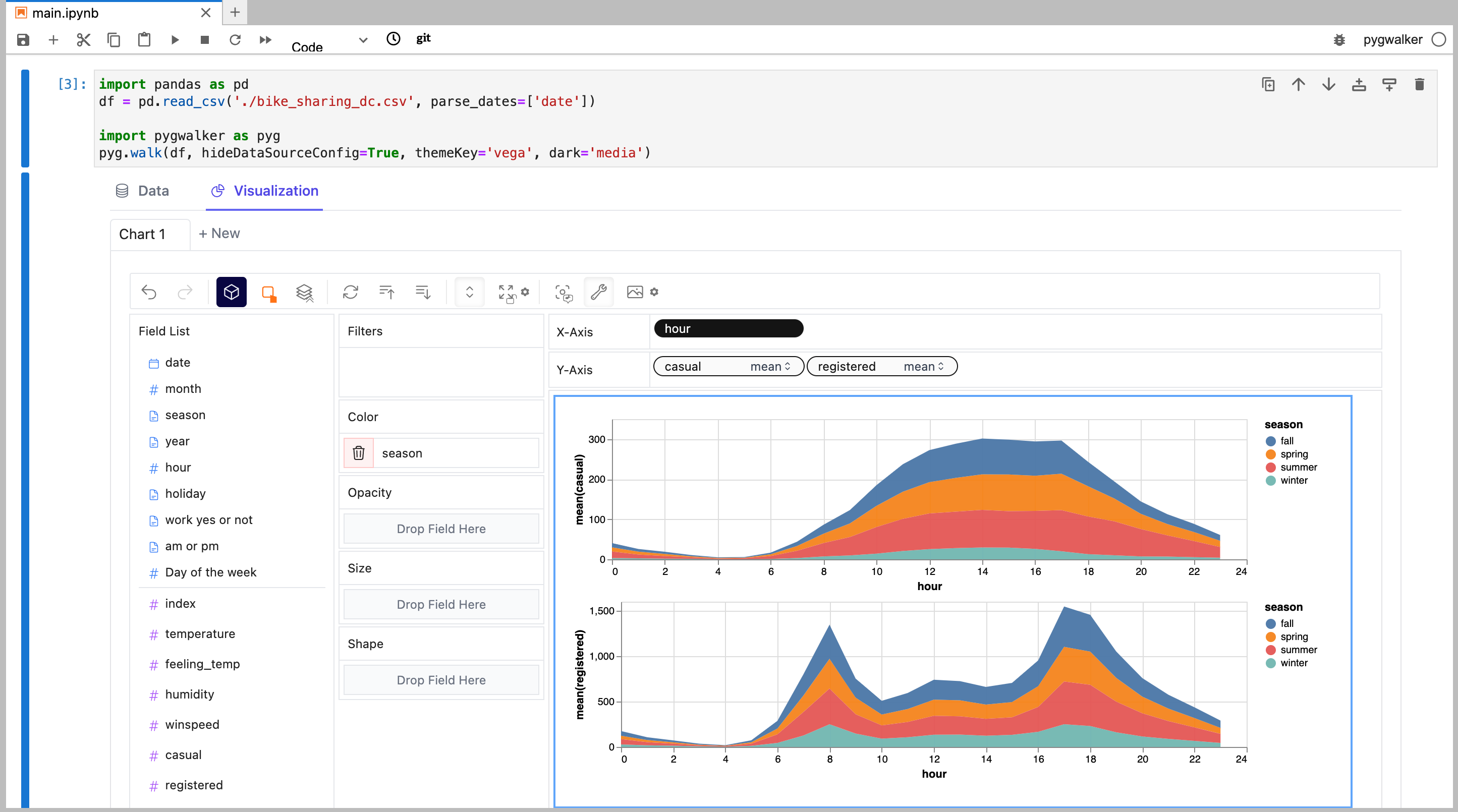
要比较不同的度量,你可以通过在行/列中添加多个度量来创建连接视图。
-
要制作按维度值划分的多个子视图的分面视图,将维度放入行或列中以创建分面视图。
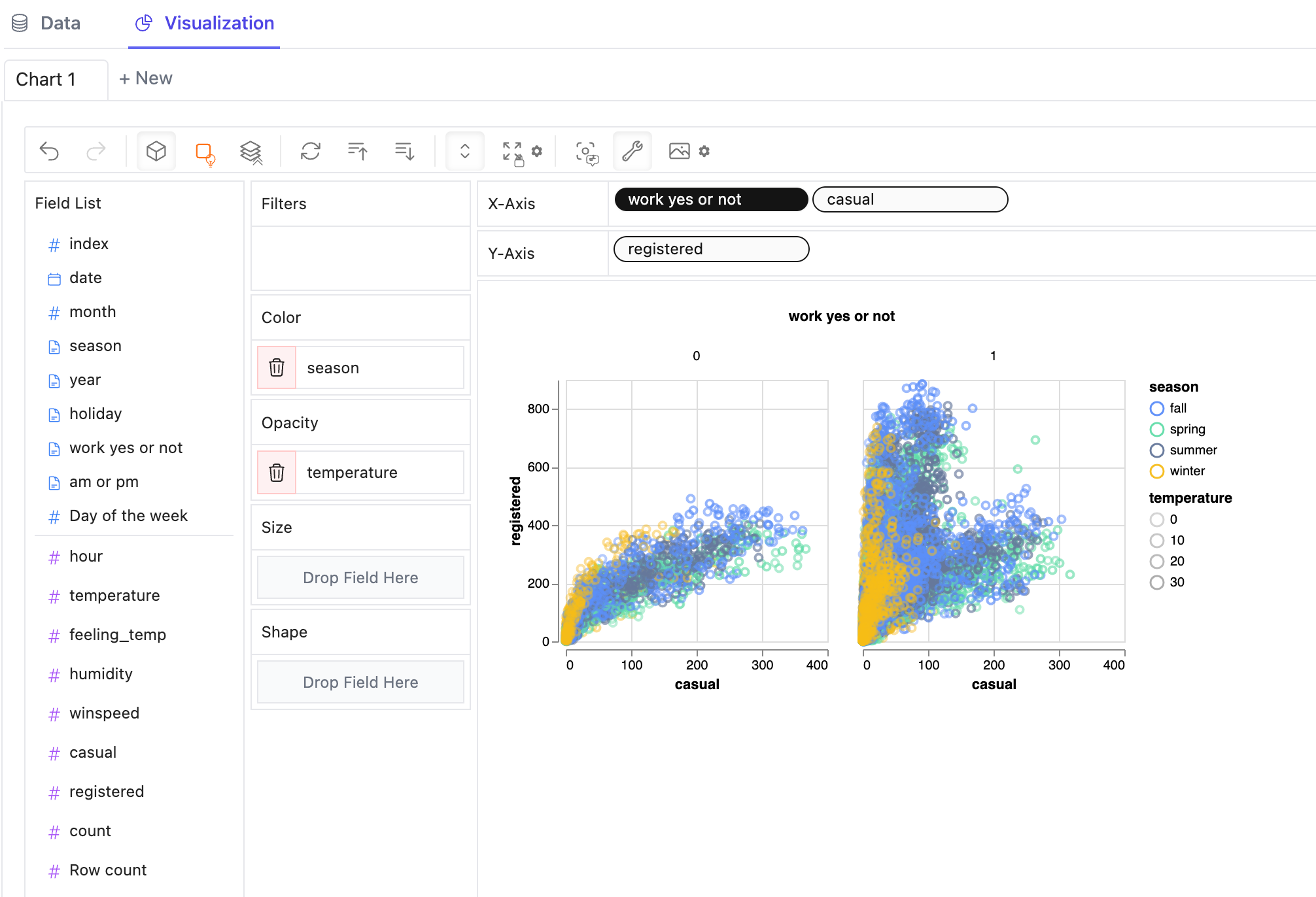
-
PyGWalker包含一个强大的数据表,提供数据及其分布、概况的快速视图。你还可以在表中添加过滤器或更改数据类型。
-
你可以将数据探索结果保存到本地文件
更好的实践
使用pygwalker时,你应该了解一些重要的参数:
spec:用于保存/加载图表配置(JSON字符串或文件路径)kernel_computation:用于使用duckdb作为计算引擎,允许你在本地机器上更快地处理更大的数据集。use_kernel_calc:已弃用,请使用kernel_computation代替。
df = pd.read_csv('./bike_sharing_dc.csv')
walker = pyg.walk(
df,
spec="./chart_meta_0.json", # 这个json文件将保存你的图表状态,你需要在完成图表后手动点击UI中的保存按钮,未来将支持"自动保存"。
kernel_computation=True, # 设置`kernel_computation=True`,pygwalker将使用duckdb作为计算引擎,支持你探索更大的数据集(<=100GB)。
)
本地notebook示例
云端notebook示例
在Streamlit中使用pygwalker
Streamlit允许你托管pygwalker的网页版本,而无需弄清楚Web应用程序的细节。
以下是一些使用pygwalker和streamlit构建的应用示例:
from pygwalker.api.streamlit import StreamlitRenderer
import pandas as pd
import streamlit as st
# 调整Streamlit页面的宽度
st.set_page_config(
page_title="在Streamlit中使用Pygwalker",
layout="wide"
)
# 添加标题
st.title("在Streamlit中使用Pygwalker")
# 你应该缓存你的pygwalker渲染器,如果你不希望内存爆炸的话
@st.cache_resource
def get_pyg_renderer() -> "StreamlitRenderer":
df = pd.read_csv("./bike_sharing_dc.csv")
# 如果你想使用保存图表配置的功能,设置 `spec_io_mode="rw"`
return StreamlitRenderer(df, spec="./gw_config.json", spec_io_mode="rw")
renderer = get_pyg_renderer()
renderer.explorer()
API参考
pygwalker.walk
| 参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| dataset | Union[DataFrame, Connector] | - | 要使用的数据框或连接器。 |
| gid | Union[int, str] | None | GraphicWalker容器div的ID,格式为'gwalker-{gid}'。 |
| env | Literal['Jupyter', 'JupyterWidget'] | 'JupyterWidget' | 使用pygwalker的环境。 |
| field_specs | Optional[Dict[str, FieldSpec]] | None | 字段规格。如果未指定,将从dataset自动推断。 |
| hide_data_source_config | bool | True | 如果为True,隐藏数据源导入和导出按钮。 |
| theme_key | Literal['vega', 'g2'] | 'g2' | GraphicWalker的主题类型。 |
| appearance | Literal['media', 'light', 'dark'] | 'media' | 主题设置。'media'将自动检测操作系统主题。 |
| spec | str | "" | 图表配置数据。可以是配置ID、JSON或远程文件URL。 |
| use_preview | bool | True | 如果为True,使用预览功能。 |
| kernel_computation | bool | False | 如果为True,使用内核计算数据。 |
| **kwargs | Any | - | 额外的关键字参数。 |
开发
参考:本地开发
已测试环境
- Jupyter Notebook
- Google Colab
- Kaggle Code
- Jupyter Lab
- Jupyter Lite
- Databricks Notebook(自版本
0.1.4a0起) - Visual Studio Code的Jupyter扩展(自版本
0.1.4a0起) - 大多数与IPython内核兼容的Web应用(自版本
0.1.4a0起) - Streamlit(自版本
0.1.4.9起),通过pyg.walk(df, env='Streamlit')启用 - DataCamp Workspace(自版本
0.1.4a0起) - Hex Projects
- ...欢迎为更多环境提出问题。
配置和隐私政策(pygwlaker >= 0.3.10)
你可以使用pygwalker config设置隐私配置。
$ pygwalker config --help
用法: pygwalker config [-h] [--set [key=value ...]] [--reset [key ...]] [--reset-all] [--list]
修改配置文件。(默认:~/Library/Application Support/pygwalker/config.json)
可用配置:
- privacy ['offline', 'update-only', 'events'] (默认: events)。
"offline": 完全离线,不发送数据或请求API
"update-only": 仅检查是否有新版本的pygwalker可更新
"events": 分享关于pygwalker中使用了哪些功能的事件,仅包含您到达哪些功能的事件数据,用于产品优化。您分析的数据不会被发送。事件数据将与一个唯一ID绑定,该ID在安装pygwalker时基于时间戳生成。我们不会收集关于您的任何其他信息。
- kanaries_token ['你的kanaries令牌'] (默认: 空字符串)。
你的kanaries令牌,可以从 https://kanaries.net 获取。
参考:https://space.kanaries.net/t/how-to-get-api-key-of-kanaries。
通过kanaries令牌,你可以在pygwalker中使用kanaries服务,如分享图表、分享配置。
选项:
-h, --help 显示此帮助信息并退出
--set [key=value ...]
设置配置。例如:"pygwalker config --set privacy=update-only"
--reset [key ...] 重置用户配置并使用默认值。例如:"pygwalker config --reset privacy"
--reset-all 重置所有用户配置并使用默认值。例如:"pygwalker config --reset-all"
--list 列出当前使用的配置。
更多详情,请参考:如何设置隐私配置?
许可证
资源
PyGWalker云版已发布!你现在可以将图表保存到云端,将交互式单元格发布为Web应用,并使用高级的GPT驱动功能。查看PyGWalker云版了解更多详情。
- 在 Kanaries PyGWalker 上查看更多关于 PyGWalker 的资源
- PyGWalker 论文 PyGWalker: 用于探索性可视化数据分析的即时助手
- 我们还在开发 RATH:一款开源的、自动化的探索性数据分析软件,通过 AI 驱动的自动化重新定义了数据整理、探索和可视化的工作流程。访问 Kanaries 网站 和 RATH GitHub 了解更多!
- YouTube:如何在 Python 中使用 PyGWalker 探索数据
- 使用 pygwalker 在 streamlit 中构建可视化分析应用
- 如果您遇到任何问题需要支持,请加入我们的 Discord 频道或在 GitHub 上提出问题。
- 如果您喜欢 pygwalker,请在以下社交媒体平台上分享!











