
 Github
Github 文档
文档 论文
论文GPT-2
95%的代码和整个想法都属于Andrej Karpathy。我只是添加了大量的详细注释,使我能够理解发生了什么,在哪里发生,为什么发生。我还添加了一些其他内容,并计划慢慢添加KV-Cache、RoPE等功能,具体取决于我的动力和空闲时间。
主要文件:
gpt2.py -- 包含模型架构和类
train_gpt2.py -- 完整的训练循环
fineweb.py -- 预训练数据预处理
gpt_playground.py -- 测试您的自定义模型
可重复性
尽管我们设置了随机生成器的种子,但不同的机器和版本可能会产生不同的结果。是的,即使你尝试设置所有可能的生成器(随机、numpy、环境变量......我都试过)。因此,我在AMD CPU和Metal CPU上得到了不同的生成结果。然而,两者都应该通过整体氛围检查,这目前是我能想到的判断它是否有效的最佳方法。
来自Torch文档:
完全可重复的结果在PyTorch不同版本、单个提交或不同平台之间是无法保证的。此外,即使使用相同的种子,CPU和GPU执行之间的结果也可能无法重现。
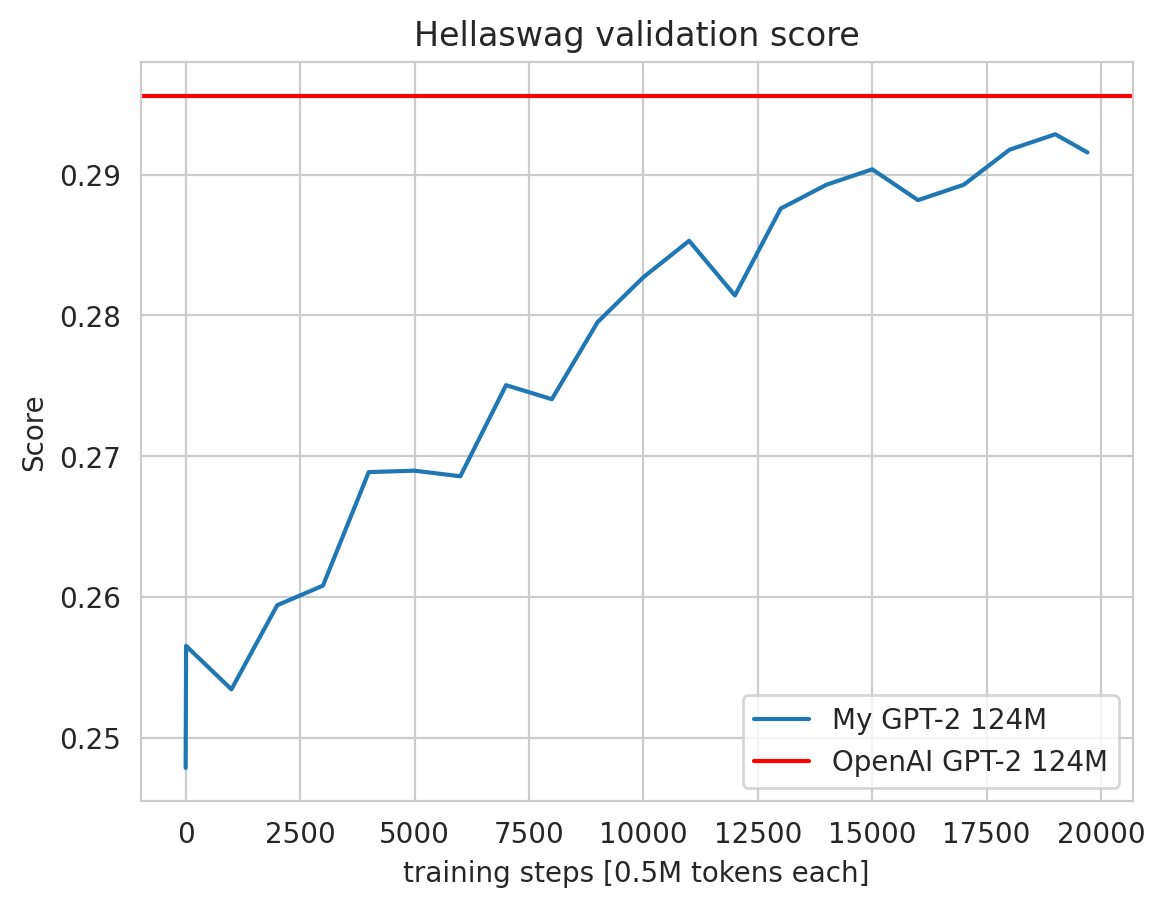
最终结果
所以,嗯。出了点问题,我的性能略低于Karpathy在视频中取得的成果。我不确定为什么,我仔细检查了所有参数,重新审视了代码,但如果有某个微小的错误导致Hellaswag的性能下降了0.01,那我可能需要花20个小时来追踪它。我已经接受了这个事实。也许,我不知道,这可能是由于使用了不同的显卡——我希望如此。
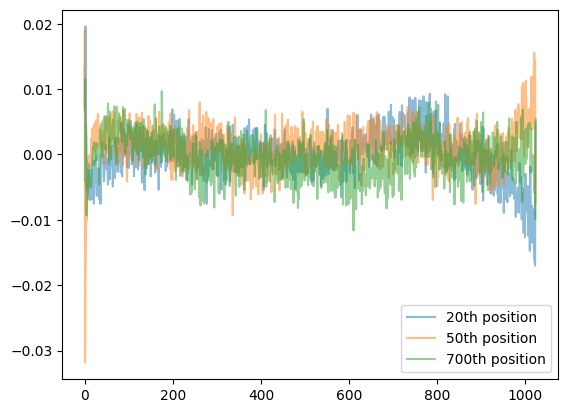
演练笔记:
- 嵌入层中的嘈杂嵌入线表明模型可能还需要更多训练
- GPT-2 仅使用解码器,因此其架构如下:
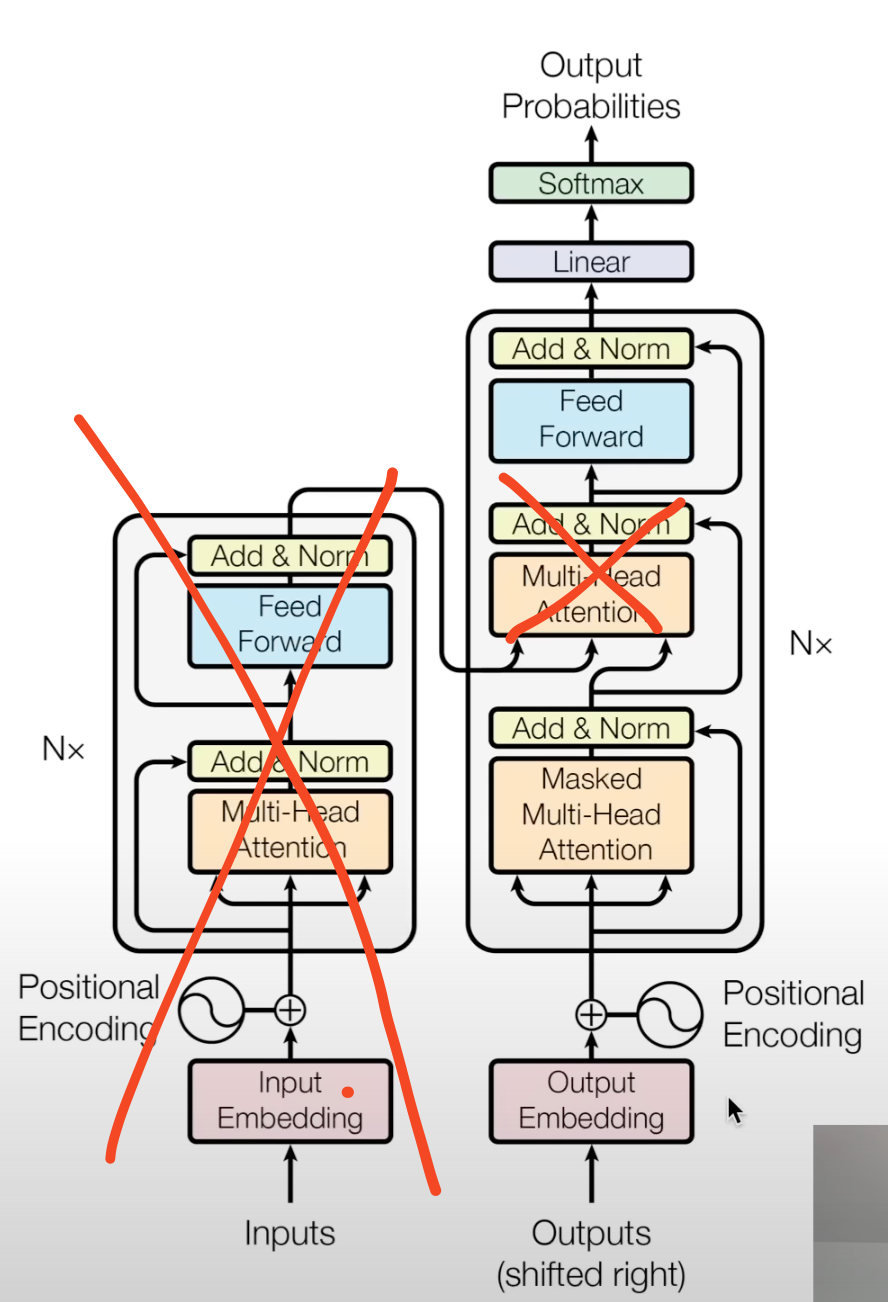 此外:
此外: - 位置嵌入是学习得到的 原始模型中它们的噪声表明模型训练不足
- 层规范化在块之前,而不是之后 这是因为干净的残差路径是一个理想的架构选择 这允许梯度从最顶层无中断地流动,因为加法只是将它们传递下去
- 在最后的自注意力后添加了层规范化
- 模块字典中的h是整个灰色块
- mlp是映射,attention是归约
- 线性层初始化为正态分布(0, 0.02),偏置为0,嵌入也是正态分布(0, 0.02),默认情况下torch不会将偏置初始化为0。通常如果遵循Javier初始化,标准差应等于$\frac{1}{\sqrt{\text{n}\textunderscore\text{module}\textunderscore\text{features}\textunderscore\text{incoming}}}$,GPT2论文大致遵循这一点,因为$\frac{1}{\sqrt(768)}=0.036$,所以与$0.02$相差不远
- 层规范化也可以初始化,但我们保留默认值,即比例为1,偏移为0
- 残差流中堆叠层的累积标准差保持为1,以控制前向传播后激活的增长(不完全清楚如何直观地看到这一点)
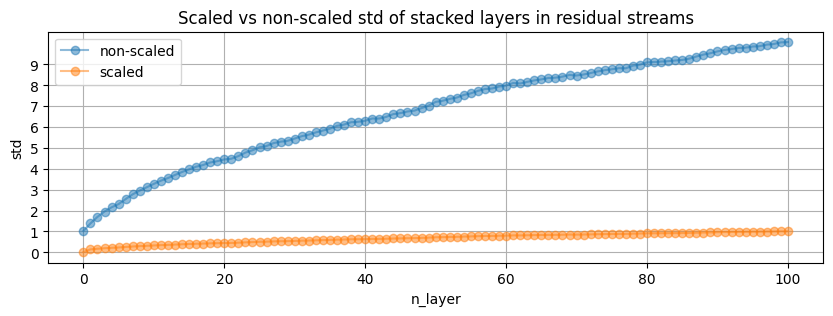 这看起来很像随机游走中方差的增长
这看起来很像随机游走中方差的增长 - 在不同设备上使用
torch.manual_seed时,它确实有效并给出相同的结果 - Andrej使用
import code; code.interact(local=locals())进行即时调试 - int8用于推理而不是训练,因为它们的间距均匀,说实话我不太明白这是什么意思,这可能是我对这个仓库中所有不确定的东西最不理解的部分,更重要的是需要浮点数以匹配权重和激活分布 —— 这到底是什么意思,我现在真的不知道(现在是午夜,也许我知道但现在不清楚)
- 改变数据类型会影响3个不同的因素:1. FLOPS, 2. VRAM, 3. 内存带宽速度,例如A100 80GB对于Float16是(312 TFLOPS, 80GB, ~2000GB/s),这里可以了解更多:A100白皮书
- mps对其他工作负载非常(非常)敏感,我在训练中每秒获得2-3k个token,一旦我只是滑动到左侧屏幕,它就降到了每秒300个token
- Float32 vs TF32(及其他):
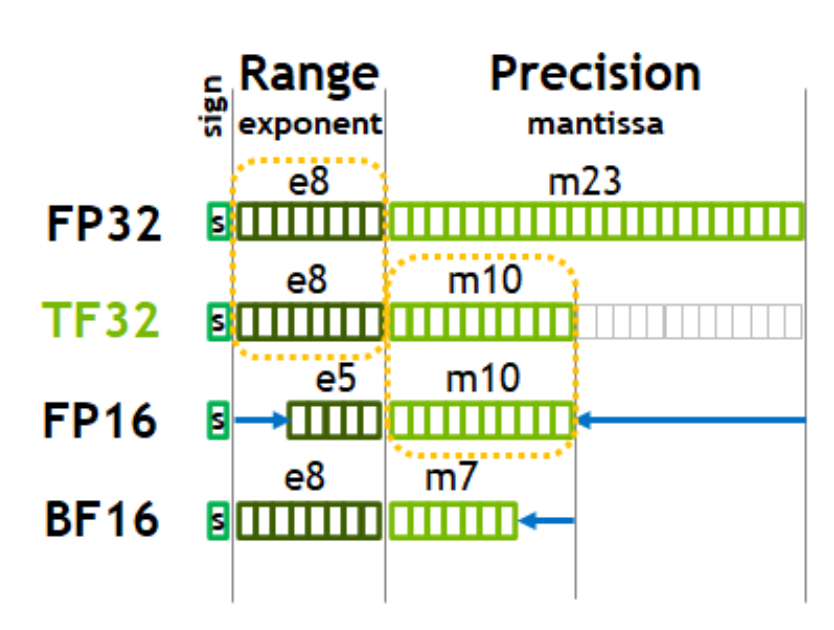 直观地说:指数跨越范围,而尾数允许在这个范围内更精细地放置数字。在TF32中,尾数被压缩到10位(从23位),我认为MPS支持BFloat16,而不是TF32 MPS着色器数据类型是我能快速找到的唯一数据类型文档。—— 回到这个问题:在
直观地说:指数跨越范围,而尾数允许在这个范围内更精细地放置数字。在TF32中,尾数被压缩到10位(从23位),我认为MPS支持BFloat16,而不是TF32 MPS着色器数据类型是我能快速找到的唯一数据类型文档。—— 回到这个问题:在scratch.py中有一个快速函数来检查设备上可用的数据类型,看起来MPS不支持torch.bfloat16,但CPU支持 - FP32、TF32和BF16跨越相同的范围,但精度逐渐降低,FP16跨越较小的数字范围,这就是为什么它不能与其他3种互换使用 —— 我们无法表示所有相同的数字,所以我们必须缩放梯度等。看这里可以很好地了解pytorch中自动混合精度的使用。它基本上说如果我们不改变使用的数据类型范围,那么我们应该使用
autocast作为前向传播和损失计算的上下文管理器(只有这个!不包括优化器步骤等),它还说我们不应该手动将任何张量转换为half(FP16)或BF16。我在这里不确定的是:为什么使用FP16需要使用梯度缩放器?我们不能用FP16也计算梯度吗,这样从一开始就一切都在同一范围内,不需要缩放? - 只有模型的某些部分受影响autocast文档,因为某些操作对精度变化更敏感,不应自动降低精度(对一般情况来说不能安全进行),例如softmax、层规范化等
torch.compile对元素级操作进行内核融合,减少数据在GPU和HBM之间的往返次数(可能还做了更多事情),torch.compile通常减少Python开销和GPU读/写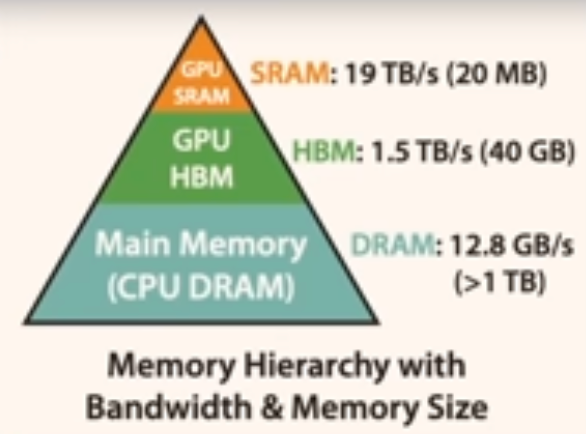
 不仅CPU <-> GPU传输很重要。SRAM和HBM之间的I/O速度和次数也需要追踪,因为它们经常成为瓶颈。内核融合对此特别有用,因为它们减少了SRAM <-> HBM传输的次数。
不仅CPU <-> GPU传输很重要。SRAM和HBM之间的I/O速度和次数也需要追踪,因为它们经常成为瓶颈。内核融合对此特别有用,因为它们减少了SRAM <-> HBM传输的次数。- 如果
autocast抛出设备错误 —— 确保你传递的是设备字符串,而不是设备对象,即如果你有类似torch.device("cuda")的东西,你应该这样传递with torch.autocast(device_type=device.type, ... - Flash Attention是一种内核融合操作。那为什么
torch.compile不能做到呢?因为它需要对注意力机制进行算法重写。尽管Flash Attention在计算上更昂贵,但它需要更少的HBM/SRAM传输,而这些传输实际上是注意力运行时间的一大部分原因。因此,通过使用更多的计算,我们减少了数据传输,总体上节省了时间。Flash Attention的主要前提是大的注意力矩阵(T, T)在键和查询之间的交互从未被具体化。FlashAttention和FlashAttention2,以及Flash Attention工作方式背后的主要机制是部分softmax计算机制。Flash Attention甚至在CPU上也有帮助,将我们的速度从776 tok/s提高到1154 tok/s。 - 2的幂非常强大。我们可能都知道,基本上计算机内的一切都是2的幂。我们想要2的幂。它们需要更少的边缘情况,通常不需要特殊处理。我们如此需要它们,以至于我们会检查代码,寻找那些没有很多2的幂的数字并修复它们,这将带来巨大的改进。其中一个这样的数字是vocab_size=50257,我们将它稍微推到50304,结果发现我们甚至可以将它除以128。这将我们从776 tok/s -> 818 tok/s(无FlashA)-> 1191 tok/s(+FlashA)。这在功能上没有改变任何东西。WTE层永远不会索引到这些额外的权重,因为我们在分词器中根本没有这些标记,lm_head会为这些嵌入分配一些概率,并且必须将它们驱动到-inf(因为它们永远不会出现,所以它们的概率必须为0),但这与可能永远不会出现或很少出现的真实标记没有什么不同。
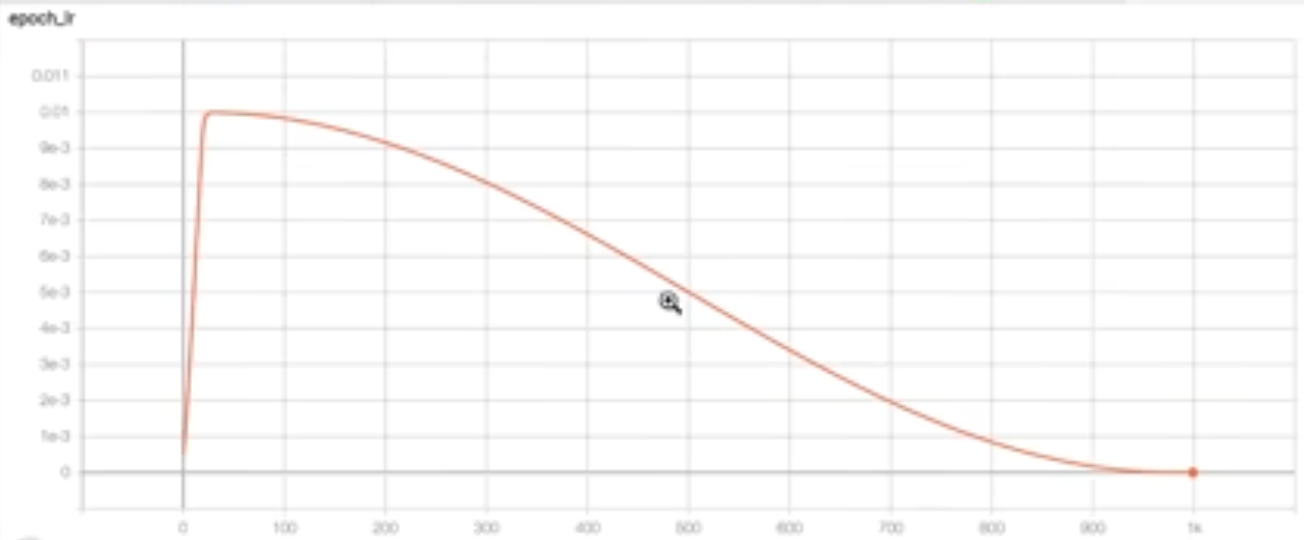
- 关于学习率和余弦衰减没有太多可写的。基本上,如果你第一次看到它,其思想是学习率被某个系数调节(我读的科学文章越多,我写作的风格就越像他们 —— 这只意味着$lr \cdot coeff$)。在这种情况下,系数根据我们在训练中的位置以3种不同的方式变化:1. 它从某个小值线性增长,例如$0.1 \cdot lr$,到$lr$,2. 像余弦从其峰值下降一样变小,3. 在训练结束前保持恒定,例如再次为$0.1 * lr$。在图表上看起来像这样:
- 权重衰减:GPT3论文指出,在训练中OpenAI(我写"他们是Open"时有点抽搐,因为这篇论文实际上是CloseAI)使用权重衰减来正则化权重。正则化是$0.1$。
- 梯度累积可以用作模仿GPT-2大批量大小的方法,而不需要OpenAI级别的资源,只需累积梯度,并在需要时进行优化器步骤。这里重要的一点是,torch损失通常用"平均值"减少批次损失。我可能会搞砸,Karpathy在视频中解释得很好,但总的来说,累积会仅通过批量大小$B$的平均值减少所有累积的小梯度,但当累积时我们的实际批量大小是$B\cdot accumulation\textunderscore steps$。
- DDP是分布式数据并行。它允许你运行模型的$n$个副本并在它们之间分割数据,有效地将训练时间缩短约$n$倍。DDP带来了并行工作特定的术语 —— 等级、本地等级、世界大小、节点、AllReduce。
- 节点 —— 一台单独的机器,可能有任意数量的GPU
- 等级 —— 分配给在其中一个GPU上运行的进程的ID,对训练运行中的所有GPU都是唯一的(2个节点各有2个GPU = 4个等级)
- 本地排名 —— 分配给在特定节点上的某个 GPU 上运行的进程的 ID,仅在节点内唯一(2 个节点各有 2 个 GPU = 每个节点 2 个本地排名)
- 世界大小 —— 分布式训练运行中启动的所有 GPU(进程)的数量(2 个节点各有 2 个 GPU = 世界大小为 4)
- 全局规约 —— 与规约相同,数组 -> 单一数值操作,但与训练运行中的所有排名共享结果(规约只在一个排名上留下结果),我们在所有排名上完成单次前向传播后运行全局规约,平均梯度并与所有排名共享,这样它们都可以执行相同的优化步骤
- torch.compile 会在每个模型键前添加 _orig_mod.,如果你计划进一步使用该模型,请记住在保存前删除它或之后处理它,简单的 .replace("_orig_mod.", "") 就能解决
其他快速智慧
- torch 缓冲区基本上是不可学习的模型张量
- torch 的 view 和 reshape 非常相似,但 1. reshape 可以处理非连续张量(仍需检查非连续时出错的原因),2. view 将返回一个使用与被查看对象相同内存区域的张量,reshape 可能会克隆或返回相同内存
- 在网络初始化时,我们期望所有词汇标记具有大致相等的概率,我们不希望分布过于尖峰,因此在这种情况下,损失应等于 $$L(\frac{1}{\text{vocab}\textunderscore\text{size}}) = L(\frac{1}{50257}) = -ln(\frac{1}{50257}) = 10.82$$
- 天才建议:为了确保你的实现是正确的,检查是否可以在单个例子上完全过拟合
- .data_ptr() 允许检查张量在内存中的存储位置
- lm_head 和 wte 权重是相同的,这来自 2016 年的论文《Using the Output Embedding to Improve Language Models》,该论文认为这显著提高了性能,直观解释是"对于输入嵌入,我们希望网络对同义词有相似反应,而在输出嵌入中,我们希望可互换单词的分数相似",这让我们节省了约 30% 的模型参数,非常棒
- nn.module 子类上的 apply 将把其参数应用于所有子类模块(我认为只适用于模块,不确定)
- 我没有观察到使用 torch.set_float32_matmul_precision("high") 在 MPS 上有任何加速(10 批次,B=16,T=256)—— 后来检查发现 MPS 甚至不支持 bfloat16,但在 CPU 上运行时似乎支持
A100 白皮书说应该是 8 倍,但在 Andrej 的案例中只有 3 倍,在我的案例中...你可以看到使用较低精度: 平均批处理时间:1.82 秒 平均令牌/秒:2265.09 不使用较低精度: 平均批处理时间:1.74 秒 平均令牌/秒:2400.92 - torch.cuda.max_memory_allocated 在你无法用 nvidia-smi/nvtop 精确定位 VRAM 使用情况,而你有一种感觉应该查看最大分配内存时非常有用,它给出了程序启动以来的最大分配内存
- torch.compile 和 torch.autocast 都不适用于 "mps" 设备和 M 系列 MacBook(或者至少我无法在不付出重大努力的情况下使它们运行),此外,autocast 在 "cpu" 设备上运行非常糟糕,几乎冻结程序,compile 运行,但性能略差于非编译版本(650 令牌/秒 vs 750)
- 很酷的是你可以传递参数组和它们特定的优化参数,就像我们对权重衰减所做的那样
param_dict = {pn: p for pn, p in self.named_parameters() if p.requires_grad} decay_params = [pn for pn, p in param_dict.items() if p.dim() >= 2] nondecay_params = [pn for pn, p in param_dict.items() if p.dim() < 2] optim_groups = [ {"params": decay_params, "weigth_decay": weight_decay}, {"params": nondecay_params, "weigth_decay": 0.0}, ] optimizer = torch.optim.AdamW(optim_groups, lr=lr, betas=(0.9, 0.95), eps=1e-8) - 全局规约与规约相同,但在每个排名(设备、进程等)中留下规约结果,而不是单一位置。我们可以通过例如执行自定义全局规约来轻松处理跨排名变量:
torch.distributed(some_variable, op=torch.distributed.ReduceOp.SOMEOP)。优秀的 nccl 文档
[图片] [图片]
我的想法
- 用绳子训练
- 在小模型上调整参数
- 尝试其他激活函数
- 进一步了解层归一化和稀疏性
- 从一开始就将input.txt中未见过的token设为-inf
- 更好地组织README,为较小的章节添加代码片段
- 使用CUDA实现在线softmax?
- 用PyTorch profiler进行性能分析,尝试优化
- 在线softmax如何实现闪电注意力?
问题
- 为什么自动转换为FP16需要梯度缩放?我们不能直接用FP16计算梯度吗?这样所有张量都在同一个数值范围内,是不是就不需要缩放了?
我的实现错误
使用原始huggingface权重克隆时生成质量低(bc5e9a1d)
这是一个警示故事,GPT-4和Claude 3.5 Sonnet都无法帮我解决。两个模型在本质上是字符串比较的问题上都失败了。尽管两者都被明确要求调试可能的拼写错误。
不知什么原因,我的生成结果看起来像这样:
> 你好,我是一个语言模型,语言模型模型模型模型模型模型建模模型建模建模建模建模建模建模建模建模建模建模建模建模
> 你好,我是一个语言模型,系统、系统、系统、系统、系统,的的的的的的的的的的的的
> 你好,我是一个语言模型,不是,不是,不是,不是,不是,不是,不是,不是
2323232323
> 你好,我是一个语言模型,一个语言模型,一个语言模型模型模型模型...
Markus ... ... ... ... ... ... ...
> 你好,我是一个语言模型,模型模型,模型,模型,模型,模型,模型,模型,模型,模型不是不是不是不是
而不是:
> 你好,我是一个语言模型,不是一门科学。我是一个语言设计师。我想写作,我想思考。我想
> 你好,我是一个语言模型,我使用英语句子结构,我喜欢单词胜过句子。
"没关系,我会看看
> 你好,我是一个语言模型,不只是另一种语言。"这不是一个"语言模型"吗?这是一个想法。到目前为止,什么
> 你好,我是一个语言模型,不是编程模型。我不是理论计算机模型 - 你没看错 - 因为我的想法是
> 你好,我是一个语言模型,我自学。
我想更多地了解语言如何工作以及为什么可以使用它们。
经过大量的断点和print(x)、print(x.shape),发现我的h[x].c_attn.bias被错误地复制了(或者我是这么认为的),这很奇怪,因为权重似乎复制正确。
h[0].c_attn.bias的正确偏置:
tensor([ 0.4803, -0.5254, -0.4293, ..., 0.0126, -0.0499, 0.0032],
requires_grad=True)
我的偏置:
tensor([-0.0198, -0.0302, 0.0064, ..., 0.0146, -0.0021, -0.0181],
requires_grad=True)
事实证明,没有注意力头的偏置看起来像这样。所有头的正确注意力偏置:
tensor([ 0.4803, -0.5254, -0.4293, ..., 0.0126, -0.0499, 0.0032])
tensor([ 0.0092, -0.1241, -0.2280, ..., 0.0404, 0.0494, -0.0038])
tensor([-0.0541, -0.0644, 0.0311, ..., 0.0015, -0.0427, 0.0059])
tensor([-0.2251, -0.0644, 0.0223, ..., 0.0205, -0.0017, -0.0044])
tensor([-0.0302, 0.1053, 0.1579, ..., -0.0185, -0.0097, 0.0927])
tensor([-0.0436, 0.0295, 0.0850, ..., 0.0089, -0.0007, 0.0082])
tensor([ 0.0380, 0.1714, -0.1409, ..., -0.0441, 0.0544, 0.0041])
tensor([ 0.3779, 0.0767, 0.0019, ..., 0.0123, -0.0721, 0.0015])
tensor([-0.0167, -0.3909, -0.1419, ..., 0.0212, 0.0140, 0.0999])
tensor([ 0.0571, 0.0355, -0.0991, ..., 0.0075, 0.0219, -0.0241])
tensor([-0.0301, 0.1360, -0.3842, ..., -0.0599, 0.1059, 0.0276])
tensor([-0.2222, 0.0549, 0.0331, ..., -0.0289, -0.0241, 0.0063])
你可能会问,到底发生了什么?你怎么可能凭空放入错误的偏置?我自然去查看了原始GPT2 state_dict中的所有偏置张量 - 我显然是将偏置与键匹配错了。当我发现这个c_attn偏置不对应原始权重中的任何偏置时,我很惊讶...
所以我深入研究了权重复制的问题。谁能想到呢。我试图比实际聪明,结果适得其反,一如既往。仔细看看:
我的过滤:
sd_keys_hf = [k for k in sd_keys_hf if "attn.bias" not in k and "attn.masked_bias" not in k]
正确的过滤:
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.masked_bias')]
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.bias')]
我的.c_attn.bias只是随机初始化的,因为我过滤掉了额外的键。
如何修复?
"attn.bias" -> ".attn.bias"
或者就听从比你聪明的人的建议,不要像我想的那样走捷径。此外,永远不要认为LLM的调试是理所当然的。
MPS在推理时比CPU慢,但在训练时快约4倍...嗯...
我会弄清楚这个问题的。
MPS上的Torch编译问题
未找到OpenMP支持。请尝试以下解决方案之一:
(1) 将`CXX`环境变量设置为除Apple clang++/g++以外的具有内置OpenMP支持的编译器;
(2) 通过conda安装OpenMP:`conda install llvm-openmp`;
(3) 通过brew安装libomp:`brew install libomp`;
(4) 手动设置OpenMP并将`OMP_PREFIX`环境变量设置为包含`include/omp.h`的路径。
我尝试了第1种方法,结果问题消失了,但现在编译似乎卡住了。程序无响应。
等等,也许只是真的很慢?中断两次,打印了不同的调用。
好吧,算了 - 在我现在正在写这个的M系列MBP上不工作的是autocast(或者可能真的很慢),另外当设备是cpu时torch.compile可以工作,但会增加批处理运行时间,所以现在不要费心去做。











