
Prismer


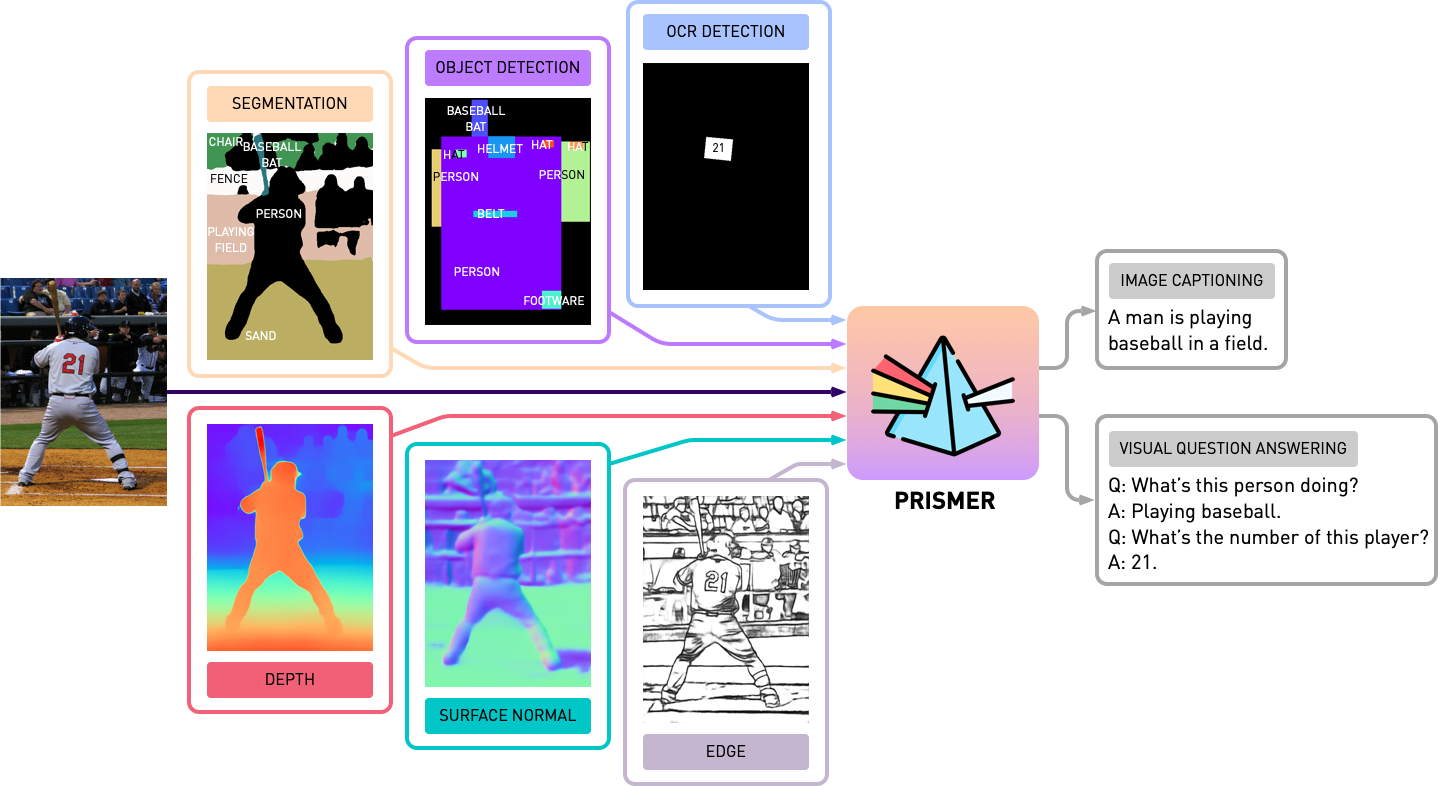
本仓库包含论文《Prismer: A Vision-Language Model with Multi-Task Experts》中的 Prismer 和 PrismerZ 的源代码。可以在 HuggingFace Space 查看我们的官方演示,以及在 Replicate 查看第三方演示。
更新日志
- 2023年4月3日:通过半精度推理和md5sum图像检查改进了HF Space演示。
- 2023年3月22日:修复了更新的
transformers包中的张量不匹配问题。 - 2023年3月13日:添加了官方HF Space演示。
入门
实现基于PyTorch 1.13,并高度集成了Huggingface accelerate 工具包,用于可读和优化的多节点多GPU训练。
首先,通过运行以下命令安装所有包依赖:
pip install -r requirements.txt
准备Accelerator配置
然后根据您的训练服务器配置生成相应的accelerate配置。对于单节点多GPU和多节点多GPU训练,只需运行并按照以下说明操作:
accelerate config
数据集
预训练
我们使用五个广泛使用的图像-替代文本/文本数据集的组合来预训练Prismer/PrismerZ,提供了预先组织好的数据列表。
- COCO 2014:Karpathy训练分割(也将用于微调)。
- Visual Genome:官方Visual Genome描述数据集。
- CC3M + SGU:经BLIP-Large过滤和重新描述。
- CC12M:经BLIP-Large过滤和重新描述。
网络数据集(CC3M、SGU、CC12M)由图像URL组成。强烈建议使用img2dataset,这是一个高度优化的大规模网络爬取工具包,用于下载这些图像。下面提供了一个使用img2dataset下载cc12m数据集的示例bash脚本。
img2dataset --url_list filtered_cc12m.json --input_format "json" --url_col "url" --caption_col "caption" --output_folder cc12m --processes_count 16 --thread_count 64 --image_size 256
注意:预计下载的图像数量会少于json文件中的图像数量,因为某些URL可能无效或需要较长的加载时间。
图像描述 / VQA
我们在两个数据集上评估图像描述性能:COCO 2014和NoCaps;以及在VQAv2数据集上评估VQA性能。在VQA任务中,我们还使用Visual Genome QA增强了训练数据,遵循BLIP的做法。同样,我们准备并组织了以下训练和评估数据列表。
生成专家标签
在开始任何Prismer实验之前,我们需要首先预生成模态专家标签,以便构建多标签数据集。在experts文件夹中,我们包含了论文中介绍的所有6个专家。我们已经为每个专家的代码库组织了一个共享的简单API。
注意:特别是对于分割专家,请首先通过cd experts/segmentation/mask2former/modeling/pixel_decoder/ops并运行sh make.sh来安装可变形卷积操作。
要下载预训练的模态专家,请运行:
python download_checkpoints.py --download_experts=True
要生成专家标签,只需编辑configs/experts.yaml中的相应数据路径,然后运行:
export PYTHONPATH=.
accelerate launch experts/generate_{EXPERT_NAME}.py
注意:专家标签生成仅适用于Prismer模型,不适用于PrismerZ模型。
实验
我们提供了Prismer和PrismerZ的预训练检查点(用于零样本图像描述),以及在VQAv2和COCO数据集上微调的检查点。使用这些检查点,应该能够复现下面列出的准确性能。
| 模型 | 预训练 [零样本] | COCO [微调] | VQAv2 [微调] |
|---|---|---|---|
| PrismerZ-BASE | COCO CIDEr [109.6] | COCO CIDEr [133.7] | test-dev [76.58] |
| Prismer-BASE | COCO CIDEr [122.6] | COCO CIDEr [135.1] | test-dev [76.84] |
| PrismerZ-LARGE | COCO CIDEr [124.8] | COCO CIDEr [135.7] | test-dev [77.49] |
| Prismer-LARGE | COCO CIDEr [129.7] | COCO CIDEr [136.5] | test-dev [78.42] |
要下载预训练/微调的检查点,请运行:
# 下载所有模型检查点(共12个模型)
python download_checkpoints.py --download_models=True
# 下载特定检查点(本例中为微调VQA的Prismer-Base)
python download_checkpoints.py --download_models="vqa_prismer_base"
注意:请记得通过sudo apt-get install default-jre安装java,这是运行官方COCO描述评估脚本所必需的。
评估
要评估模型检查点,请运行:
# 零样本图像描述(记得在配置文件中删除描述前缀)
accelerate launch train_caption.py --exp_name {MODEL_NAME} --evaluate
# 微调图像描述
accelerate launch train_caption.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
# 微调VQA
accelerate launch train_vqa.py --exp_name {MODEL_NAME} --from_checkpoint --evaluate
训练 / 微调
要从头开始预训练或微调任何模型,或使用检查点,请运行:
# 从头开始训练/微调
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME}
# 从最新检查点开始训练/微调(每个epoch保存)
accelerate launch train_{TASK}.py --exp_name {MODEL_NAME} --from_checkpoint
我们还在当前训练脚本中通过PyTorch官方的FSDP插件包含了模型分片。使用相同的训练命令,另外添加--shard_grad_op以进行ZeRO-2分片(梯度+优化器状态),或--full_shard以进行ZeRO-3分片(ZeRO-2 + 网络参数)。
注意:VQAv2准确率的误差范围应小于0.1;COCO/NoCAPs CIDEr分数的误差范围应小于1.0。
最小示例
最后,我们提供了一个最小示例,使用我们微调的Prismer/PrismerZ检查点在单个GPU上执行图像描述。只需将您的图像放在helpers/images下(支持.jpg、.jpeg和.png图像),然后运行:
python demo.py --exp_name {MODEL_NAME}
然后您可以在helpers/labels文件夹中看到所有生成的模态专家标签,在helpers/images文件夹中看到生成的描述。
特别是对于Prismer模型,我们还提供了一个简单的脚本来美化生成的专家标签。要美化并可视化专家标签及其预测的描述,请运行:
python demo_vis.py
注意:记得在configs/caption.yaml的demo部分设置相应的配置。默认的demo模型配置是Prismer-Base。
引用
如果您发现这段代码/工作对您自己的研究有用,请考虑引用以下内容:
@article{liu2024prismer,
title={Prismer: A Vision-Language Model with Multi-Task Experts},
author={Liu, Shikun and Fan, Linxi and Johns, Edward and Yu, Zhiding and Xiao, Chaowei and Anandkumar, Anima},
journal={Transactions on Machine Learning Research},
year={2024}
}
许可
版权所有 © 2023,NVIDIA Corporation。保留所有权利。
本作品根据Nvidia Source Code License-NC提供。
模型检查点在CC-BY-NC-SA-4.0下共享。如果您重新混合、转换或构建基于该材料的作品,您必须以与原始许可相同的许可分发您的贡献。
对于商业咨询,请访问我们的网站并提交表格:NVIDIA Research Licensing。
致谢
我们要感谢所有开源其工作的研究人员,使这个项目成为可能。感谢@bjoernpl贡献了自动检查点下载脚本。
联系方式
如果您有任何问题,请联系sk.lorenmt@gmail.com。











