
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档Functionary
Functionary 是一个能够解释和执行函数/插件的语言模型。
该模型可以决定何时执行函数,是并行还是串行执行,并且能够理解它们的输出。它只在需要时触发函数。函数定义以 JSON Schema 对象的形式给出,类似于 OpenAI GPT 函数调用。
文档和更多示例:functionary.meetkai.com
更新日志:(点击展开)
- [2024-08-11] 我们最新的模型(meetkai/functionary-medium-v3.1)在伯克利函数调用排行榜中排名第二
- [2024/08/08] 我们发布了基于 meta-llama/Meta-Llama-3.1-70B-Instruct 的 128k 上下文长度 70B 模型:meetkai/functionary-medium-v3.1
- [2024/08/07] 我们发布了两个基于 meta-llama/Meta-Llama-3.1-8B-Instruct 的 128k 上下文长度模型:
- meetkai/functionary-small-v3.1:使用 Meta 的原始提示模板,如用户自定义自定义工具调用中所述
- meetkai/functionary-small-v3.2:使用我们自己的提示模板。这个模型比 meetkai/functionary-small-v3.1 更好
- [2024/06/14] 我们发布了 meetkai/functionary-medium-v3.0(基于 meta-llama/Meta-Llama-3-70B-Instruct),具有更好的函数调用能力
- [2024/05/17] 我们发布了 meetkai/functionary-small-v2.5,与 functionary-small-v2.4 相比,具有更好的函数调用和代码解释器能力
- [2024/05/06] functionary v2 到 v2.4 模型的流式支持在 llama-cpp-python 中发布!
- [2024/05/03] 在 Modal.com 上添加了对无服务器 vLLM 部署的支持
- [2024/04/27] 新的改进的语法采样!确保生成函数名称、提示模板和参数的 100% 准确性
- [2024/04/02] 我们发布了 meetkai/functionary-small-v2.4 和 meetkai/functionary-medium-v2.4!这是第一批具有代码解释器能力的 functionary 模型(通过在工具中传入
{type: "code_interpreter"})!
设置
要安装所需的依赖项,请运行:
pip install -r requirements.txt
小型模型:
python3 server_vllm.py --model "meetkai/functionary-small-v3.2" --host 0.0.0.0 --max-model-len 8192
中型模型:
我们的中型模型需要:4xA6000 或 2xA100 80GB 来运行,需要使用:tensor-parallel-size
# vllm 要求首先运行这个:https://github.com/vllm-project/vllm/issues/6152
export VLLM_WORKER_MULTIPROC_METHOD=spawn
python server_vllm.py --model "meetkai/functionary-medium-v3.1" --max-model-len 8192 --tensor-parallel-size 2
语法采样
我们还提供了自己的函数调用语法采样功能,它限制了 LLM 的生成始终遵循提示模板,并确保函数名称 100% 准确。参数使用高效的 lm-format-enforcer 生成,确保参数遵循所调用工具的模式。要启用语法采样,请使用命令行参数 --enable-grammar-sampling 运行 vLLM 服务器:
python3 server_vllm.py --model "meetkai/functionary-medium-v3.1" --max-model-len 8192 --tensor-parallel-size 2 --enable-grammar-sampling
注意:
- 语法采样支持仅适用于 V2 和 V3.0 模型。V1 和 V3.1 模型没有此类支持。
- 我们的 vLLM 服务器仅在启用语法采样时支持 OpenAI Chat Completion API 中的
tool_choice="required"功能。
文本生成推理
我们还提供了一个使用 Text-Generation-Inference(TGI)对 Functionary 模型进行推理的服务。按照以下步骤开始:
-
按照安装说明安装 Docker。
-
安装 Python 的 Docker SDK
pip install docker
- 启动 Functionary TGI 服务器
在启动时,Functionary TGI 服务器尝试连接到现有的 TGI 端点。在这种情况下,你可以运行以下命令:
python3 server_tgi.py --model <远程模型ID或本地模型路径> --endpoint <TGI服务端点>
如果 TGI 端点不存在,Functionary TGI 服务器将通过安装的 Docker Python SDK 使用 endpoint CLI 参数中提供的地址启动一个新的 TGI 端点容器。分别为远程和本地模型运行以下命令:
python3 server_tgi.py --model <远程模型ID> --remote_model_save_folder <保存和缓存远程模型的路径> --endpoint <TGI服务端点>
python3 server_tgi.py --model <本地模型路径> --endpoint <TGI服务端点>
Docker
如果你在依赖项方面遇到问题,并且你有 nvidia-container-toolkit, 你可以这样启动你的环境:
sudo docker run --gpus all -it --ipc=host --name functionary -v ${PWD}/functionary_workspace:/workspace -p 8000:8000 nvcr.io/nvidia/pytorch:23.10-py3
OpenAI 兼容用法
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="functionary")
client.chat.completions.create(
model="meetkai/functionary-small-v3.2",
messages=[{"role": "user",
"content": "伊斯坦布尔的天气如何?"}
],
tools=[{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市和州,例如 San Francisco, CA"
}
},
"required": ["location"]
}
}
}],
tool_choice="auto"
)
原始用法:
详细信息(点击展开)
import requests
data = {
'model': 'meetkai/functionary-small-v3.2', # 这里的模型名称是部署时server_vllm.py或server.py中"--model"参数的值
'messages': [
{
"role": "user",
"content": "伊斯坦布尔的天气如何?"
}
],
'tools':[ # 对于functionary-7b-v2我们使用"tools";对于functionary-7b-v1.4我们使用"functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市和州,例如 旧金山, CA"
}
},
"required": ["location"]
}
}
}
]
}
response = requests.post("http://127.0.0.1:8000/v1/chat/completions", json=data, headers={
"Content-Type": "application/json",
"Authorization": "Bearer xxxx"
})
# 打印响应文本
print(response.text)
可用模型
| 模型 | 描述 | VRAM FP16 |
|---|---|---|
| functionary-small-v3.2 / GGUF | 128k上下文,代码解释器,使用我们自己的提示模板 | 24GB |
| functionary-medium-v3.1 / GGUF | 128k上下文,代码解释器,使用原始的Meta提示模板 | 160GB |
| functionary-small-v3.1 / GGUF | 128k上下文,代码解释器,使用原始的Meta提示模板 | 24GB |
| functionary-medium-v3.0 / GGUF | 8k上下文,基于 meta-llama/Meta-Llama-3-70B-Instruct | 160GB |
| functionary-small-v2.5 / GGUF | 8k上下文,代码解释器 | 24GB |
| functionary-small-v2.4 / GGUF | 8k上下文,代码解释器 | 24GB |
| functionary-medium-v2.4 / GGUF | 8k上下文,代码解释器,更高准确性 | 90GB |
| functionary-small-v2.2 / GGUF | 8k上下文 | 24GB |
| functionary-medium-v2.2 / GGUF | 8k上下文 | 90GB |
| functionary-7b-v2.1 / GGUF | 8k上下文 | 24GB |
| functionary-7b-v2 / GGUF | 支持并行函数调用 | 24GB |
| functionary-7b-v1.4 / GGUF | 4k上下文,更高准确性(已弃用) | 24GB |
| functionary-7b-v1.1 | 4k上下文(已弃用) | 24GB |
| functionary-7b-v0.1 | 2k上下文(已弃用)不推荐使用,请使用2.1及以上版本 | 24GB |
兼容性信息
- v1模型与OpenAI-python v0和v1都兼容。
- v2模型专为与OpenAI-python v1兼容而设计。
关于OpenAI-python v0和v1之间的差异,您可以参考官方文档这里
相关项目之间的差异
| 功能/项目 | Functionary | NexusRaven | Gorilla | Glaive | GPT-4-1106-preview |
|---|---|---|---|---|---|
| 单一函数调用 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 并行函数调用 | ✅ | ✅ | ✅ | ❌ | ✅ |
| 跟进缺失的函数参数 | ✅ | ❌ | ❌ | ❌ | ✅ |
| 多轮对话 | ✅ | ❌ | ❌ | ✅ | ✅ |
| 基于工具执行结果生成模型响应 | ✅ | ❌ | ❌ | ❌ | ✅ |
| 闲聊 | ✅ | ❌ | ✅ | ✅ | ✅ |
| 代码解释器 | ✅ | ❌ | ❌ | ❌ | ✅ |
您可以在这里找到更多关于这些功能的详细信息
Llama.cpp 推理
使用Huggingface Tokenizer的Llama.cpp推理
使用LLama-cpp-python进行推理的示例可以在这里找到:llama_cpp_inference.py。
集成到Llama-cpp
此外,functionary也被集成到了LLama-cpp-python中,但集成可能不会快速更新,所以如果结果有问题或奇怪,请使用:llama_cpp_inference.py。目前,v2.5还没有被集成,所以如果您使用的是functionary-small-v2.5-GGUF,请使用:llama_cpp_inference.py
确保最新版本的llama-cpp-python已成功安装在您的系统中。Functionary v2已完全集成到llama-cpp-python中。您可以通过正常的聊天补全或通过llama-cpp-python的OpenAI兼容服务器(其行为类似于我们的服务器)使用Functionary的GGUF模型进行推理。
以下是使用正常聊天补全的示例代码:
from llama_cpp import Llama
from llama_cpp.llama_tokenizer import LlamaHFTokenizer
# 我们应该使用HF AutoTokenizer而不是llama.cpp的tokenizer,因为我们发现Llama.cpp的tokenizer给出的结果与Huggingface的不一样。原因可能是在训练中,我们向tokenizer添加了新的tokens,而Llama.cpp没有成功处理这一点
llm = Llama.from_pretrained(
repo_id="meetkai/functionary-small-v2.4-GGUF",
filename="functionary-small-v2.4.Q4_0.gguf",
chat_format="functionary-v2",
tokenizer=LlamaHFTokenizer.from_pretrained("meetkai/functionary-small-v2.4-GGUF"),
n_gpu_layers=-1
)
messages = [
{"role": "user", "content": "河内的天气怎么样?"}
]
tools = [ # 对于functionary-7b-v2我们使用"tools";对于functionary-7b-v1.4我们使用"functions" = [{"name": "get_current_weather", "description":..., "parameters": ....}]
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取当前天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市和州,例如:旧金山,加利福尼亚州"
}
},
"required": ["location"]
}
}
}
]
result = llm.create_chat_completion(
messages = messages,
tools=tools,
tool_choice="auto",
)
print(result["choices"][0]["message"])
输出结果将会是:
{'role': 'assistant', 'content': None, 'tool_calls': [{'type': 'function', 'function': {'name': 'get_current_weather', 'arguments': '{\n "location": "Hanoi"\n}'}}]}
更多详细信息,请参阅llama-cpp-python中的函数调用部分。要使用llama-cpp-python的OpenAI兼容服务器来使用我们的Functionary GGUF模型,请参阅此处获取更多详细信息和文档。
注意:
- 对于llama-cpp-python中的Functionary,默认系统消息会在API调用期间自动添加。因此,无需在
messages中提供默认系统消息。 - 从v0.2.70版本开始,Functionary模型在普通聊天补全和llama-cpp-python的OpenAI兼容服务器中的流式传输功能得到了官方支持。
调用真实的Python函数
要调用真实的Python函数,获取结果并提取结果进行回应,你可以使用chatlab。以下示例使用的是chatlab==0.16.0:
请注意,Chatlab目前不支持并行函数调用。此示例代码仅与Functionary版本1.4兼容,可能无法与Functionary版本2.0正常工作。
from chatlab import Conversation
import openai
import os
openai.api_key = "functionary" # 我们只需要将其设置为非None的值
os.environ['OPENAI_API_KEY'] = "functionary" # chatlab要求我们也设置这个
openai.api_base = "http://localhost:8000/v1"
# 现在提供带有描述的函数
def get_car_price(car_name: str):
"""这个函数用于根据给定的名称获取汽车价格
:param car_name: 要获取价格的汽车名称
"""
car_price = {
"tang": {"price": "$20000"},
"song": {"price": "$25000"}
}
for key in car_price:
if key in car_name.lower():
return {"price": car_price[key]}
return {"price": "unknown"}
chat = Conversation(model="meetkai/functionary-7b-v2")
chat.register(get_car_price) # 注册这个函数
chat.submit("名为Tang的汽车价格是多少?") # 提交用户问题
# 打印流程
for message in chat.messages:
role = message["role"].upper()
if "function_call" in message:
func_name = message["function_call"]["name"]
func_param = message["function_call"]["arguments"]
print(f"{role}: 调用函数: {func_name}, 参数:{func_param}")
else:
content = message["content"]
print(f"{role}: {content}")
输出将如下所示:
USER: 名为Tang的汽车价格是多少?
ASSISTANT: 调用函数: get_car_price, 参数:{
"car_name": "Tang"
}
FUNCTION: {'price': {'price': '$20000'}}
ASSISTANT: 名为Tang的汽车价格是20,000美元。
使用Modal.com进行无服务器部署
Functionary模型的无服务器部署可通过modal_server_vllm.py脚本实现。在注册并安装Modal后,按照以下步骤在Modal上部署我们的vLLM服务器:
- 创建开发环境
modal environment create dev
如果你已经创建了开发环境,就不需要再创建一个。只需在下一步中配置它即可。
- 配置开发环境
modal config set-environment dev
- 提供Functionary模型服务
modal serve modal_server_vllm
- 部署运行器
modal deploy modal_server_vllm
用例
以下是几个如何使用这个函数调用系统的示例:
旅游和酒店业 - 行程规划
函数plan_trip(destination: string, duration: int, interests: list)可以接收用户输入,如"我想计划一个为期7天的巴黎之行,重点是艺术和文化",并据此生成行程。
房地产 - 房产估值
类似estimate_property_value(property_details: dict)的函数可以让用户输入房产详情(如位置、面积、房间数等),并获得估计的市场价值。
电信 - 客户支持
函数parse_customer_complaint(complaint: {issue: string, frequency: string, duration: string})可以帮助从复杂的叙述性客户投诉中提取结构化信息,识别核心问题和潜在解决方案。complaint对象可以包括诸如issue(主要问题)、frequency(问题发生频率)和duration(问题持续时间)等属性。
详细信息(点击展开)
client.chat.completions.create(
model="meetkai/functionary-7b-v2",
messages=[
{"role": "user", "content": '过去一周我的网络经常断开连接'},
],
tools=[
{
"type": "function",
"function": {
"name": "parse_customer_complaint",
"description": "解析客户投诉并识别核心问题",
"parameters": {
"type": "object",
"properties": {
"complaint": {
"type": "object",
"properties": {
"issue": {
"type": "string",
"description": "主要问题",
},
"frequency": {
"type": "string",
"description": "问题发生的频率",
},
"duration": {
"type": "string",
"description": "问题持续的时间",
},
},
"required": ["issue", "frequency", "duration"],
},
},
"required": ["complaint"],
}
}
}
],
tool_choice="auto"
)
响应将包含:
{"role": "assistant", "content": null, "tool_calls": [{"type": "function", "function": {"name": "parse_customer_complaint", "arguments": '{\n "complaint": {"issue": "网络断开连接", "frequency": "经常", "duration": "过去一周"}\n}'}}]}
然后你需要使用提供的参数调用parse_customer_complaint函数。 如果你想要模型的评论,那么你需要再次调用模型,并提供函数的响应,模型将撰写必要的评论。
工作原理
我们将函数定义转换为类似TypeScript定义的文本。 然后我们将这些定义作为系统提示注入。之后,我们注入默认的系统提示。 然后我们开始对话消息。
提示示例可以在这里找到:V1(v1.4),V2(v2, v2.1, v2.2, v2.4)和V2.llama3(v2.5)
我们不改变logit概率以符合某个特定模式,但模型本身知道如何符合。这允许我们轻松使用现有的工具和缓存系统。
评估
Berkeley函数调用排行榜
我们在Berkeley函数调用排行榜中排名第二(最后更新:2024-08-11)
| 模型名称 | 函数调用准确率(名称和参数) |
|---|---|
| meetkai/functionary-medium-v3.1 | 88.88% |
| GPT-4-1106-Preview (Prompt) | 88.53% |
| meetkai/functionary-small-v3.2 | 82.82% |
| meetkai/functionary-small-v3.1 | 82.53% |
| FireFunction-v2 (FC) | 78.82.47% |
函数预测评估
在SGD数据集上评估函数调用预测。准确率指标衡量预测函数调用的整体正确性,包括函数名称预测和参数提取。
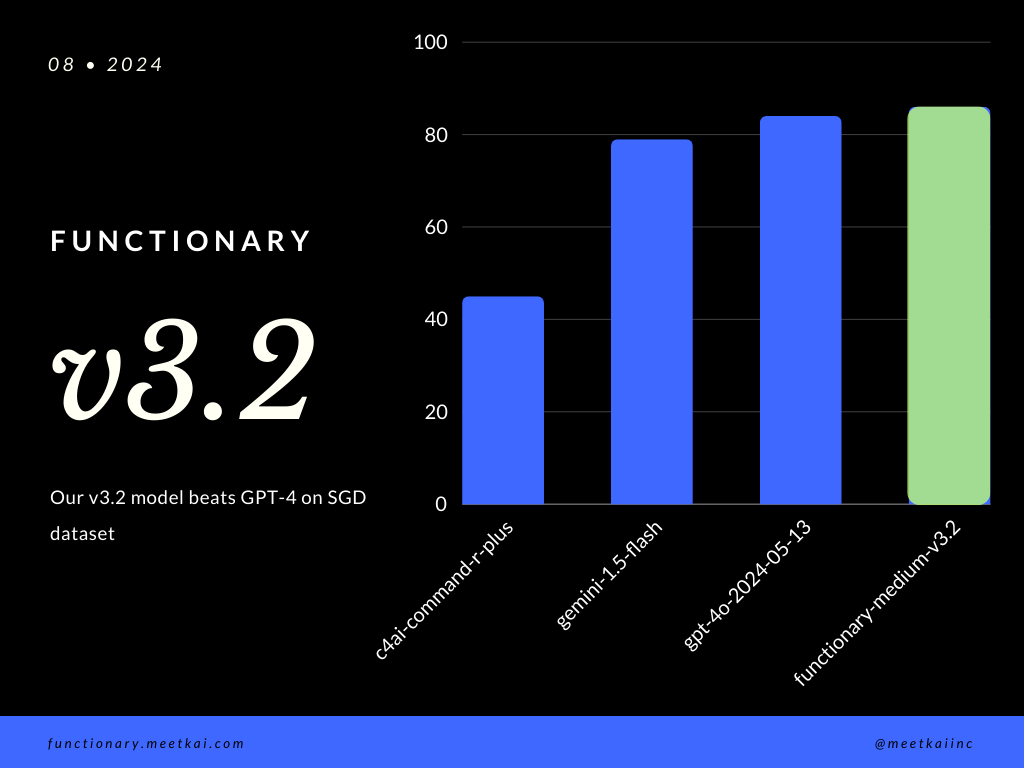
| 数据集 | 模型名称 | 函数调用准确率(名称和参数) |
|---|---|---|
| SGD | meetkai/functionary-medium-v3.1 | 88.11% |
| SGD | gpt-4o-2024-05-13 | 82.75% |
| SGD | gemini-1.5-flash | 79.64% |
| SGD | c4ai-command-r-plus | 45.66% |
训练
参见训练README
路线图
- 基于OpenAPI规范的插件支持。
- 快速推理服务器
- vLLM
- text-generation-inference ? 参见:许可问题
- 流式支持
- 服务器的function_call参数
- 语法采样以确保函数和参数名称100%准确
- 并行函数调用支持
- Python函数调用支持(自动检测类型注解并自动调用)
- 真实世界使用示例,如创建代理。
- 训练基于Mixtral的模型
- 代码解释器支持
- 请考虑为未来的请求开启PR











