
 Github
Github 文档
文档 论文
论文VoxFormer:3D语义占用预测的前沿基准

VoxFormer: 基于稀疏体素Transformer的相机3D语义场景补全, CVPR 2023.
李一鸣, 于志丁, Chris Choy, 肖超伟, Jose M. Alvarez, Sanja Fidler, 冯晨, Anima Anandkumar
新闻
- 2023/06: 🔥 我们发布了SSCBench,一个从KITTI-360、nuScenes和Waymo派生的大规模语义场景补全基准。
- [2023/03]: 🔥 VoxFormer被CVPR 2023接收为亮点论文**(235/9155, 2.5%接收率)**。
- [2022/11]: VoxFormer在SemanticKITTI 3D SSC(语义场景补全)任务上实现了最先进的性能,达到13.35% mIoU和44.15% IoU(仅使用相机)!
摘要
人类可以轻松想象被遮挡物体和场景的完整3D几何结构。这种令人向往的能力对于识别和理解至关重要。为了使AI系统具备这种能力,我们提出了VoxFormer,这是一个基于Transformer的语义场景补全框架,可以仅从2D图像输出完整的3D体素语义。我们的框架采用两阶段设计,从深度估计得到的可见和被占用体素查询的稀疏集合开始,然后是一个将稀疏体素生成密集3D体素的密化阶段。这种设计的关键思想是2D图像上的视觉特征仅对应于可见的场景结构,而不是被遮挡或空白的空间。因此,从可见结构的特征化和预测开始更为可靠。一旦我们获得稀疏查询集,我们应用掩码自编码器设计通过自注意力将信息传播到所有体素。在SemanticKITTI上的实验表明,VoxFormer在几何和语义方面分别相对提高了20.0%和18.1%,并将训练时的GPU内存减少了约45%,降至不到16GB。
方法
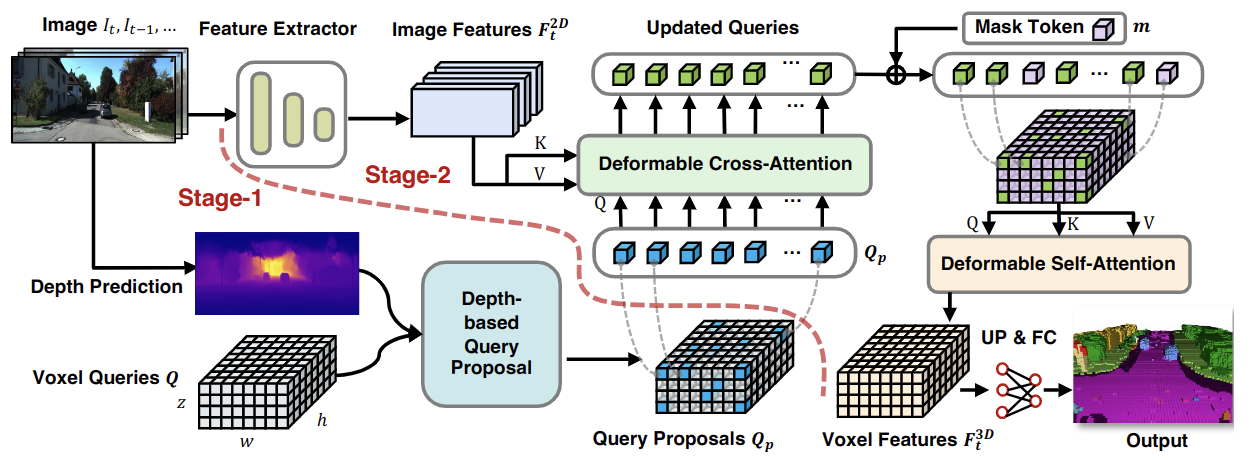 |
|---|
| 图1. VoxFormer的整体框架。给定RGB图像,通过ResNet50提取2D特征,并通过现成的深度预测器估计深度。经过校正的估计深度实现了类别无关的查询提议阶段:位于被占用位置的查询将被选择与图像特征进行可变形交叉注意力。之后,将添加掩码标记以通过可变形自注意力完成体素特征。精炼后的体素特征将被上采样并投影到输出空间以进行每个体素的语义分割。请注意,我们的框架支持单张或多张图像输入。 |
入门指南
- [安装](https://github.com/NVlabs/VoxFormer/blob/main/docs/install.md
- [准备数据集](https://github.com/NVlabs/VoxFormer/blob/main/docs/prepare_dataset.md
- [运行和评估](https://github.com/NVlabs/VoxFormer/blob/main/docs/getting_started.md
模型库
第一阶段的查询提议网络(QPN)可在此处获得。 对于第二阶段,请根据下表下载训练好的模型。
| 主干网络 | 方法 | 学习率调度 | IoU | mIoU | 配置 | 下载 |
|---|---|---|---|---|---|---|
| R50 | VoxFormer-T | 20轮 | 44.15 | 13.35 | 配置文件 | 模型 |
| R50 | VoxFormer-S | 20轮 | 44.02 | 12.35 | 配置文件 | 模型 |
| R50 | VoxFormer-T-3D | 20轮 | 44.35 | 13.69 | 配置文件 | 模型 |
| R50 | VoxFormer-S-3D | 20轮 | 44.42 | 12.86 | 配置文件 | 模型 |
数据集
- SemanticKITTI
- KITTI-360
- nuScenes
引用
如果这项工作对您的研究有帮助,请引用以下BibTeX条目。
@InProceedings{li2023voxformer,
title={VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion},
author={Li, Yiming and Yu, Zhiding and Choy, Christopher and Xiao, Chaowei and Alvarez, Jose M and Fidler, Sanja and Feng, Chen and Anandkumar, Anima},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2023}
}
许可证
版权所有 © 2022-2023,NVIDIA Corporation及其附属公司。保留所有权利。
本作品根据Nvidia Source Code License-NC提供。点击此处查看此许可证的副本。
预训练模型根据CC-BY-NC-SA-4.0共享。如果您对材料进行重新混合、转换或基于材料进行创作,您必须在相同的许可条款下分发您的贡献。
对于商业咨询,请访问我们的网站并提交表单:NVIDIA研究许可。
星标历史
致谢
非常感谢以下优秀的开源项目:











