
 访问官网
访问官网 Github
Github Huggingface
Huggingfacekoboldcpp
KoboldCpp是一款易于使用的AI文本生成软件,适用于GGML和GGUF模型,灵感来自原版KoboldAI。它是Concedo开发的单一自包含可分发程序,基于llama.cpp构建,并添加了多功能的KoboldAI API端点、额外格式支持、Stable Diffusion图像生成、语音转文本、向后兼容性,以及一个精美的用户界面,包含持久化故事、编辑工具、保存格式、记忆、世界信息、作者注释、角色、场景等KoboldAI和KoboldAI Lite提供的所有功能。
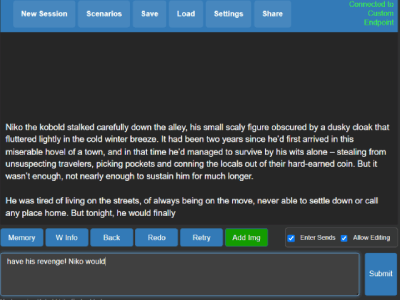
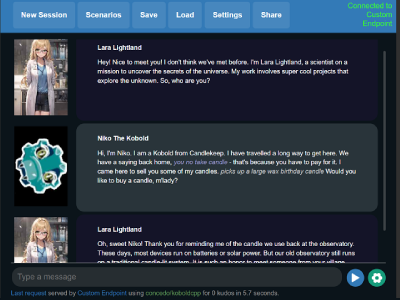
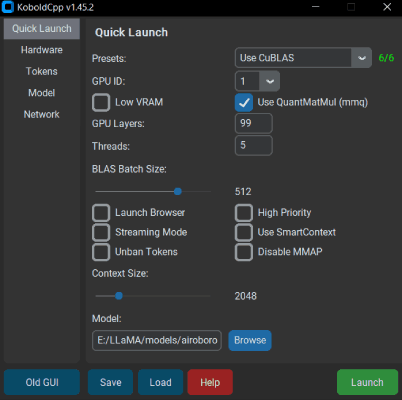
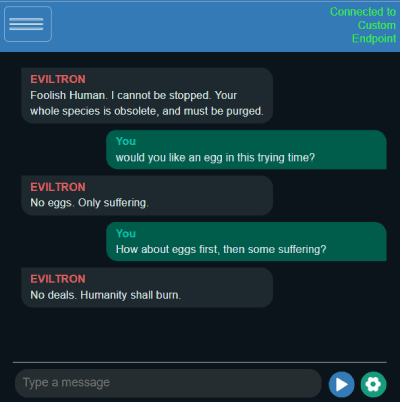
Windows使用方法(预编译二进制文件,推荐)
- Windows二进制文件以koboldcpp.exe的形式提供,这是一个包含所有必要文件的pyinstaller包装器。在此下载最新的koboldcpp.exe版本
- 运行时,只需执行koboldcpp.exe。
- 不带命令行参数启动时会显示一个包含可配置设置子集的GUI。通常您只需更改
预设和GPU层数即可。阅读--help以获取有关每个设置的更多信息。 - 默认情况下,您可以连接到http://localhost:5001
- 您也可以使用命令行运行它。有关信息,请查看
koboldcpp.exe --help
Linux使用方法(预编译二进制文件,推荐)
在现代Linux系统上,您应该在**发布页面**下载koboldcpp-linux-x64-cuda1150预构建的PyInstaller二进制文件。只需下载并运行该二进制文件即可。
或者,您也可以通过在终端中运行以下命令将koboldcpp安装到当前目录:
curl -fLo koboldcpp https://github.com/LostRuins/koboldcpp/releases/latest/download/koboldcpp-linux-x64-cuda1150 && chmod +x koboldcpp
运行此命令后,您可以使用终端中的./koboldcpp从当前目录启动Koboldcpp(对于CLI用法,请使用--help运行)。
在Colab上运行
- KoboldCpp现在有一个官方Colab GPU笔记本!这是一个无需安装任何东西就能在一两分钟内轻松入门的方法。在此尝试!
- 请注意,KoboldCpp不对您使用此Colab笔记本负责,您应确保自己的使用符合Google Colab的使用条款。
在RunPod上运行
- KoboldCpp现在可以在RunPod云GPU上使用!这是一个无需安装任何东西就能在一两分钟内轻松入门的方法,并且非常可扩展,能够以合理的成本运行70B+模型。在此尝试我们的RunPod镜像!
Docker
- 官方docker可在https://hub.docker.com/r/koboldai/koboldcpp找到
- 如果您正在构建自己的docker,请记得设置CUDA_DOCKER_ARCH或启用LLAMA_PORTABLE
MacOS
- 您需要克隆仓库并从源代码编译,请参阅下面的MacOS编译说明。
获取GGUF模型
- KoboldCpp使用GGUF模型。这里不包含模型,但您可以从其他地方下载GGUF文件,例如TheBloke的Huggingface。在huggingface.co上搜索"GGUF"可以找到大量兼容的
.gguf格式模型。 - 对于初学者,我们推荐Airoboros Mistral或Tiefighter 13B(更大的模型)。
- 或者,您可以在此下载工具自行将模型转换为GGUF格式。运行
convert-hf-to-gguf.py进行转换,然后运行quantize_gguf.exe对结果进行量化。
提高性能
- GPU加速:如果您使用带有Nvidia GPU的Windows,可以使用
--usecublas标志(仅限Nvidia)或--usevulkan(任何GPU)获得开箱即用的CUDA支持,请确保选择正确的带有CUDA支持的.exe。 - GPU层卸载:添加
--gpulayers将模型层卸载到GPU。卸载到VRAM的层数越多,生成速度就越快。实验以确定要卸载的层数,如果内存不足,请减少几层。 - 增加上下文大小:使用
--contextsize(数字)增加上下文大小,允许模型读取更多文本。请注意,您可能还需要在KoboldAI Lite UI中增加最大上下文(单击并编辑数字文本字段)。 - 旧CPU兼容性:如果遇到崩溃或问题,可以尝试使用
--noblas标志关闭BLAS。您还可以尝试使用--noavx2在非avx2兼容模式下运行。最后,您可以尝试使用--nommap关闭mmap。
欲了解更多信息,请务必使用--help标志运行程序,或**查看wiki**。
从源代码编译KoboldCpp
在 Linux 上编译(使用 koboldcpp.sh 自动编译脚本)
当无法直接使用预编译二进制文件时,我们提供了一个自动构建脚本,该脚本使用 conda 获取所有依赖项,并从源代码生成一个可直接使用的 pyinstaller 二进制文件供 Linux 用户使用。
- 使用
git clone https://github.com/LostRuins/koboldcpp.git克隆仓库 - 只需执行构建脚本
./koboldcpp.sh dist并运行生成的二进制文件。(不推荐已有 conda 安装的系统使用。依赖项:curl, bzip2)
./koboldcpp.sh # 启动 GUI 进行简单配置和启动(需要 X11)。
./koboldcpp.sh --help # 列出所有可用的终端命令,您可以像使用 Python 脚本和二进制文件一样使用 koboldcpp.sh。
./koboldcpp.sh rebuild # 自动生成新的 conda 运行时并编译库的新副本。在更新 Koboldcpp 后执行此操作以保持功能正常。
./koboldcpp.sh dist # 生成您自己的预编译二进制文件(由于 Linux 编译的特性,这些只能在等于或新于您自己的发行版上工作。)
在 Linux 上编译(手动方法)
- 要从源代码编译二进制文件,使用
git clone https://github.com/LostRuins/koboldcpp.git克隆仓库 - 提供了 makefile,只需运行
make。 - 可选 OpenBLAS:使用
make LLAMA_OPENBLAS=1手动链接您自己安装的 OpenBLAS - 可选 CLBlast:使用
make LLAMA_CLBLAST=1手动链接您自己安装的 CLBlast - 注意:对于这些,您需要获取并链接 OpenCL 和 CLBlast 库。
- 对于 Arch Linux:安装
cblasopenblas和clblast。 - 对于 Debian:安装
libclblast-dev和libopenblas-dev。
- 对于 Arch Linux:安装
- 您可以尝试使用
LLAMA_CUBLAS=1(或 AMD 的LLAMA_HIPBLAS=1)进行 CuBLAS 构建。您需要安装 CUDA Toolkit。有些人也报告使用 CMake 文件成功,不过那主要是针对 Windows。 - 要进行全功能构建(所有后端),执行
make LLAMA_OPENBLAS=1 LLAMA_CLBLAST=1 LLAMA_CUBLAS=1 LLAMA_VULKAN=1。(注意,LLAMA_CUBLAS=1在 Windows 上不起作用,您需要 Visual Studio) - 构建完所有二进制文件后,您可以使用命令
koboldcpp.py [ggml_model.gguf] [port]运行 Python 脚本
在 Windows 上编译
- 我们鼓励您使用发布的 .exe 文件,但如果您想在 Windows 上从源代码编译二进制文件,最简单的方法是:
- 获取最新版本的 w64devkit(https://github.com/skeeto/w64devkit)。确保使用"vanilla"版本,而不是 i686 或其他不同的版本。如果尝试其他版本,它们会与预编译库冲突!
- 使用
git clone https://github.com/LostRuins/koboldcpp.git克隆仓库 - 确保您使用的是 w64devkit 集成终端,然后在 KoboldCpp 源文件夹中运行
make。这将创建 .dll 文件。 - 如果您想生成 .exe 文件,确保已通过 pip 安装 PyInstaller Python 模块(
pip install PyInstaller)。然后运行脚本make_pyinstaller.bat - koboldcpp.exe 文件将位于 dist 文件夹中。
- 使用 CUDA 构建:需要 Visual Studio、CMake 和 CUDA Toolkit。克隆仓库,然后在 Visual Studio 中打开 CMake 文件并编译。将生成的
koboldcpp_cublas.dll复制到与koboldcpp.py文件相同的目录中。如果您正在打包可执行文件,可能需要包含 CUDA 动态库(如cublasLt64_11.dll和cublas64_11.dll),以确保可执行文件在不同的 PC 上正常工作。 - 替换库(不推荐):如果您希望使用自己版本的其他 Windows 库(OpenCL、CLBlast 和 OpenBLAS),可以这样做:
- OpenCL - 测试用 https://github.com/KhronosGroup/OpenCL-SDK 。如果您希望编译它,请按照仓库说明进行操作。您需要 vcpkg。
- CLBlast - 测试用 https://github.com/CNugteren/CLBlast 。如果您希望编译它,需要引用 OpenCL 文件。只有使用 MSVC 编译才会生成 ".lib" 文件。
- OpenBLAS - 测试用 https://github.com/xianyi/OpenBLAS 。
- 将相应的 .lib 文件移动到项目的 /lib 文件夹,覆盖旧文件。
- 同时,替换项目目录根目录中现有版本的相应 .dll 文件(如 libopenblas.dll)。
- 按照上述说明构建 KoboldCpp 项目。
在 MacOS 上编译
- 您可以从源代码编译二进制文件。您可以使用
git clone https://github.com/LostRuins/koboldcpp.git克隆仓库 - 提供了 makefile,只需运行
make。 - 如果您想要 Metal GPU 支持,请运行
make LLAMA_METAL=1,注意需要安装 MacOS metal 库。 - 构建完所有二进制文件后,您可以使用命令
koboldcpp.py --model [ggml_model.gguf]运行 Python 脚本(如果希望将层卸载到 GPU,请添加--gpulayers (层数))。
在 Android 上编译(Termux 安装)
- 从 F-Droid 安装并运行 Termux
- 输入命令
termux-change-repo并选择Mirror by BFSU - 使用
pkg install wget git python安装依赖项(以及任何其他缺失的包) - 安装依赖项
apt install openssl(如果需要) - 克隆仓库
git clone https://github.com/LostRuins/koboldcpp.git - 导航到 koboldcpp 文件夹
cd koboldcpp - 构建项目
make - 获取一个小型 GGUF 模型,例如
wget https://huggingface.co/concedo/KobbleTinyV2-1.1B-GGUF/resolve/main/KobbleTiny-Q4_K.gguf - 启动 Python 服务器
python koboldcpp.py --model KobbleTiny-Q4_K.gguf - 在移动浏览器中连接到
http://localhost:5001 - 如果遇到任何错误,请确保使用
pkg up更新您的包 - Termux 的 GPU 加速可能是可行的,但我尚未探索。如果您找到一个适用于多设备的好解决方案,请分享或提交 PR。
AMD 用户
第三方资源
- 这些非官方资源由社区贡献,可能已过时或未维护。不会提供官方支持!
- Arch Linux 软件包:CUBLAS 和 HIPBLAS。
- 非官方 Docker:korewaChino 和 noneabove1182
- Nix & NixOS:KoboldCpp 已在 Nixpkgs 上提供,只需将
koboldcpp添加到您的environment.systemPackages中即可安装。- 请确保将
nixpkgs.config.allowUnfree、hardware.opengl.enable(如果使用不稳定版本则为hardware.graphics.enable)和nixpkgs.config.cudaSupport设置为true以启用 CUDA。 - macOS 默认启用 Metal,Linux 和 macOS 默认启用 Vulkan 支持,ROCm 支持尚未提供。
- 您还可以使用
nix3-run运行 KoboldCpp:nix run --expr ``with import <nixpkgs> { config = { allowUnfree = true; cudaSupport = true; }; }; koboldcpp`` --impure - 或使用
nix-shell:nix-shell --expr 'with import <nixpkgs> { config = { allowUnfree = true; cudaSupport = true; }; }; koboldcpp' --run "koboldcpp" --impure - 可以覆盖软件包(如 OpenBlast、CLBLast、Vulkan 等),请参阅 Nix Pills 第 17 章 - Nixpkgs 覆盖软件包
- 请确保将
问题和帮助维基
- 首先,请查看 KoboldCpp 常见问题解答和知识库,可能已经有您问题的答案!另外请搜索以往的问题和讨论。
- 如果找不到答案,请在此 GitHub 上提出问题,或在 KoboldAI Discord 上与我们联系。
KoboldCpp 和 KoboldAI API 文档
KoboldCpp 公开演示
注意事项
- Windows:无需安装,单文件可执行程序(开箱即用)
- 自 v1.0.6 起,需要 libopenblas,本仓库中包含预编译的 Windows 二进制文件。如果找不到,将回退到不使用 BLAS 的模式。
- 自 v1.15 起,如果启用则需要 CLBlast,本仓库中包含预编译的 Windows 二进制文件。如果找不到,将回退到不使用 CLBlast 的模式。
- 自 v1.33 起,您可以将上下文大小设置为超过模型官方支持的大小。这会增加困惑度,但在 4096 以下应该仍能在未调优的模型上良好工作。(适用于 GPT-NeoX、GPT-J 和 Llama 模型)使用
--ropeconfig自定义。 - 自 v1.42 起,支持 LLAMA 和 Falcon 的 GGUF 模型
- 自 v1.55 起,Linux 上的 lcuda 路径是硬编码的,如果不使用 koboldcpp.sh 进行编译,可能需要手动更改 makefile。
- 自 v1.60 起,提供使用 StableDiffusion.cpp 的原生图像生成功能,您可以加载任何 SD1.5 或 SDXL .safetensors 模型,它将提供兼容 A1111 的 API 供使用。
- 我尽量保持与所有过去的 llama.cpp 模型的向后兼容性。但为获得最佳结果,也鼓励您尽可能重新转换/更新您的模型。
许可证
- 原始 GGML 库和 ggerganov 的 llama.cpp 采用 MIT 许可证
- 然而,KoboldAI Lite 采用 AGPL v3.0 许可证
- KoboldCpp 代码和其他文件也采用 AGPL v3.0 许可证,除非另有说明
注释
- 如果您愿意,在使用
make构建 koboldcpp 库后,可以使用make_pyinstaller.bat通过 pyinstaller 自行重新构建可执行文件 - API 文档可在
/api(例如http://localhost:5001/api)和 https://lite.koboldai.net/koboldcpp_api 获取。在/v1路由(例如http://localhost:5001/v1)也提供了兼容 OpenAI 的 API。 - 支持所有最新的 GGUF 模型,KoboldCpp 还包括对旧版本/传统 GGML
.bin模型的向后兼容性,但某些较新的功能可能不可用。 - 列出了不完整的模型和架构列表,但还有数百个其他 GGUF 模型。通常,如果是 GGUF 格式,就应该能正常工作。
- Llama / Llama2 / Llama3 / Alpaca / GPT4All / Vicuna / Koala / Pygmalion / Metharme / WizardLM
- Mistral / Mixtral / Miqu
- Qwen / Qwen2 / Yi
- Gemma / Gemma2
- GPT-2 / Cerebras
- Phi-2 / Phi-3
- GPT-NeoX / Pythia / StableLM / Dolly / RedPajama
- GPT-J / RWKV4 / MPT / Falcon / Starcoder / Deepseek 等等
- Stable Diffusion 1.5 和 SDXL safetensor 模型
- 基于 LLaVA 的视觉模型和多模态投影器(mmproj)
- 用于语音转文本的 Whisper 模型











