
 Github
Github 论文
论文摘要
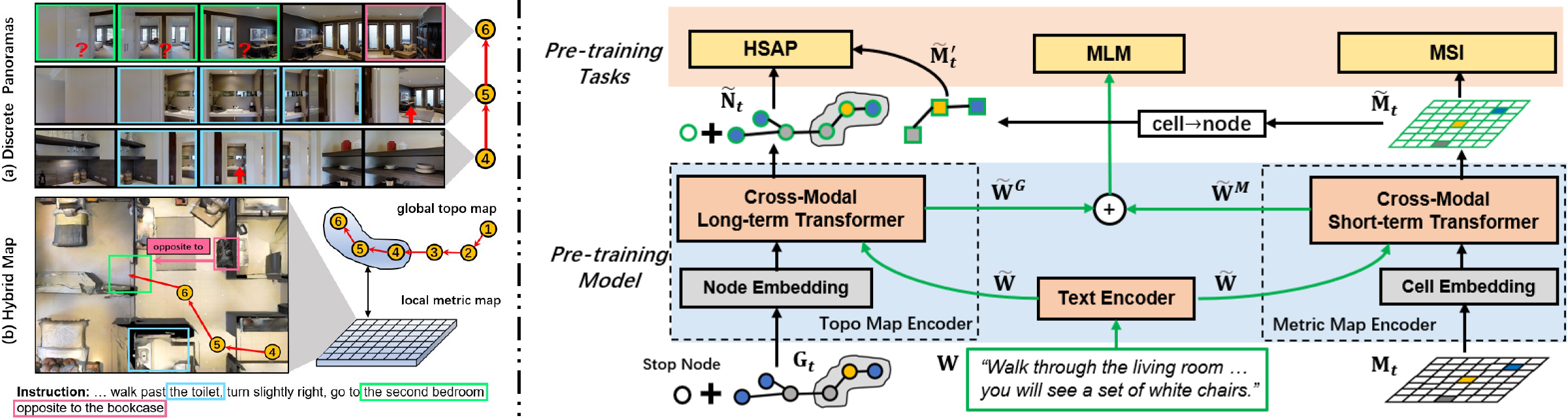
大规模预训练在视觉语言导航(VLN)任务中展现了令人瞩目的成果。然而,大多数现有的预训练方法采用离散全景图来学习视觉-文本关联。这要求模型隐式地关联全景图中不完整、重复的观察,可能会损害代理的空间理解能力。因此,我们提出了一种新的基于地图的预训练范式,专为VLN设计,具有空间感知能力。具体而言,我们构建了一个局部度量地图,明确地聚合不完整的观察并去除重复,同时在全局拓扑地图中建模导航依赖关系。这种混合设计可以平衡VLN对短期推理和长期规划的需求。然后,基于这种混合地图,我们设计了一个预训练框架来学习多模态地图表示,增强了空间感知的跨模态推理能力,从而促进语言引导的导航目标。大量实验证明了基于地图的预训练路线对VLN的有效性,所提出的方法在四个VLN基准测试(R2R、R2R-CE、RxR、REVERIE)中达到了最先进水平。
方法
待办事项
- 发布VLN(R2R、RxR、REVERIE)代码。
- 发布VLN-CE(R2R-CE)代码。
- 数据预处理代码。
- 发布检查点和预处理数据集。
设置
安装
-
创建虚拟环境。我们使用Python 3.6开发此项目。
conda env create -f environment.yaml -
安装最新版本的Matterport3DSimulator,包括Matterport3D RGBD数据集(用于第6步)。
-
下载Matterport3D场景网格。必须从Matterport3D项目网页获取
download_mp.py。download_mp.py也用于在第2步下载RGBD数据集。
# 使用python 2.7运行
python download_mp.py --task habitat -o data/scene_datasets/mp3d/
# 解压到:./data/scene_datasets/mp3d/{scene}/{scene}.glb
按照Habitat安装指南安装habitat-sim和habitat-lab。我们在实验中使用v0.1.7版本。简而言之:
-
为具有多个GPU或没有连接显示器的机器(如集群)安装
habitat-sim:conda install -c aihabitat -c conda-forge habitat-sim=0.1.7 headless -
从GitHub仓库克隆
habitat-lab并安装。以下命令将安装Habitat Lab的核心以及habitat_baselines。git clone --branch v0.1.7 git@github.com:facebookresearch/habitat-lab.git cd habitat-lab python setup.py develop --all # 安装habitat和habitat_baselines -
用于度量地图的网格特征预处理(约100G)。
# 适用于R2R、RxR、REVERIE python precompute_features/grid_mp3d_clip.py python precompute_features/grid_mp3d_imagenet.py python precompute_features/grid_depth.py python precompute_features/grid_sem.py
R2R-CE 预训练
python precompute_features/grid_habitat_clip.py python precompute_features/save_habitat_img.py --img_type depth python precompute_features/save_depth_feature.py
7. 下载预处理的指令数据集和训练好的权重[[链接]](https://drive.google.com/file/d/1jYg_dMlCDZoOtrkmmq40k-_-m6xerdUI/view?usp=sharing)。目录结构已经整理好。对于R2R-CE实验,按照[ETPNav](https://github.com/MarSaKi/ETPNav)的方法在`bevbert_ce/data`文件夹中配置VLN-CE数据集,并将训练好的CE权重[[链接]](https://drive.google.com/file/d/1-2u1NWmwpX09Rg7uT5mABo-CBTsLthGm/view?usp=sharing)放入`bevbert_ce/ckpt`。
祝你使用BEVBert进行VLN之旅顺利!
## 运行
预训练。下载预计算的图像特征[[链接]](https://drive.google.com/file/d/1S8jD1Mln0mbTsB5I_i2jdQ8xBbnw-Dyr/view?usp=sharing)到`img_features`文件夹。
CUDA_VISIBLE_DEVICES=0,1,2,3 bash scripts/pt_r2r.bash 2333 # R2R CUDA_VISIBLE_DEVICES=0,1,2,3 bash scripts/pt_rxr.bash 2333 # RxR CUDA_VISIBLE_DEVICES=0,1,2,3 bash scripts/pt_rvr.bash 2333 # REVERIE
cd bevbert_ce/pretrain CUDA_VISIBLE_DEVICES=0,1,2,3 bash run_pt/run_r2r.bash 2333 # R2R-CE
微调和测试,训练好的权重可以在步骤7中找到。
CUDA_VISIBLE_DEVICES=0,1,2,3 bash scripts/ft_r2r.bash 2333 # R2R CUDA_VISIBLE_DEVICES=0,1,2,3 bash scripts/ft_rxr.bash 2333 # RxR CUDA_VISIBLE_DEVICES=0,1,2,3 bash scripts/ft_rvr.bash 2333 # REVERIE
cd bevbert_ce CUDA_VISIBLE_DEVICES=0,1,2,3 bash run_r2r/main.bash [train/eval/infer] 2333 # R2R-CE
# 联系方式
* dong DOT an AT cripac DOT ia DOT ac DOT cn, [安东](https://marsaki.github.io/)
* yhuang AT nlpr DOT ia DOT ac DOT cn, [黄岩](https://yanrockhuang.github.io/)
# 致谢
我们的实现部分受到了[DUET](https://github.com/cshizhe/VLN-DUET)、[S-MapNet](https://github.com/vincentcartillier/Semantic-MapNet)和[ETPNav](https://github.com/MarSaKi/ETPNav)的启发。
感谢他们开源了这些出色的工作!
# 引用
如果您觉得这个仓库有用,请考虑引用我们的论文:
@article{an2023bevbert, title={BEVBert: Multimodal Map Pre-training for Language-guided Navigation}, author={An, Dong and Qi, Yuankai and Li, Yangguang and Huang, Yan and Wang, Liang and Tan, Tieniu and Shao, Jing}, journal={Proceedings of the IEEE/CVF International Conference on Computer Vision}, year={2023} }











